
1. 분류와 회귀
- 예측하려는 타깃값이
범주형 데이터면분류문제,수치형 데이터면회귀문제
1-1) 분류
- 주어진 피처에 따라 어떤 대상을 정해진(유한한) 범주(타깃값)에 구분해 넣는 작업
(ex. 개와 고양이 구분, 스팸메일과 일반 메일 구분, 질병 검사 결과가 양성인지 음성인지 등)
→ 타깃값이 두 개 분류는이진분류, 세 개 이상 분류는다중분류
1-2) 회귀
- 자연현상이나 사회 현상에서 변수 사이 관계
(ex. 학습 시간이 시험 성적에 미치는 영향, 수면의 질이 건강에 미치는 영향, 공장의 재고 수준이 회사 이익에 미치는 영향 등)
→ 영향을 미치는 변수를독립변수, 영향을 받는 변수를종속변수
- 회귀 : 독립변수와 종속변수 간 관계를 모델링 하는 방법
→ 독립변수 X, 종속변수 Y(단순 선형 회귀)
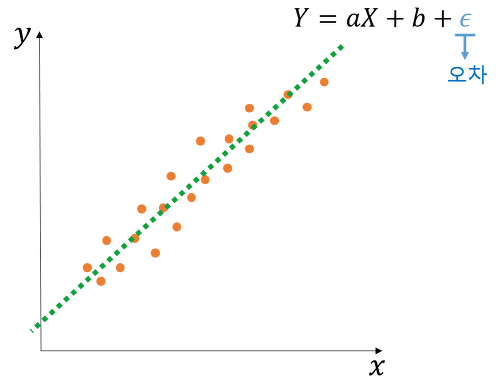
- 독립변수(피처)와 종속변수(타깃값) 사이 관계를 기반으로 회귀 모델을 훈련해
최적의 회귀계수를 찾아야 함
✅ 회귀 평가지표
- 최적의 회귀계수를 구하려면, 예측값과 실젯값의 차이(오차)를 최소화해야 함 ⇒ '데이터에 회귀 모델이 잘 들어맞는다.' 라는 뜻
- 오차가 0이면 회귀 모델이 정확히 일치하지만, 과대적합된 결과임을 의심해봐야 함
- 회귀 평가지표 값은 작을수록 모델 성능이 좋음
⬇️⬇️⬇️⬇️⬇️ 자주 쓰는 회귀 평가지표
- MAE(Mean Absolute Error) 평균 절대 오차
: 실제 타깃값과 예측 타깃값 차의 절댓값 평균
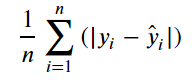
- MSE(Mean Squared Error) 평균 제곱 오차
: 실제 타깃밗과 예측 타깃값 차의 제곱의 평균
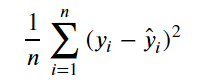
