Spring WebFlux + Coroutine 환경 비동기 개발에서 살아남기 💪 - Coroutine과 suspend 함수
Spring Webflux + Coroutine
Coroutine이란
"협력적 멀티태스킹" 이 코루틴의 핵심이라는 소리를 많이 들었지만 여전히 감이 오지 않는다
CoRoutine은 말그대로 Co + Routine으로 같이 하나의 루틴을 처리한다고 이해하면 된다
여기서 루틴을 하나의 함수를 실행하는 과정으로 생각하면 편하다.
보통 우리가 익숙한 동기 코드는 하나의 스레드가 return을 만날 때까지 하나의 함수를 처리한다
그런데 코루틴은 하나의 함수를 실행하기 위해 여러개의 스레드들이 들락날락? 거리면서 조금씩 조금씩 일을 처리하게 된다
좀 더 구체적으로 말하면 suspend 키워드가 붙은 함수를 만나게되면 해당 함수의 일이 처리가 될 때까지 스레드는 다른 누군가에게 suspend 함수의 작업을 위임하고 진행중인 루틴을 빠져나가 다른 일을 한다.
그리고 suspend 함수의 작업이 끝났다는 콜백을 받으면 해당 스레드, 혹은 멀티쓰레드 환경에서는 다른 여유있는 스레드가 다시 해당 루틴에 들어와서 다음 일을 처리하는 식이다.
이렇게 되면 여러 함수들이 동시에 처리될 수 있으므로 코루틴은 동시성을 지원한다고 할 수 있다
코루틴을 흔히 경량쓰레드라고 많이 부른다.
그렇게 부르는 이유는 보통 소량의 스레드로 위와 같이 동시성 프로그래밍을 지원하기 때문이다.
만약 하나의 루틴을 처리하는 과정에서 매 suspend와 콜백 처리를 다른 쓰레드가 하게 된다면 CPU가 쓰레드를 매번 변경해주어야 하므로 context Switching의 비용이 든다
그러나 코루틴은 하나 혹은 소량의 스레드가 단순히 함수를 왔다갔다 하는 것이라 해당 비용을 줄일 수 있디.
Kotlin Compiler와 suspend 함수
위의 설명을 듣고 나면 알겠는데,, 대체 suspend가 어떤 마법인지가 궁금해진다
대단한 기술은 아니고 사실 suspend는 kotlin Compiler가 비동기 코드를 최대한 동기처럼 눈속임해서 보여주는 키워드라고 생각하면 된다.
그래도 내부동작을 파해처보면 아래와 같다.
- Kotlin compiler가
suspend가 붙은 함수를 만나면,, - 해당 함수에 추가 코드를 덧붙여 Finite State Machine (aka. FSM) 형태로 Continuation을 주입
FSM 기반 재귀함수
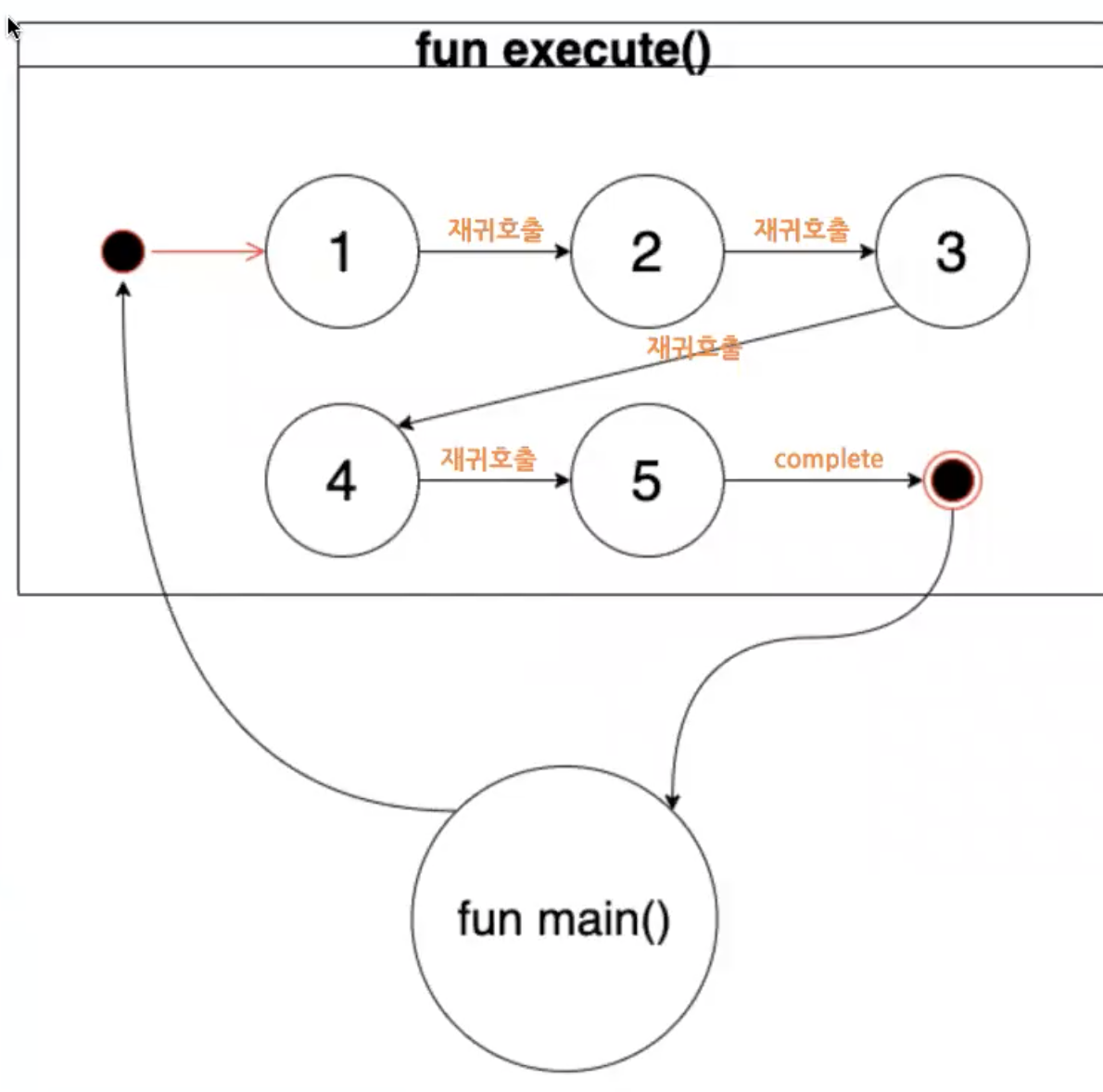
FSM 기반 재귀함수는
1. execute 함수가 실행되면 재귀 호출을 이용해서 스스로(execute 함수)를 실행하면서 state를 변경
2. state가 최종에 도달하면 값을 caller에 반환
과정으로 동작한다
이걸 코루틴에 어떻게 적용했는가?
