
[글또 9기] 세 번째 글
0. 들어가며
최근 특정 기능에 대한 ‘조회수’ 집계를 구현할 일이 있었다.
문제는 ‘로그인 + 비로그인’ 모두 포함하여 ‘중복 허용’의 조회수 집계가 필요하다는 것이었다.
중복 허용이 아니라면 DB insert를 고려했겠지만, 중복 허용이기 때문에 냅다 DB Insert를 하기엔 너무 위험하다고 생각했다.
그리고 해당 기능에서 ‘로그인 유저’에 대한 로그는 이미 아래와 같은 구조로 수집되고 있는 상황이었다.

Cloudwatch - Kinesis Firehose - S3 - Glue - RDS
CloudWatch의 구독 필터를 통해 해당 기능의 로그를 수집하고,
Kinesis Firehose를 통해 데이터 변환 및 S3에 저장한다.
특정 주기마다 S3에 쌓여있는 로그를 Glue를 통해 가져와서 데이터 처리를 하고 RDS로 보낸다.
이 구조에서 최소한의 변경으로 ‘로그인+비로그인의 중복 허용 조회수’를 집계를 구현해야만 하는 셈…!
그리하여 그 과정에서 겪었던 시행착오와 최종결과까지 쭉 정리하고자 한다.
1. 설계하기
1-1. 로그 분석하기
자, CloudWatch에서 로그 분석부터 해보자…
우선 조회수를 집계하려는 특정 기능은 사용자가 유입되는 순간 로그에 특정 식별자가 붙는다.
(예를 들면 [CLICK] 이런 식)
그렇기 때문에 CloudWatch LogInsight에서 얼마나 많은 로그가 찍히고 있는지 확인했다.
stats count(*) as logCount by bin(1d)
|filter @message like '[CLICK]'(참고 자료)
Boolean, comparison, numeric, datetime, and other functions - Amazon CloudWatch Logs
자습서: 로그 필드로 그룹화된 시각화를 생성하는 쿼리 실행 - Amazon CloudWatch Logs
그렇게 약 두달간의 로그 수를 확인하고, 일자별 평균을 내본 결과
해당 기능과 관련된 로그는 약 7만건이었고, 로그인일 경우엔 2만건, 비로그인일 경우엔 5만건이었다.
기존엔 로그인 관련 로그만 저장하고 있었지만, 비로그인(+중복 허용)까지 포함해서 로그를 저장하면 2-3배 더 많은 로그를 저장해야했다.
또한 로그인의 경우엔 매일 1~3만건 사이를 왔다갔다 했지만, 비로그인은 특정 경우엔 10만건을 돌파하기도 했다.
하지만 오로지 조회수 집계를 위해 매일 5만건 이상씩을 더 저장하는 건 비효율적이라고 생각했다.
다른 용도로도 활용되면 모를까 count만 할 용도였기 때문에...
그래서 저장을 최소화하는 방향으로 가고 싶었다.
또 하나 고려할 점은, Kinesis Firehose의 s3 전송 내역을 보면
유저가 주로 활동하는 시간대에는 로그 전송량이 특히 더 증가했다.
그래서 내가 설계하면서 고려한 부분은 아래와 같이 두 가지였다.
- 비로그인 로그의 저장을 최소화할 것 (count 용도 외엔 쓰지 않기 때문에)
- 유저가 몰리는 시간대에 급증하는 로그를 안전하게 집계할 것
1-2. 시행착오
1. SQS - Lambda 이용하기 (실패)
우선 SQS와 같은 Queue를 따로 둬서 로그를 집계하고자 했다.
저장을 최소화하면서 로그 수가 갑자기 몰려도 DB 부하를 방지할 수 있을 것이라 생각했다.
또한 찾아본 결과, request가 몰렸을 때 병목 현상으로 인한 데이터 유실을 방지할 수 있다고 한다.