- RMSE(Root Mean Squared Error) 평균 제곱근 오차
: MSE에 제곱근을 취한 값
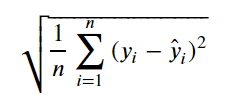
-
MSLE(Mean Squrared Log Error)
: MSE에서 타깃값에 로그를 취한 값 -
RMSLE(Root Mean Squrared Log Error)
: MSLE에 제곱근을 취한 값
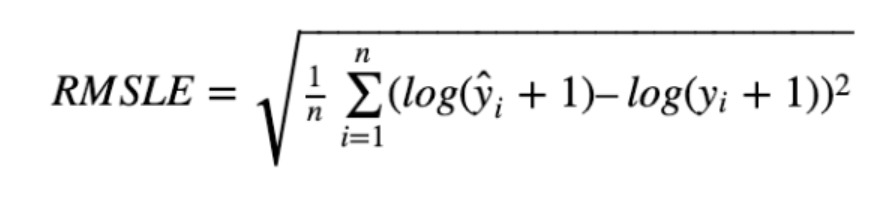
- R² 결정계수
: 예측 타깃값의 분산/실제 타깃값의 분산
** MSLE와 RMSLE에서 log(y)가 아닌 log(y+1)을 사용한 이유는 로그값이 음의 무한대(-∞)가 되는 상황 방지하기 위함
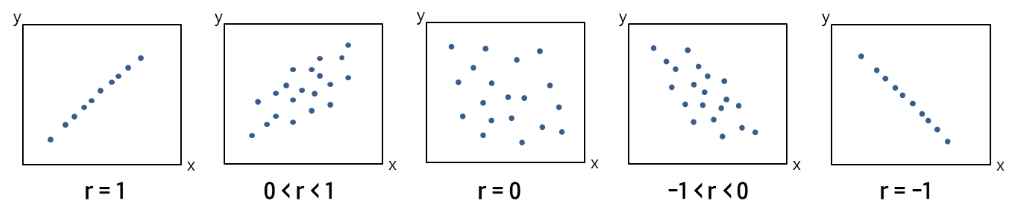
✅ 상관계수
- 피어슨 상관계수
: 선형 상관관계의 강도와 방향을 나타내며, -1~1사이의 값을 가짐
2. 분류 평가지표
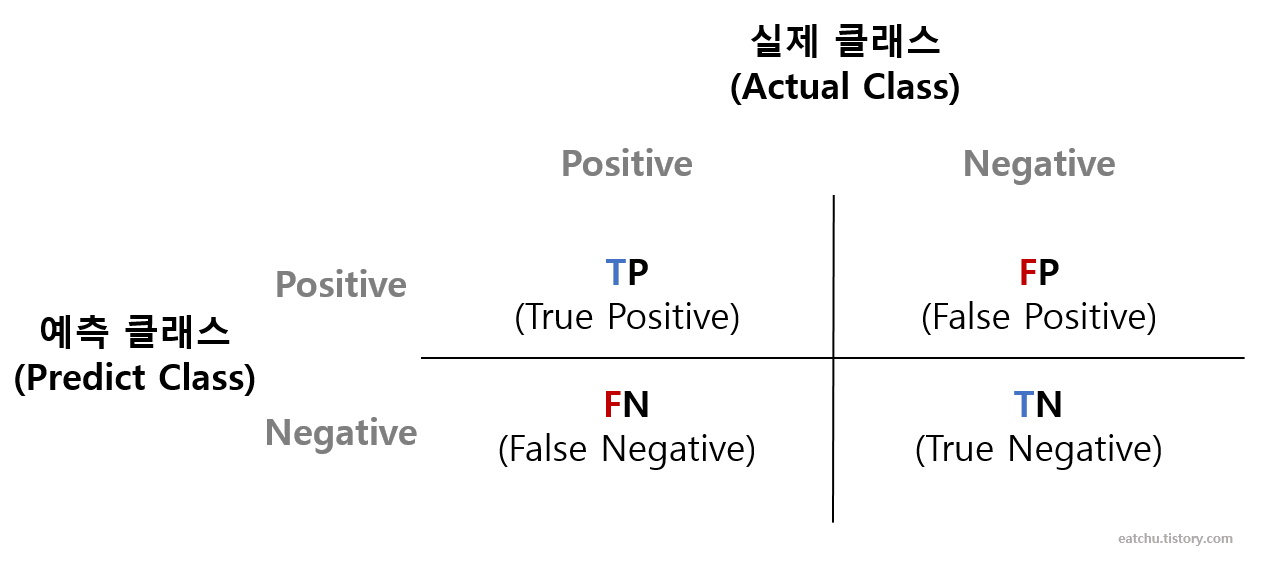
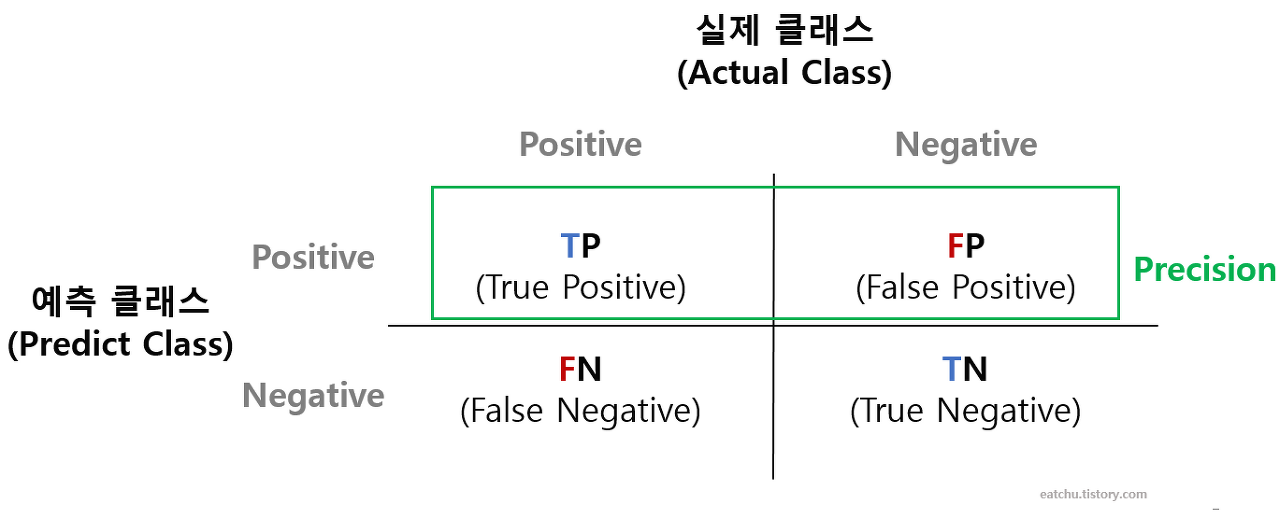
2-1) 오차행렬
- 실제 타깃값과 예측 타깃값이 어떻게 매칭되는지 보여줌
Tip) '참(T)'오로 시작하면 올바로 예측한 것, '거짓(F)'으로 시작하면 틀린 것
- 오차행렬을 활용한 주요 평가지표는 정확도, 정밀도, 재현율, F1 점수가 있으며
모두 값이 클수록좋은 지표
✅ 정확도
- 정확도(Accuracy) = (TN + TP) / (TN + FP + FN + TP)
: 불균형한 데이터를 다룰 때 모델의 신뢰도를 떨어뜨릴 수 있음 → 평가지표로 잘 쓰이지 않음
✅ 정밀도
- 정밀도(Precision) = TP / (TP + FP)