Continuation 인자를 타겟 함수에 추가하고 Continuation 구현체를 생성
타겟 함수 내의 모든 suspend 함수에 생성한 continuation 객체를 전달
* 코드를 분리해서 switch case 안에 넣고 label을 이용해서 state를 변경
코루틴에서의 suspend 함수는 위와 같은 FSM 형태로 compile 된다
Continuation & SharedData
- SharedData는 Continuation을 implement한 구현체
- Continuation은 resumeWith() 함수와 coroutineContext를 갖고 있음
- resumeWith()는 재귀함수 실행을 위한 도구
- coroutineContext는 여러 스레드가 일을 처리하는데 필요한 정보들을 모아둔 것
CoroutineContext
하나의 코루틴을 실행시키기 위한 정보들: Threadlocal을 사용할 수 없기 때문에 같은 루틴을 실행할 스레드들끼리의 정보 공유 매개
- Job
따라서 하나의 루틴을 여러 스레드가(혹은 하나의 스레드가) 협업해서 실행하게 하기 위해
CoroutineContext 안에 작업과 관련된 데이터를 담고 해당 루틴을 재귀 호출 시켜줄 resumeWith를 담은 SharedData를 매 재귀호출마다 담아서 전달해준다.
상세 예시
이전 포스트에서 잠깐 스포했던 요 코드는 kotlin compiler에 의해 어떻게 바뀌게 될까
suspend fun orderProduct(userId: String, productId: String): Order {
val buyer = userRepository.findUserById(userId).awaitSingle()
val address = addressRepository.findAddressByUser(buyer).awaitLast()
val products = productRepository.findAllProductsByIds(productIds).asFlow().awaitAll()
val stores = storeRepository.findStoresByProducts(products).asFlow().awaitAll()
val order = orderRepository.createOrder(buyer,address,products,stores).await()
return order
}- SharedData 생성
class SharedDataConnection(
val completion: Continuation<Any>
) : Continuation<Any> {
val label: Int = 0
lateinit var result: Any
lateinit var buyer: User
lateinit var address: Address
lateinit var products: List<Product>
lateinit var stores: List<Store>
lateinit var order: Order
lateinit var resume: () -> Unit
override val context: CoroutineContext = completion.context
override fun resumewith(result: Result<Any>){
this.result = result
this.resume()
}
}- suspend 함수 단위로 switch case 쪼개진 execute 함수
fun execute(userId: String, productId: String, completion: Continuation<Any>){
val that = this
val cont = completion as? SharedDataContinuation
?: SharedDataContinuation(completion).apply{
resume = fun() {
// 재귀호출
that.execute(userId, productId, this)
}
when (cont.label) {
0 -> {
cont.label = 1 // 순차적으로 진행하기 위한 라벨
userRepository.findUserById(userId)
.subscribe{ user ->
cont.resumeWith(Result.sucess(user))
}
}
1-> {
cont.label = 2
cont.buyer = (cont.result as Result<User>).getOrThrow()
addressRepository.findAddressByUser(cont.buyer)
.subscribe( LastItemSubscriber { address ->
cont.resumeWith(Result.success(address))
})
}
...(생략)subscribe는 IO작업이 끝났을 때 실행된다고 생각하면 되는데
따라서 쓰레드는 execute라는 하나의 루틴 안에서 처음부터 끝까지 전부 IO작업을 기다리며 처리하는 것이 아니라,
처음 findUserById를 만나면 IO 작업을 요청함과 동시에 해당 루틴에서 빠져나간다
이후 IO작업이 마치면 subscribe 안의 재귀가 실행되며 이때 해당 작업을 담당하는 스레드가 다시 와서 resumeWith로 재귀함수를 호출한다
이후 label이 1이 되어 주소를 찾는 case로 들어가 작업을 처리하던 스레드는 findAddressByUser를 만나게 되고 또 다시 IO작업이 진행되는 동안 해당 루틴을 빠져나가고.. 위와 같은 과정이 반복된다.
참고링크
https://wooooooak.github.io/kotlin/2019/08/25/%EC%BD%94%ED%8B%80%EB%A6%B0-%EC%BD%94%EB%A3%A8%ED%8B%B4-%EA%B0%9C%EB%85%90-%EC%9D%B5%ED%9E%88%EA%B8%B0/
https://kotlinworld.com/139?category=973476
https://brunch.co.kr/@myner/50
