Spring WebFlux + Coroutine 환경 비동기 개발에서 살아남기 💪 - Reactor 활용과 Coroutine 등장 배경
Spring Webflux + Coroutine
Reactive Programming
우리는 주로 절차를 명시해서 순서대로 실행되는 Imperative Programming(명령형 프로그래밍)을 해왔다.
이와 다르게 Reactive Programming이란 데이터의 흐름을 먼저 정의하고 데이터가 변경되었을 때 연관된 작업이 실행된다
즉 프로그래머가 어떠한 기능을 직접 정해서 실행하는 것이 아니라 시스템에 이벤트가 발생했을 때 알아서 처리되는 것이다
Reactor
지난 포스트에서 다루기도 했지만 Spring webflux에서 사용하는 reactive library가 Reactive Streams의 구현체인 Reactor이다
이 Reactor의 주요 객체가 Mono와 Flux, 둘 다 Publisher 인터페이스를 구현한 구현체
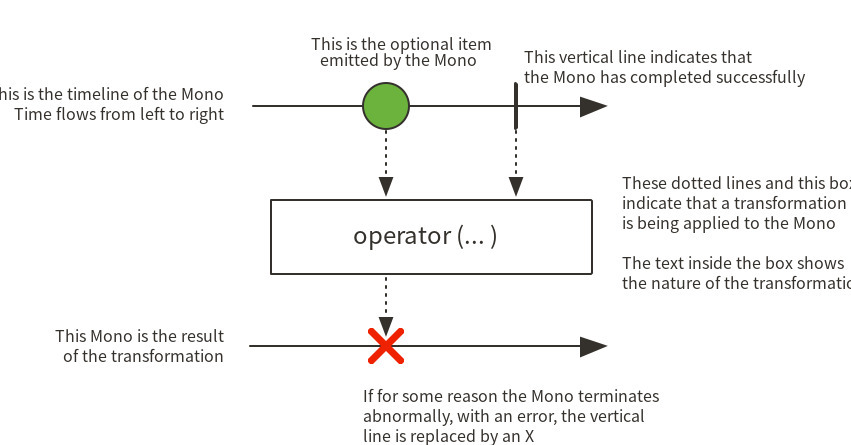
Mono
Mono 는 0~1개의 데이터를 처리한다
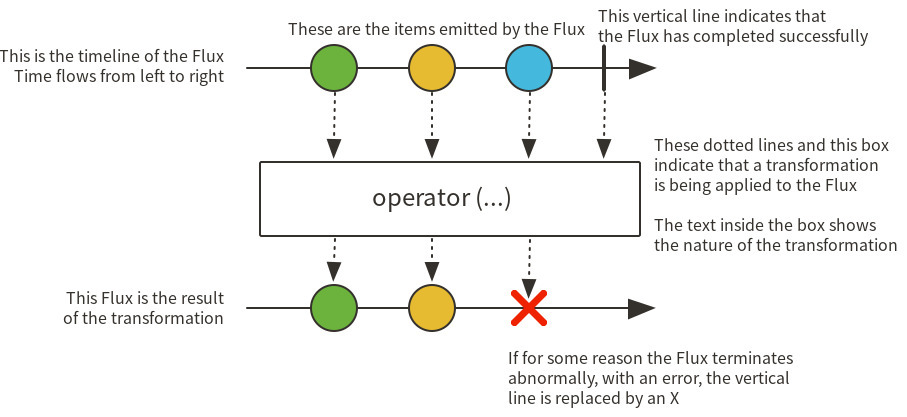
Flux
0~N개의 데이터를 처리한다
따라서 데이터가 하나 전달될 때마다 내부적으로 onNext 이벤트를 실행한다
Flux내의 모든 데이터 처리가 완료되면 onComplete 이벤트가 발생하며 데이터를 전달하는 과정에서 오류가 나면 onError 이벤트가 발생한다
활용
publisher 생성
Flux<String> flux1 = Flux.just("foo", "bar", "foobar");
Flux<String> flux2 = Flux.fromIterable(Arrays.asList("foo", "bar", "foobar"));
Flux<Integer> flux3 = Flux.range(5, 3); // 5, 6, 7
Mono<Object> mono1 = Mono.empty(); // empty여도 타입을 가진다
Mono<String> mono2 = Mono.just("foo");위와 같이 다양하게 생성 가능하고 Flux와 Mono가 publisher 구현체이므로 내부에 데이터를 넣어주면 된다
subscriber를 subscribe
- subscribe
publisher가 subscriber를 subscribe 함
void subscribeExamples() {
Flux<Integer> flux2 = Flux.range(1, 3);
flux2.subscribe(i -> System.out.println(i));
Flux<Integer> flux3 = Flux.range(1, 4)
.map(i -> {
if(i <= 3){
return i;
}
throw new RuntimeException("Got to 4");
});
flux3.subscribe(
i -> System.out.println(i),
error -> System.out.println("Error: " + error));
Flux<Integer> flux4 = Flux.range(1, 4);
flux4.subscribe(
i -> System.out.println(i),
error -> System.out.println("Error: " + error), // onError : 에러로 흐름 종료
() -> System.out.println("Done")); // onComplete : 성공적으로 흐름 종료 == Runabble이다 (Supplier)
Flux<Integer> flux5 = Flux.range(1, 15);
flux5.subscribe(
i -> System.out.println(i),
error -> System.out.println("Error: " + error), // onError : 에러로 흐름 종료
() -> System.out.println("Done"), // onComplete : 성공적으로 흐름 종료 == Runabble이다 (Supplier)