: 양성 예측의 정확도, 양성이라고 예측한 값(TP + FP) 중 실제 양성인 값(TP)의 비율
ex) 실제 스팸 메일(양성)을 일반 메일(음성)로 분류하게 되면 사용자가 불편함을 느끼겠지만 일반 메일을 스팸 메일로 분류할 경우 필요한 메일을 받지 못하는 업무상 차질이 생길 수 있음
✅ 재현율
- 재현율(Recall) = TP / (TP + FN)
: 민감도 또는 참 양성 비율(TPR), 실제 양성 값(TP + FN) 중 양성으로 잘 예측한 값(TP)의 비율
ex) 암환자를 음성이 아닌 양성으로 잘못 판단했을 경우 오류의 대가는 재검사를 하는 수준의 비용이지만 양성인 환자를 음성으로 잘못 판단했을 경우 오류의 대가는 생명임
✅ F1 점수
- F1 점수
: 정밀도와 재현율을 조합한 평가지표
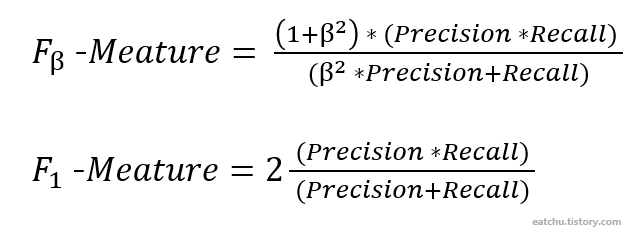
2-2) 로그 손실
- 분류 문제에 타깃값을 확률로 예측할 때 사용하는 평가지표 → 값이 작을수록 좋은 지표

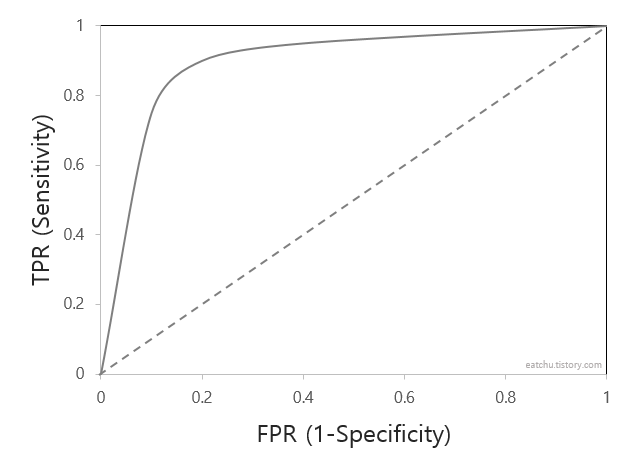
2-3) ROC 곡선과 AUC
- ROC(Receiver Operating Characteristic)
: 참 양성비율(TPR)에 대한 거짓 양성비율(FPR) 곡선
- TPR = TP / (TP + FN) : 실제 Positive 중에 모델이 Positive로 잘 예측한 비율
- FPR = FP / (TN + FP) = 1 - (TN / (TN + FP))
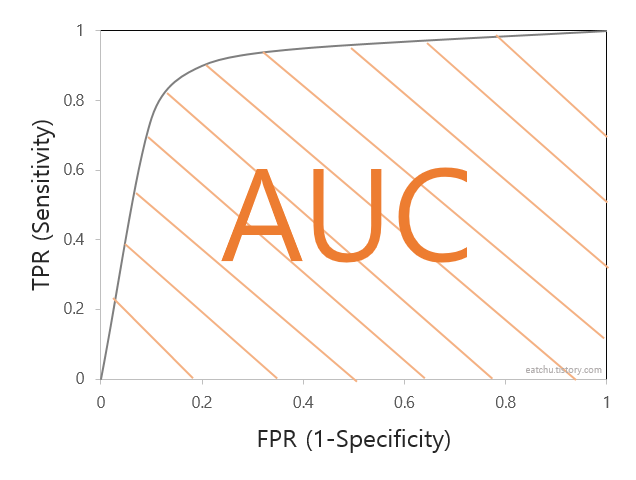
- AUC(Area Under Curve)
: ROC곡선 아래 면적
Tip) 타깃값(이산값)으로 예측 시 분류 평가지표 → 정확도, 정밀도, 재현율, F1 점수
