[글또 9기] 네 번째 글
지난 글에 이어서 '중복 허용의 조회수'를 구하기 위한 로그 수집 설정 과정을 간단하게 적어보도록 한다!
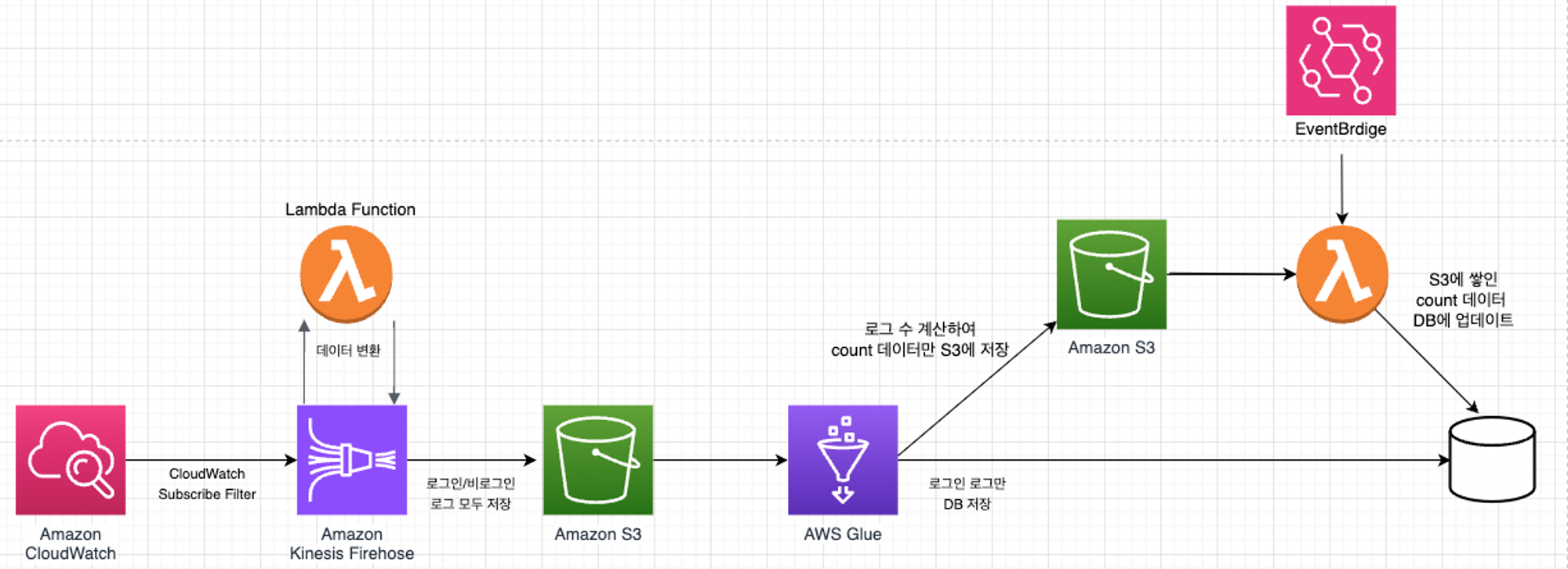
우선 지난 포스팅에서 조사하고 고민한 결과, 위와 같은 구조로 구현하기로 결심했다!
로그를 저장하기 위해 CloudWatch부터 KinesisFirehose를 통해 S3까지 세팅 과정은
다른 블로그에서도 충분히 찾아볼 수 있기 때문에 생략하겠다.
중복 허용의 조회수를 위해 추가된 사항이 있는 부분에 대해서만 적어보도록 한다!
1. CloudWatch 구독 필터 설정
우선 CloudWatch 구독 필터와 관련해서 반드시 알아둘 점은
CloudWatch는 로그 그룹당 최대 2개의 구독 필터를 지원한다는 것!
2개 이상 설정할 수 없기 때문에 구독 필터를 적절히 잘 설정해야 한다.
나의 경우엔 ‘로그인 + 비로그인’ 모두 포함하여 ‘중복 허용’의 조회수 집계 기능을 구현하는 것이었기 때문에 로그인 유입 시 찍히는 로그와 비로그인 유입 시 찍히는 로그를 수집해야 했다.
따라서 로그인 + 비로그인을 OR 조건으로 한, Kinesis Firehose 구독 필터를 설정해주었다.
복합 표현식을 사용하여 JSON 객체에서 일치하는 용어 검색
터 패턴에서 논리 연산자 AND('&&') 및 OR('||')을 사용하여 둘 이상의 조건이 참인 로그 이벤트와 일치하는 복합 표현식을 생성할 수 있습니다. 복합 표현식은 괄호('()') 사용과 () > && > || 표준 연산 순서를 지원합니다.
지표 필터, 구독 필터, 필터 로그 이벤트 및 Live Tail에 대한 필터 패턴 구문 - Amazon CloudWatch Logs
// 예시
{ $.user.email = "John.Stiles@example.com" || $.coordinates[0][1] = "nonmatch" && $.actions[2] = "nonmatch" }2. Glue job 및 Workflow 생성
1번까지 하면 로그인/비로그인에 대한 로그가 S3에 저장된다.