subscription -> subscription.request(10)); // subscription에게 10개의 데이터를 요청한다
}결과
// 2번
1
2
3
// 3번
1
2
3
Error: java.lang.RuntimeException: Got to 4
// 4번
1
2
3
4
Done
// 5번
1
2
3
4
5
6
7
8
9
10Reactor 활용 예시 코드
상품을 주문하는 코드를 작성한다고 할 때
유저 아이디와 상품 아이디를 받아서
유저 정보 조회, 유저의 주소 조회, 상품 조회, 상품을 판매하는 상점을 모두 조회한 뒤
주문데이터를 저장하는 코드를 비동기적으로 작성하려면 아래와 같이 작성해야 한다
Mono<Order> orderProduct(String userId, String productId) {
return Mono.create { emitter ->
userRepository.findUserById(userId)
.subscribe { buyer ->
addressRepository.findAddressByUser(buyer)
.subscribe { address ->
checkValidRegion(address)
productRepository.findAllProductsByIds(productId)
.collectList()
.subscribe(products ->
storeRepository.findStoresByProducts(products)
.collect().asList()
.subscribe().with { store ->
orderRepository.createOrder(buyer,address,products, store).whenComplete{
order -> emitter.success(order)}
....
}
}Coroutine의 필요성
위의 코드를 보면서 가독성이 매우 떨어진다고 느낀다면 지극히 정상이다
위의 코드처럼 하나의 IO 작업의 결과를 받아서 그 결과로 IO 또 다른 IO작업을 연쇄적으로 실행하는 코드를 비동기적으로 프로그래밍하려면
위와 같이 끝없이 subscribe의 굴레를 만들어줘야 한다,, ㅎㅎ
이러한 코드의 엄청난 가독성,,ㅎㅎ 을 시원하게 개선해주는 것이 coroutine의 역할이다!
일단 맛보기지만 위의 코드를 코루틴으로 작성하면 아래와 같이 깔끔하게 정리된다
suspend fun orderProduct(userId: String, productId: String): Order {
val buyer = userRepository.findUserById(userId).awaitSingle()
val address = addressRepository.findAddressByUser(buyer).awaitLast()
val products = productRepository.findAllProductsByIds(productIds).asFlow().awaitAll()
val stores = storeRepository.findStoresByProducts(products).asFlow().awaitAll()
val order = orderRepository.createOrder(buyer,address,products,stores).await()
return order
}코루틴은 근본적으로 subscribe 범벅이었던 기존의 rector 코드를 마치 동기 코드처럼 보이게 해서 코드 가독성을 엄청나게 높여준다는 장점이 있다!
그런데 이렇게 보면 정말로 코드가 동기적으로 처리되는 것처럼 보인다,, awiat라는 말이 특히,, 그래서 IO작업이 끝날때까지 기다리겠다는 의미 아닌가?
코루틴이 어떻게 비동기로 동작하는지는 다음 포스트에서 더 자세하게 다뤄볼 예정이다 👏
참고한 링크
https://bgpark.tistory.com/162
https://www.youtube.com/watch?v=eJF60hcz3EU&t=1410s