타깃 확률로 예측 시 분류 평가지표 → 로그 손실, AUC
3. 주요 머신러닝 모델
3-1) 선형 회귀 모델
- 선형 회귀식을 활용하여 회귀계수(모델 파라미터)를 찾는 것
✅ 데이터 생성
✅ 모델훈련
✅ 회귀선 확인
3-2) 로지스틱 회귀 모델
- 션형 회구 ㅣ방식 응용해 분류 모델에 적용
- 시그모이드 함수 활용하여 타깃값에 포함될 확률 예측
: 0-1사이 값을 가짐, x값이 작을수록 0에 가깝고 클수록 1에 가까움
3-3) 결정 트리
- 작동원리
1) 데이터를 가장 잘 구분하는 조건 정함
2) 조건을 기준으로 데이터를 두 범주로 나눔
3) 나뉜 각 범주의 데이터를 잘 구분하는 조건을 재정립
4) 조건에 따라 각 범주에 속한 데이터를 재분할
5) 위와 같은 방식으로 계속 분할하여 최종 결정 값을 구함
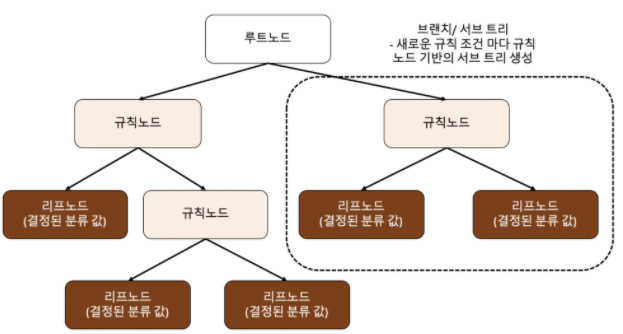
✅ 결정 트리 분할 방식
- 머신러닝에서 결정트리는
불순도를 최소화하는 방향으로 분할
- 불순도 : 한 범주 안에 서로 다른 데이터가 얼마나 섞여 있는지 나타내는 정도
✔️ 불순도 측정 지표
- 엔트로피(entropy)
: 불확실한 정도, 값이 클수록 불순도 높고, 작을수록 불순도 낮음
→ 정보이득(1-엔트로피) ⇒ 정보 이득을 최대화(불순도 최소화)하는 방향으로 노드 분할- 지니 불순도(gini impurity)
: 값이 클수록 불순도 높고 작을수록 불순도 낮음, 불순도 최소화하는 방향으로 노드 분할
✅ 결정 트리 구현
- 사이킷런으로 결정 트리 구현 가능
분류용 모델 - DecisionTreeClassifier
회귀용 모델 - DecisionTreeRegressor
- DecisionTreeClassifier 파라미터 (참고. p143)
- criterion
- max_depth