그렇다면 이제 Glue에서 해야하는 것들은 다음과 같다!
(1) S3에 저장된 로그들을 Glue로 가져와서
(2) Glue의 집계 기능을 통해 로그인/비로그인 수를 count하고
(3) 그 count한 결과값을 다시 S3에 저장하기
2-1. Glue Database 생성하기
S3에 저장된 로그들을 가져오기 위해선 'Crawler'를 설정해야 하는데,
그 전에 Crawler의 Target Database가 될 Data Catalog의 Database를 생성해준다!
여기서 AWS Glue Data Catalog란, Glue에서 ETL 작업(추출,변환,로드)를 할 때 원본이 되는 데이터가 참조하는 일종의 테이블 정의라고 볼 수 있겠다!
Glue에서는 Data를 직접 가져오는 것이 아닌, Data의 메타데이터만을 가져와서 데이터 카탈로그에 저장합니다.
<메타데이터와 데이터 카탈로그는 무엇일까요?>
메타데이터란, 데이터의 특성을 나타낸 것으로 크롤링된 데이터의 크기, 데이터의 형식, 스키마 등등으로 원본 데이터를 표현한 데이터입니다.
데이터 카탈로그는 이러한 메타데이터 들을 모아 한눈에 여러 데이터들을 확인할 수 있도록 해주는 기능입니다. Glue 에서는 “테이블”이라는 이름으로 데이터 카탈로그가 존재하며, 저장된 모든 메타데이터 들을 확인할 수 있으며 스키마 수정 등 간단한 메타데이터에 대한 작업을 할 수 있습니다.
작업을 할 때마다 모든 데이터를 가져오게 된다면 어떻게 될까요? 데이터의 양이 MB수준이면 가능하겠지만, GB, TB수준까지만 올라도 매우 큰 네트워크 트래픽이 발생할 것 입니다. 이를 방지하기 위해, 최후의 데이터 가공까지 원본 데이터를 옮기지 않습니다.(DB의 Lazy Evaluation과 비슷한 맥락입니다.)
Data의 메타데이터를 가져오는 작업은 Glue Crawler를 통해 할 수 있습니다.
출처 : https://tech.cloud.nongshim.co.kr/2021/08/19/hands-on-aws-glue-studio-etl/
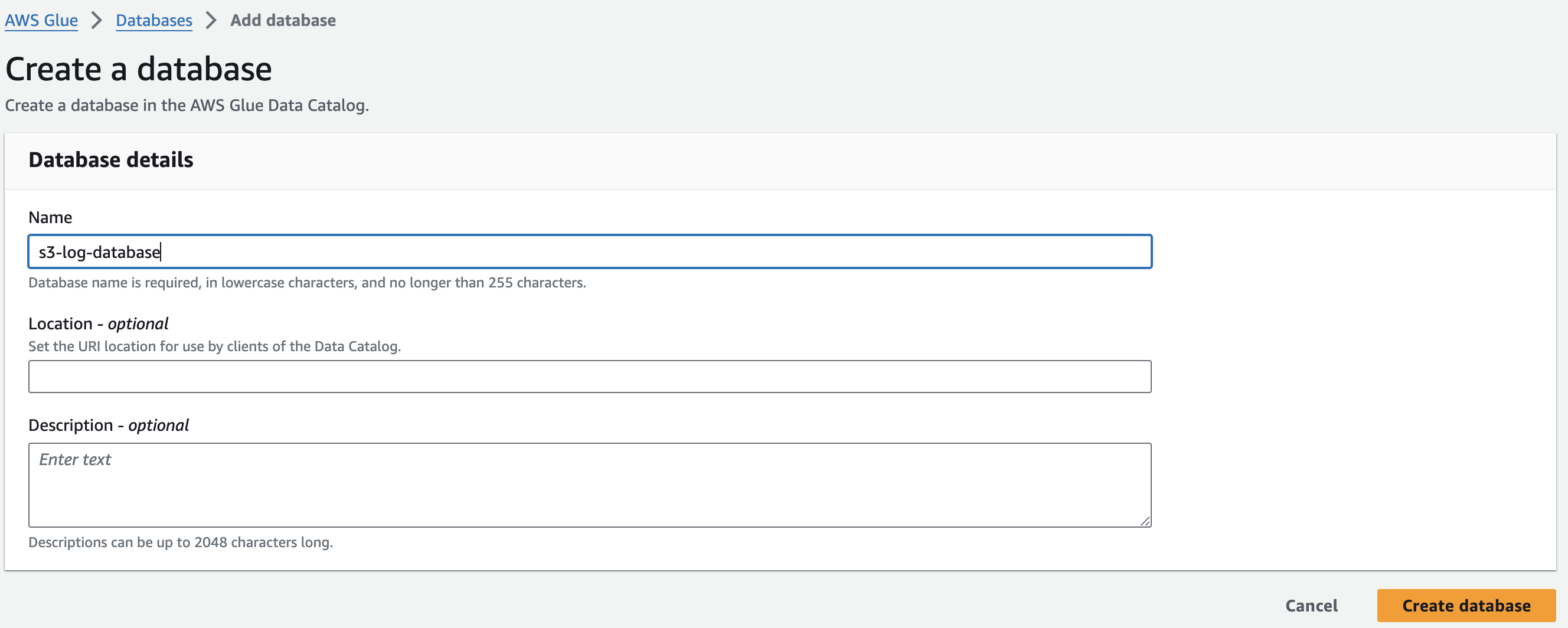