RDS의 쓰기 속도와 Lambda에서 RDS로 전달하는 속도 차이로 인해 병목 현상이 발생하면, 데이터의 일부만 저장될 수 있는데, SQS를 쓰면 일시적으로 모아뒀다가 나중에 consumer에게 전달하는 방식이기 때문에 이런 문제를 예방할 수 있다고 한다.
이와 관련해서는 아래의 블로그를 읽어보면 좋을 것 같다.
AWS Lambda를 이용한 병목현상 경험하기
AWS SQS로 병목현상 해결하기
- 그럼 KinesisFirehose에서 SQS로 전송하도록 해볼까?

- 우선 s3에 저장하지 않고 SQS에 담아뒀다가 Lambda를 통해서 로그인+비로그인 총 조회수를 집계하고 주기적으로 DB에 update하는 것을 생각했다. 하지만!! 이건 문제가 있었다.
- KinesisFirehose는 데이터를 추출해서 특정 목적지로 ‘전송’하는 것이 특징이다.
그러나 그 전송 가능한 목적지 중에서 SQS나 Lambda는 지원하지 않는다. - MongoDB나 S3와 같이.. 저장이 가능한 목적지만 지원하는 듯 했다.
- 그럼 CloudWatch 구독 필터를 따로 추가하면 되지 않을까?
- 그러나 CloudWatch 구독 필터는 최대 2개 밖에 지원하지 않는다.
- 나의 경우엔 구독 필터가 2개 모두 걸려있는 상황이었고, 그 중 하나가 이 로그 처리에 쓰이는 Kinesis Firehose 구독 필터였다.즉 CloudWatch 구독 필터를 따로 추가할 수 없던 상황이었다.
- 또한 실제 구독필터 생성을 보면 4가지 종류밖에 없다.