- min_samples_split
- min_samples_leaf
- max_features
※ 결정트리에 조건이 많을수록 모델이 과대적합될 우려 발생
⇒ max_depth, min_samples_split, min_samples_leaf가 과대적합 제어 파라미터
3-4) 앙상블 학습
- 다양한 모델이 내린 예측 결과를 결합하는 기법
⇒ 예측 성능이 좋아지고, 과대적합 방지 효과 있음
✅ 보팅
- 개별 결과를 종합해 최종 예측 결정하는 방식
- 하드보팅
:다수결 투표방식으로 최종 예측값 결정- 소프트보팅
: 개별 예측 확률들의 평균으로 최종 예측 결정, 대체적으로 소프트 보팅 사용
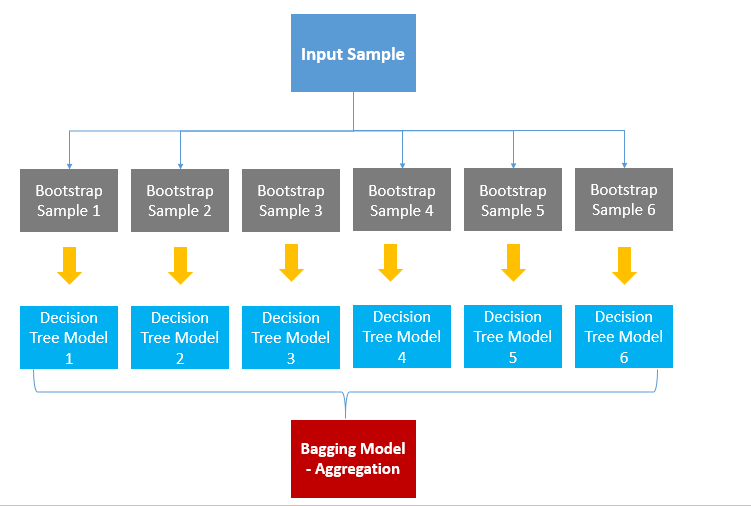
✅ 배깅
- 개별 모델로 예측한 결과를 결합해 최종 예측 결정
→ 특징 : 개별모델이 서로 다른 샘플링 데이터 활용
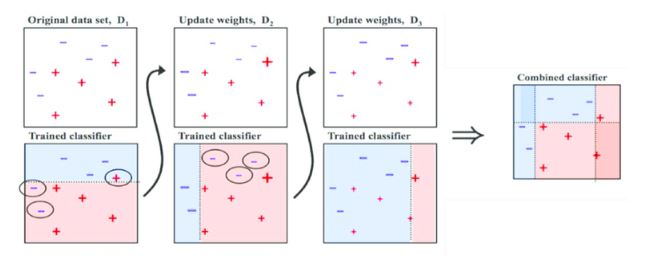
✅ 부스팅
- 가중치를 활용해 분류 성능이 약한 모델을 강하게 만듦
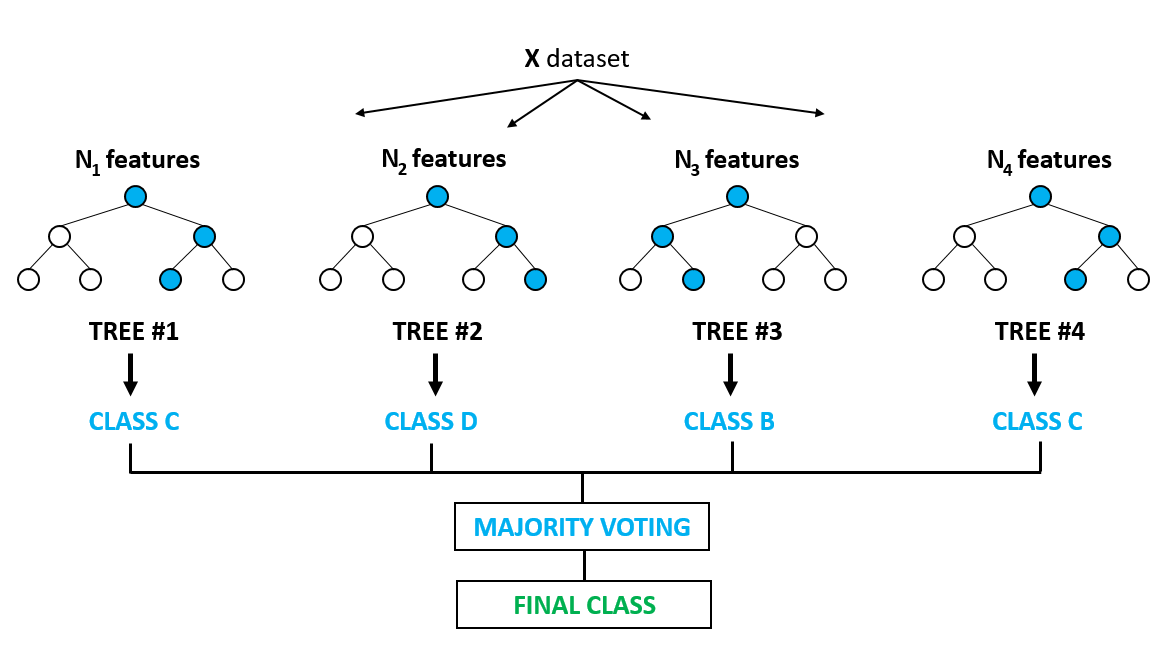
3-5) 랜덤 포레스트
- 결정 트리를 배깅 방식으로 결합한 모델
=
✅ 랜덤 포레스트 구현
- 사이킷런으로 랜덤 포레스트 구현 가능
분류용 모델 - RandomForestClassifier
회귀용 모델 - RandomForestRegressor
- RandomForestClassifier 파라미터 (참고. p151)
- n_estimators
- criterion
- max_depth
- min_samples_split
- min_samples_leaf
- max_features
3-6) XGBoost
- 성능이 우수한 트리기반 부스팅 알고리즘,
결정 트리를 직렬 배치