데이터베이스를 만드는 건 간단하다.
위와 같이 간단하게 이름만 정하면 생성이 완료된다.
그 다음 테이블을 만드는데, 직접 테이블을 생성할 수도 있고, 혹은 크롤러를 통해서 테이블을 생성할 수 있다.
크롤러를 실행하면 테이블이 자동 생성된다.
참고 : [AWS Glue] Crawler를 통해 S3에서 Data Catalog로 데이터 추출

나는 크롤러를 이용하여 tables를 생성해보겠다.
Add tables using crawler를 이용해서 크롤러를 만들어보자!
2-2. S3 Crawler 설정하기
참고 : https://www.youtube.com/watch?v=yj98zViIgYI
Crawler는 S3에 저장된 로그들을 가져오는 역할을 한다.
아래와 같이 S3를 data source로 추가해주고,
긁어올 S3 path와 하위 폴더 어디까지를 긁어올 건지(Subsequent crawler runs)를 설정한다.




그리고 GlueRole을 설정해준다. 만약 없다면 하나 생성한다!

Target Database는 아까 생성한 database로 한다.
그리고 크롤러를 돌리는 주기(스케줄러)를 설정할 수 있는데, 나는 workflows에서 따로 설정할 것이기 때문에 onDemand (필요할 때마다) 로 설정했다!
설정 완료한 크롤러는 Run 버튼을 눌러 tables를 생성해준다.
참고로 S3 크롤러 같은 경우엔, 지정한 s3 경로에 데이터가 있어야 tables가 생성된다.
(없으면 s3에 데이터 만든 후 실행해야 정상적으로 생성됨!)
[참고] 크롤러가 AWS Glue Data Catalog을 채우는 과정
1. 크롤러는 선택한 사용자 지정 분류자를 실행하여 데이터의 형식 및 스키마를 추론합니다. 사용자 지정 분류자에 대한 코드를 제공하면 지정한 순서대로 실행됩니다.
첫 번째 사용자 분류자가 데이터 구조를 성공적으로 인식하는 과정은 테이블의 스키마를 생성하는 데 사용됩니다. 하위 목록에 있는 사용자 분류자는 건너뜁니다
2. 어떠한 사용자 지정 분류자도 데이터 스키마와 일치하지 않는다면 기본 설정 분류자는 데이터 스키마를 인식할 시도를 합니다. 기본 설정 분류자의 예는 JSON을 인식하는 분류자입니다.
3. 크롤러를 데이터 스토어로 연결합니다. 어떤 데이터 스토어는 크롤러 액세스 연결 속성을 요구합니다.
4. 추론된 스키마는 데이터 때문에 생성됩니다.
5. 크롤러는 메타데이터를 Data Catalog로 작성합니다. 테이블 정의는 데이터 스토어의 데이터에 대한 메타데이터를 포함합니다. 테이블은 Data Catalog에서 테이블 컨테이너인 데이터베이스에 작성됩니다. 테이블 속성은 테이블 스키마를 추론한 분류자에 의해 생성된 라벨인 분류자를 포함합니다.
출처 : https://docs.aws.amazon.com/ko_kr/glue/latest/dg/catalog-and-crawler.html
2-3. Job 만들기
2-2까지 하면 앞서 언급한 (1),(2),(3) 단계에서
(1) S3에 저장된 로그들을 Glue로 가져오기 위한 세팅이 완료되었다.
이후 s3에서 가져온 로그들을 바탕으로 조회수를 집계하고,
집계한 조회수를 S3에 저장하는 Glue Job을 만들 것이다.