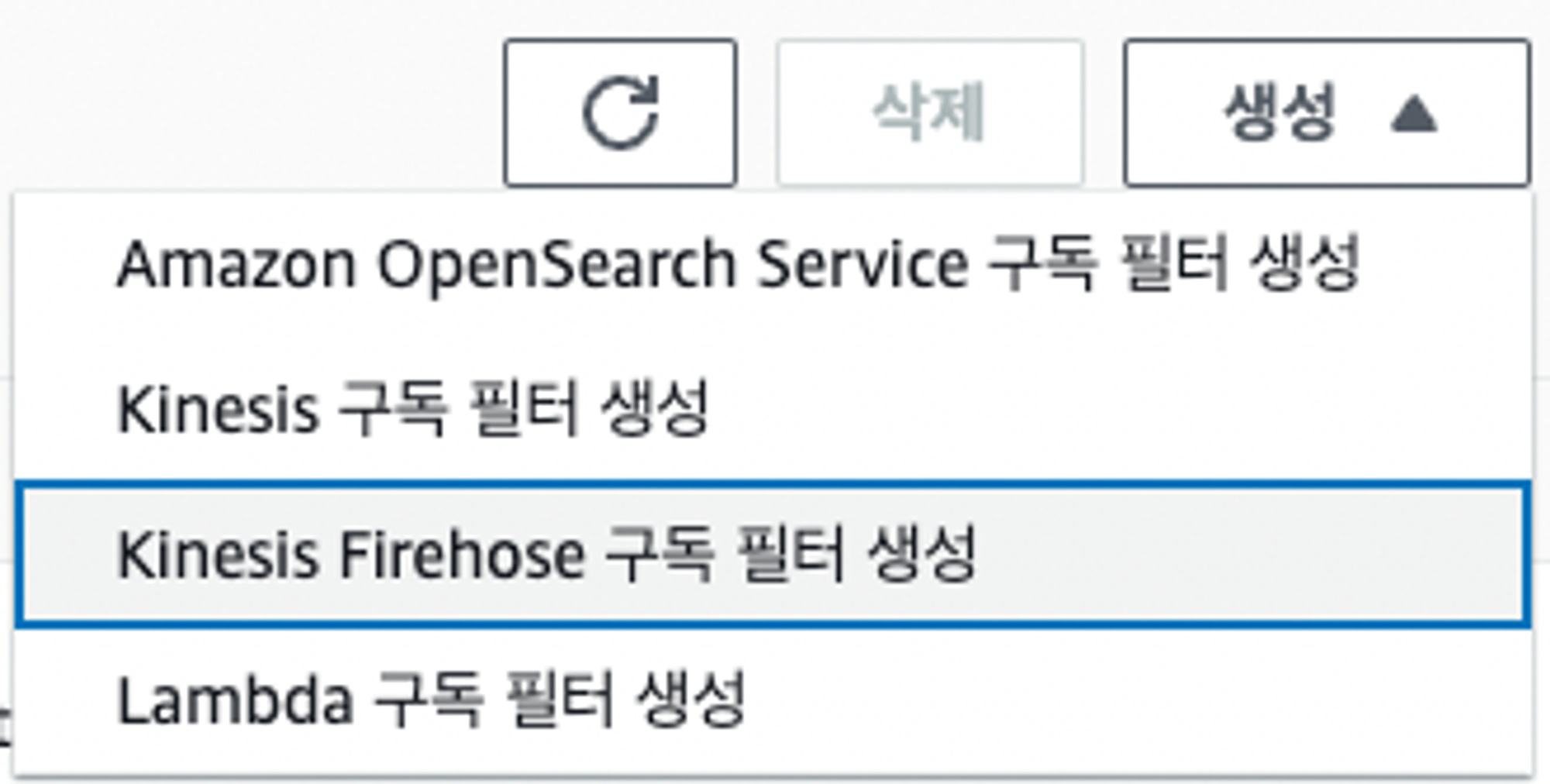
- 찾아보니 구독 필터에서 SQS까지 연결하려면 Lambda를 구독 필터를 생성해서 연결해야 한다고 한다…
Serverless Land
2. Kinesis DataStream 도입 (보류)
-
그렇다면 KinesisFirehose 대신 Kinesis DataStream을 도입해보면 어떨까?
(참고한 글) Kinesis Streams — Using AWS Lambda to Process Kinesis Streams
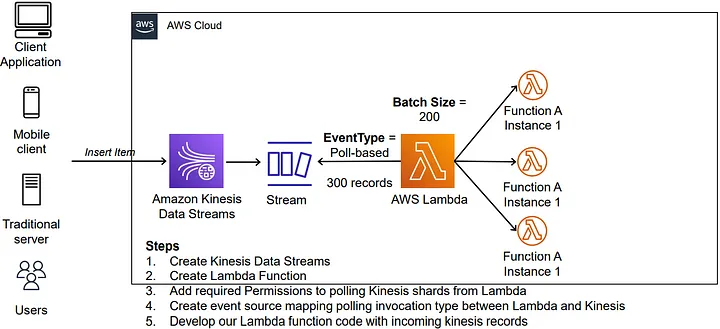
- 우선 Kinesis DataStream/Firehose 이 둘의 차이부터 알아보자…
[참고] Kinesis Data Stream / Kinesis Firehose 차이
- Data Stream 은 low latency streaming service 이고, Firehose 는 data transfer service.
- Data Stream 은 최대 일주일까지 데이터 일시적으로 저장 가능 (Stream 역할 수행), Firehose 는 일시적 저장 불가능 (Transfer 역할만 수행)
- Data Stream 은 Consumer 들이 Stream 에서 데이터를 꺼내와서 작업하는 개념이고, Firehose 는 데이터를 직접 Destination 에 전달(Transfer)하는 개념이다.
- Data Stream은 Consumer 를 여러 개 지정 가능, Firehose는 단일 Destination 을 가짐.
