먼저 저는 게임 전적 사이트를 아는 사람과 함께 개발 및 운영을 하고있었습니다.
백엔드는 Nestjs와 Prisma, DB는 PostgresSQL로 개발하였습니다.
배포는 AWS의 ECS를 통해 배포를 하고, RDS를 이용해 데이터베이스를 연결하였습니다.
먼저 트래픽이 없을 시기인 새벽 2시경 갑자기 백엔드 CloudWatch 경보와 Uptime 알림이 엄청나게 요동치기 시작하였습니다. 이런시간에 서버가 죽는건 처음이라 가장 먼저 ECS 백엔드 로그를 확인해보았습니다.
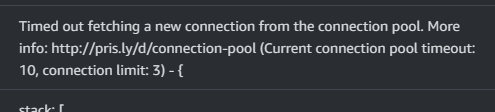
갑자기 Prisma에서 Connections Pool이 고갈이 나서 Timeout되어 서비스가 더이상 동작을 하지않는 것이였습니다.
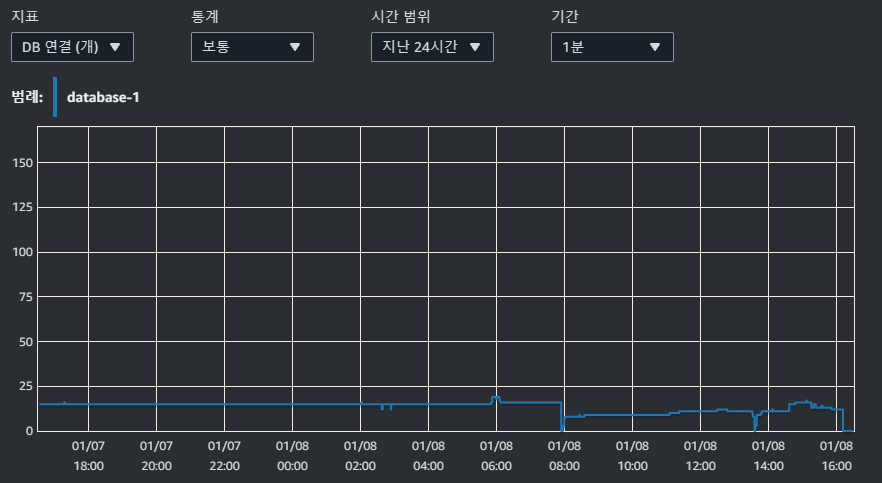
이후 RDS의 문제로 판단하여 RDS CloudWatch 지표를 보니
Connection 수는 매우 정상적이였습니다.
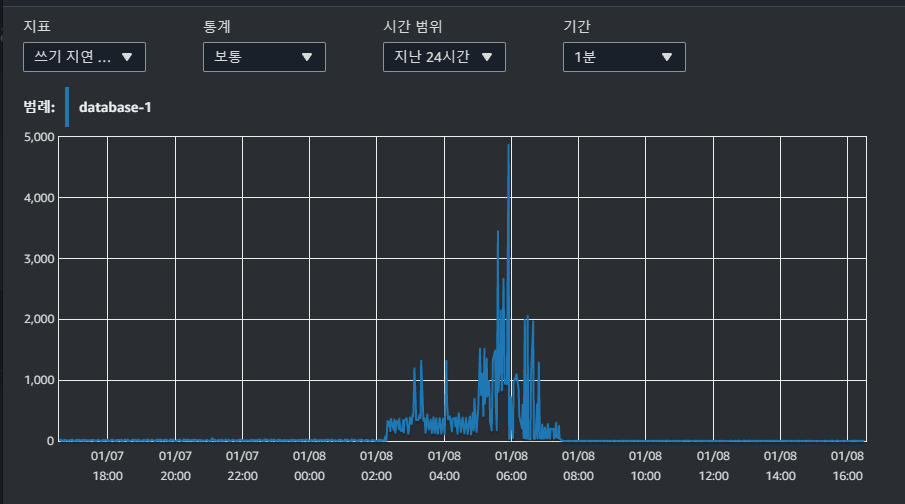
하지만 스토리지 지연시간은 갑자기 5000ms까지 불어나는 상황이었습니다.

또한 데이터베이스 로드를 보니 대부분이 IO에 시간을 쓰고 있습니다.