아래의 AWS Glue > Jobs > Visual ETL을 선택하자.


Visual ETL이란 이름답게 위와 같이 쉽게 필요한 작업들을 조합하여 ETL job을 만들 수 있다.
첫 번째, Data Source - S3 bucket
우선 S3를 dataSource로 하여 S3에 저장된 로그들을 가져온다.
(참고로 Data Preview에서 내가 설정한 작업들이 데이터를 어떻게 변환하는지 미리보기가 가능한데, 크롤러가 수행되어서 실제 데이터를 가져와야 확인이 가능하다.)
두 번째, 'Change Schema'
아까 정의한 Table의 Schema에 따라 데이터를 변환한 후,
세 번째, 'Spark SQL' 문을 정의하여 조회수 count

select
year(cast(current_timestamp as TIMESTAMP) - INTERVAL 1 hours) as year,
month(cast(current_timestamp as TIMESTAMP) - INTERVAL 1 hours) as month,
day(cast(current_timestamp as TIMESTAMP) - INTERVAL 1 hours) as day,
hour(cast(current_timestamp as TIMESTAMP) - INTERVAL 1 hours) as hour,
count(*) as login_count
from myDataSource
group by board_id위와 같이 Spark SQL문을 짜서 게시판 ID별로 login_count를 계산하도록 해줬다.
참고로 year, month, day, hour는 S3에 저장할 때 파티셔닝을 해서 저장하기 위해 위와 같이 계산해줬다.
1시간 전 데이터만 긁어와 집계할 것이어서 저렇게 설정해주었다.
네 번째, 파티셔닝 설정하여 S3에 저장


위와 같이 파티셔닝을 설정해주면
해당 파티셔닝 설정별로 폴더가 생성된다.
(예 : {bucket}/year=2024/month=2/day=4/hour=18)
참고 : AWS Glue를 이용한 파티션 데이터 처리 | Amazon Web Services
AWS Tutorials - Partition Data in S3 using AWS Glue Job
Glue - Read Data Catalog and load S3 Bucket - Part2
[Hands On] Glue를 이용한 데이터 전처리
[Aws + Spring] Spring Boot + Aws Glue + S3를 활용한 방문자 통계 구축 (2)
2-4. Workflow 만들기
지금까지 만든 크롤러, ETL jobs를 workflows를 설정하여 수행하는 걸 자동화해보자!

적당한 Workflow 이름을 설정한 후,
Add trigger를 통해서 트리거를 추가해보자.

가장 먼저 크롤러를 통해 데이터를 긁어와야 하므로, 크롤러 trigger를 만들었다.
트리거 타입을 설정할 수 있는데, 나는 매시마다 수행하도록 할 것이므로 Schedule를 설정했다.
수동으로 설정할 때는 On demand를 하면 되고, 혹은 EventBrdige를 따로 설정하여 트리거를 연동할 수 있다.