- Data Stream 은 샤드 수를 조정하여 수동으로 Scailing 해야함 반면 Firehose 는 데이터 요청에 따라 Scailing 이 자동으로 이루어짐
[AWS Kinesis] Data Stream vs. Data Firehose
- 즉, Kinesis Firehose는 특정 목적지로 전달하는 게 주된 역할이지만, Kinesis DataStream은 파이프라인이자 메시지 큐와 비슷한 역할을 한다. SQS 대신 이용하기에 괜찮은 선택지 같았다. 따라서…
 (1) CloudWatch에서 ‘Kinesis Firehose 구독 필터’에서 ‘Kinesis Data Stream 구독 필터’로 교체를 하고,
(1) CloudWatch에서 ‘Kinesis Firehose 구독 필터’에서 ‘Kinesis Data Stream 구독 필터’로 교체를 하고,
(2) consumer를 Kinesis Firehose와 Lambda Function 두 개로 지정
(3) 로그인 유저들의 로그는 Firehose를 통해 S3 저장 / 비로그인 유저의 로그는 저장하지 않고 람다를 이용하여 주기적으로 count하여 DB에 저장
- 우선 Kinesis DataStream/Firehose 이 둘의 차이부터 알아보자…
-
그러나 고려할 점…
- DataStream은 샤드 수를 조정하여 수동으로 Scailing 해야 하는 등.. 초반에 여러 시행 착오가 있을 것으로 보였다..
- 또한 앞의 방법들은 기존의 구조를 건드리지 않고 추가적으로 붙이는 방식의 설계였다면, 이건 기존의 구조를 어쨌든 좀 변경해야 한다는 점…
- 물론 consumer를 여러 개 둘 수 있다는 점에서 추후 확장성을 염두하면 이 방법이 가장 좋아보였지만...(흑흑)
- 사실 이러쿵저러쿵 하지만 Kinesis DataStream이란 기술을 잘 모르는 채로 함부로 도입하는 게 좀 마음에 걸렸다...ㅎㅠ 조회수 집계 기능 하나 때문에 기존에 잘 작동하던 로그 수집 및 집계들도 시행착오를 겪으며 모두 케어해야한다는 점이 다소 부담이었다. 그래서 보류...! ㅠㅠ
1-3. 결정
S3에 로그인+비로그인 로그 모두 쌓기 / Glue에서 데이터 처리하여 Lambda로 전송하기
- 마음은 Kinesis DataStream을 쓰고 싶었지만... 이 이상 확장될 때 고려해볼 법한 방안이라고 생각되어 결국 어느 정도 타협하기로 했다.
- 그리하여.. 다음과 같은 방안을 고안하게 되었다.

-
정리
- (전) S3에 로그인 로그만 쌓기 → (후) 로그인+비로그인 로그 모두 쌓기
- (전) Glue에서 데이터 처리하여 로그인 로그 RDS로 전송하기 → (후) Glue job에서 분기 처리하여 로그인 로그는 그대로 RDS 저장 / 로그인과 비로그인 로그 각각 집계하여 count만 내고 S3에 저장
- (추가) S3에 쌓은 count 데이터 Lambda와 EventBridge Scheduler를 이용하여 주기적으로 RDS 에 저장
-
고려할 점
- 결국 s3에 로그인+비로그인 로그를 모두 쌓는다는 점이 아쉽긴 하지만
기존의 방식에서 변경되는 점이 가장 적고, Kinesis DataStream 도입보다는 쉽다는 점. - 로그의 용량이 굉장히 작기 때문에 모두 저장해도 큰 차이가 없을 것이란 점을 고려
- 그리고 이 쌓이는 로그들은 주기적으로 s3에서 지워주기로 했다.
⇒ 그리하여…
기존의 구조에서 Glue 에서 분기 처리 / Lambda + EventBridge Scheduler 를 추가하기로 결정!
일단 이 방식으로 하다가 나중에 Kinesis DataStream을 도입해보면 어떨까 싶다... - 결국 s3에 로그인+비로그인 로그를 모두 쌓는다는 점이 아쉽긴 하지만
포스팅이 생각보다 길어지는 것 같아서 이쯤에서 나눠가는 걸로 하겠다!
다음 글은 이를 세팅하는 과정에 대해서 적어보겠다!
(혹시 지나가다 다른 방법이나 피드백이 있는 분이 있다면..
댓글로 남겨주시면 감사하겠습니다!)
다음 포스팅에서 계속..