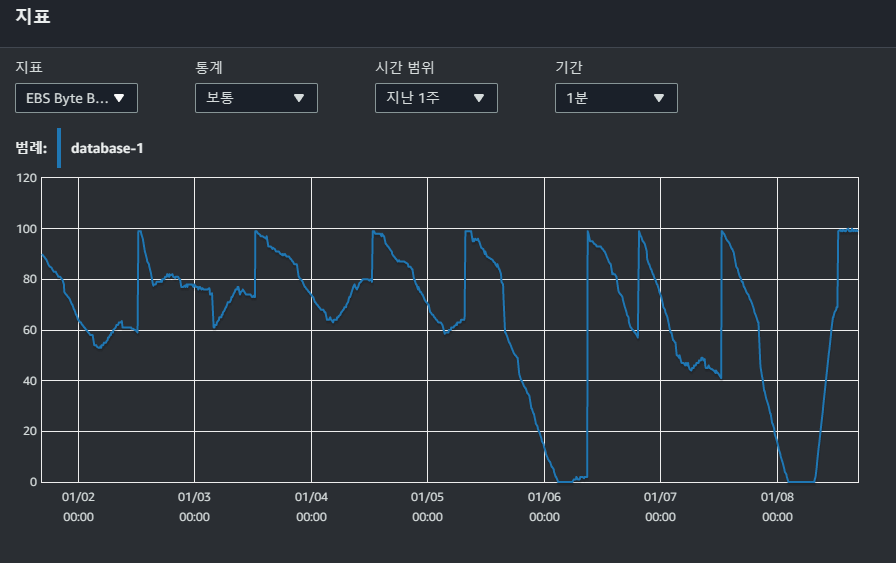
자세히 지표를 보던중 특이한 지표를 하나 발견하게 됐습니다.
EBS Byte Balance와 EBS IO Balance가 0을 치고있던 것이였습니다.
해당 지표를 빠르게 검색하니 AWS 문서에서 병목현상으로 알려주었습니다.
하지만 저희는 gp2의 버스트 성능을 사용하지 않고, gp3의 스토리지 용량과 성능이 독립적으로 동작하는 스토리지를 사용하는데 뭔가 이상하다 느꼈습니다.
다른 AWS 문서를 참고하니 인스턴스 자체에 사용할 수 있는 IO가 제한되어있고, 24시간 중 30분만 버스트로 IO를 사용할 수 있는 것이였습니다.
그리고 왜 새벽 2시에 갑자기 DB가 뻗었는지 알아보았고, 실시간으로 제공하기엔 너무 큰 데이터들을 하루 3번씩 Batch를 통해 캐싱하는 큰 작업, 자잘한 Batch들이 너무 자주 실행되는 것이 문제였습니다. 또한 저희 쿼리는 WAS에서 충분히 처리할 수 있는 부분도 SQL쿼리로 DB에 너무 많은 부담을 주는 상황이였습니다. 일단 황급히 Batch 작업의 cron의 횟수를 하루 1회로 줄이고, 추후 DB에서 처리하는 부분을 WAS로 진행할 계획을 수립하였습니다.
하지만 이미 고갈된 버스트 성능 때문에 기본적인 쿼리도 더이상 제대로 진행이 불가능해진 상황입니다.
이에 황급히 대안을 생각하였고
- RDS 재시작
- Prisma Timeout 늘리기
- 지금 RDS의 인스턴스를 업그레이드
- Aurora로 업그레이드
정도로 생각이 났습니다. 저희는 어짜피 RDS의 성능을 거의 쥐어짜듯이 사용하고 있었고 첫번째와 두번째는 임시방편에 불가능하니, 이참에 Aurora로 업그레이드를 진행하기로 결정하였습니다.
새벽이니 먼저 프론트에서 더이상 API를 부르지 못하도록 긴급 점검 공지와 503 리다이렉트를 설정하였습니다.
그리고 RDS에서 pg_dump --file <Dump name.dump> -v --format=c를 통해 DB 덤프를 뜨고, 새로운 Aurora DB에 pg_restore을 통해 복원을 진행하였습니다. 이후 백엔드와 Batch 스케줄러에서 사용하는 엔드포인트를 교체하니, 급하게 DB 문제는 해결되었습니다.
하지만 아직까지 문제점이 너무 많아 진행중인 백엔드 리팩토링에 더욱 박차를 가하고, DB말고 WAS에서 리소스를 전담하도록 수정하도록 해야겠습니다.