위와 같은 식으로
크롤러 트리거 -> 크롤러 -> ANY 트리거 (job 트리거) -> job 설정
해서 워크플로우를 만들면 설정한 시간마다 workflow가 이 플로우대로 수행한다!
워크플로우가 수행된 후, 아까 설정한 log-count-job의 타겟 S3에
카운트 처리가 된 조회수 로그가 S3에 쌓여있는지 확인해보면 된다.
여기까지 하면 앞서 말한 (1),(2),(3) 단계에서
(1) S3에 저장된 로그들을 Glue로 가져와서
(2) Glue의 집계 기능을 통해 로그인/비로그인 수를 count하고
(3) 그 count한 결과값을 다시 S3에 저장하기
(3)단계까지 왔다!
3. S3 → Lambda (with EventBridgeScheduler)
3-1. Lambda 만들기
이제 Lambda를 이용하여 S3에 쌓인 조회수 로그를 읽어오고,
조회수 저장 API로 전송하여 해당 데이터를 저장해보자!
그렇다면 위 로직을 수행할 Lambda의 스크립트를 짜야한다.
그래서 아래의 참고 자료들을 통해 람다를 만들고 파이썬으로 스크립트를 만들었다.
- 참고 자료
Read File Data from S3 using Python AWS LambdaRead JSON file from S3 With AWS Lambda in python with Amazon EventBridge Rule
https://www.youtube.com/watch?v=sFvYUE8M7zY
스크립트 중 핵심 코드 부분을 설명하자면 다음과 같다.
import boto3
import json
def lambda_handler(event, context):
# s3 Client 생성
s3_client = boto3.client('s3')
# 파티셔닝한 폴더 아래의 s3 File key들 가져오기
file_list = []
for s3_key in s3_keys:
s3_objects = s3_client.list_objects_v2(Bucket=s3_bucket, Prefix=s3_key)
for content in s3_objects.get('Contents', []):
file_key = content['Key']
file_size = content.get('Size', 0)
if file_size > 0:
file_list.append(file_key)
# 각 파일을 읽어와서 JSON으로 파싱
for file_key in file_list:
response = s3_client.get_object(Bucket=s3_bucket, Key=file_key)
file_content = response['Body'].read().decode('utf-8')
json_data = json.loads(file_content)
S3에서 파티셔닝한 폴더 아래에 있는 조회수 count 로그들(json 형태)의 key를 먼저 가져온 후, 해당 key를 바탕으로 s3 Object를 가져와 json으로 파싱한다.
그리고 파싱한 데이터들을 미리 만들어둔 조회수 저장 API의 Request 형태에 맞게
가공한 후 쏴주기!
- (참고) 만약 람다에서 환경변수를 사용하고 싶다면 구성 > 환경 변수 > 편집 을 이용하여 설정해주면 된다.

환경 변수를 가져오는 파이썬 코드는 다음과 같다.
import os
def lambda_handler(event, context):
s3_bucket = os.getenv("s3_bucket")참고 :
Lambda 환경 변수 사용 - AWS Lambda
[ DevOps ] - (AWS Lambda) 환경변수 설정

이렇게 람다 생성 및 스크립트 설정 완료!
3-2. EventBridgeScheduler 설정
'Amazon EventBridgeScheduler > 일정 생성' 으로 가서
Cron 을 이용하여 람다가 실행될 반복 일정을 세팅해준다.


대상은 람다이므로 람다를 선택한 후, 아까 생성한 람다 함수를 선택해준다!