파이썬 래퍼 XGBoost와 사이킷런 XGBoost 둘 다 사용 가능 (해당 교재에서는 파이썬 래퍼 XGBoost 기준으로 설명)
- xgboost.DMatrix() 파라미터 (참고. p153)
- data
- label
- 하이퍼파라미터 (참고. p153-p155)
- booster
- objective
- eta(learning_rate)
- max_depth
등
- xgboost.train() 파라미터 (참고. p155-p156)
- params
- dtrain
- num_boost_round
등
3-7) LightGBM
- XGBoost와 성능은 비슷하지만
훈련 속도가 더 빠름
파이썬 래퍼 LightGBM와 사이킷런 LightGBM 둘 다 사용 가능
(해당 교재에서는 파이썬 래퍼 LightGBM 기준으로 설명)
- LightGBM.Dataset() 파라미터 (참고. p158)
- LightGBM 모델의 하이퍼파라미터 (참고. p158-p160)
- LightGBM.train() 파라미터 (참고. p160-161)
4. 하이퍼파라미터 최적화
- 사용자가 직접 설정해야하는 값
4-1) 그리드서치
- 주어진 하이퍼파라미터를 모든 경우의 수를 탐색
단점 : 시간이 오래 걸림
→ 가장 기본적인 최적화 기법
4-2) 랜덤서치
- 하이퍼파라미터를 무작위로 탐색
→ 그리드서치나 베이지안 최적화보다 사용 빈도 적음
4-3) 베이지안 최적화
- 사전 정보를 바탕으로 최적 하이퍼파라미터 값 확률적으로 추정
장점 : 빠르고 효율적, 직관적인 코드
- 수행절차
- 1) 하이퍼파라미터 탐색 범위 설정
2) 평가지표 계산 함수(성능 평가 함수) 정의
3) BayesianOptimization 객체 생성
4) 베이지안 최적화 수행
5. 참고

공부하는 데이터 분석가 👩💻