아래로 내려보면 아래와 같이 페이로드를 주는 곳이 있다.
필요에 따라 해당 스케줄러에서 람다로 전송할 페이로드를 설정할 수 있다.
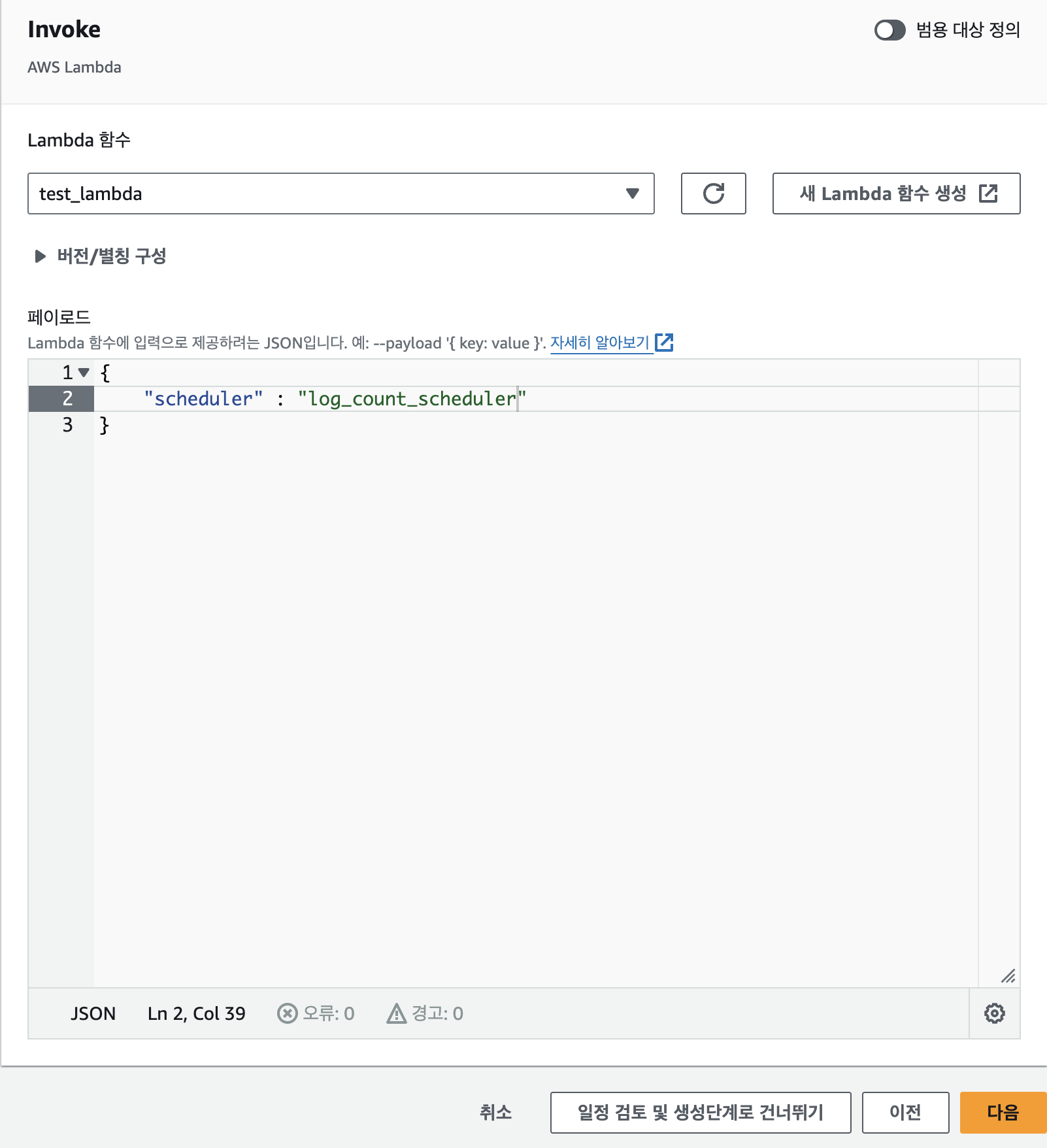
이 페이로드는 람다의 코드 소스에서 가장 상위에 있는 함수가 고정적으로 받는 인자 event를 통해 가져올 수 있다.
해당 event 인자 내부에 딕셔너리 형태로 데이터가 저장되어있다.

이후 일정 완료 후 작업과 재시도 정책, 이벤트 브릿지 ROLE(없으면 생성!)을
필요에 따라 설정해주면 끝!
참고로 앞서 Glue에서 설정한 Workflow가 먼저 제대로 수행이 완료되어
S3에 조회수 계산 로그가 저장이 되어있어야
그 다음에 EventBrdigeScheduler의 스케줄링에 따라 람다가 제대로 수행된다.
즉, workflow가 수행되어 s3에 저장되기 까지의 시간이 얼마나 걸리는지 측정한 후,
이후 EventBrdigeScheduler가 수행 스케줄링 시간을 적절하게 설정하자.
처음엔 좀 헤매긴 했지만, 하고 나니 생각보다 쉽고 간단하다.
이것이 AWS의 힘인가...
여튼 재미있었다!
