본 내용은 Spring I/O 2022에서 톰 홈버그(Tom Hombergs)가 발표한 내용을 정리한 글입니다.
Overview
글을 읽으시는 분들은 모놀리스(monolith)기반의 프로젝트에서 개발을 한 경험이 있거나 지금도 개발을 하고 있을 겁니다. 서비스의 규모가 커지면서 우리가 구축했던 계층형 아키텍처는 계층의 경계가 혼잡해지고 특정 계층이 비대해져 문제를 많이 느꼈을 겁니다. 하지만 그렇다고 애매한 규모의 서비스가 마이크로서비스로 전환하기에는 비용을 감당하기 쉽지않습니다.
최근 그 고민을 해결하고 싶어 제가 읽었던 책은 ‘클린 아키텍처(clean architecture)’와 ‘만들면서 배우는 클린 아키텍처’였습니다. 책을 읽으면서 공감도 많이하고 무언가 해소가 되는 기분이었습니다.
그런데! ‘클린 아키텍처’에서 말하는 내용을 바탕으로 ‘만들면서 배우는 클린 아키텍처’의 예제인 헥사고날 아키텍처(hexagonal architecture)로 개발을 하려고 하니 막막해졌습니다. 간단한 서비스조차 헥사고날 아키텍처를 도입하려면 공수가 상당하였습니다. 또한 이러한 개념을 회사에 도입하자니 팀원분들과 함께 이해도를 높이기 위한 학습이 필요했고 실제 구현을 해보지 않았던 내용이라 쉽사리 선택하기도 어려웠습니다.
그러던 도중 ‘만들면서 배우는 클린 아키텍처’의 저자 톰 홈버그(Tom Hombergs)가 최근 Spring I/O 2022 세션에서 발표를 했다는 소식을 들었습니다. 참고로 이 개발자는 2019년 동일한 컨퍼런스에서 발표한 내용을 토대로 책을 썼습니다.
톰 홈버그의 이날 발표 내용은 이전 발표와 이어지는 내용이었습니다. 모놀리스와 마이크로서비스에 딜레마, 계층형 아키텍처의 문제점, 헥사고날 아키텍처가 도입이 어려운 이유 그리고 이것을 해결할 Component-based architecture에 대한 소개입니다. 이 내용을 정리(번역에 가깝지만 번역이라기에는 형편없는)한 내용을 글로 작성했습니다.
Let's build components, not layers by Tom Hombergs @ Spring I/O 2022
톰 홈버그는 계층(layer)이 아닌 구성요소(components)에 대한 이야기를 준비했습니다. 어떻게 component-based architecture 구축하는지에 대한 방법입니다.
Software is under-engineered and Software is over-engineered
under-engineering and over-engineering
우리가 만드는 소프트웨어는 과소 엔지니어링이 되어있기도 하고 과도한 엔지니어링이 되어있습니다. 아마 대부분의 엔지니어가 각 프로젝트에서 커다란 진흙 덩어리(big ball of mud, 엉망진창) 같이 under-engineering된 프로젝트에서 일을 했을 것 입니다. 반대로 너무 복잡하게 설계된 프로젝트는 많은 규칙을 가지고 있어 수정을 어떻게 해야할지 모르게 만듭니다.
그런데 같은 소프트웨어가 동시에 under-engineering 되고 over-engineering 되기도 합니다. 이는 우리가 다른 측면에서 소프트웨어를 바라보면 된다.

종종 소프트웨어는 코드 수준(at the code level)에서는 구조(structure)가 충분하지 않고 충분하지 않게 코드가 구성(organizing)되어있습니다. 이 경우 under-engineering하게 됩니다.
그리고 소프트웨어는 시스템 수준(at the system level)에서 마이크로서비스로 분산된 아키텍처로 구성하는 경우 over-engineering 하게 됩니다.
우리는 보통 모놀리스(monolith)로 프로젝트 빌딩을 합니다. 시간이 지날수록 규모가 너무 커지고 더이상 이해하지 못할 정도로 복잡도가 올라갔을 때까지 우리는 무엇을 해야할까요. 우리는 일반적으로 under-engineered 된 커다란 엉망진창이 된 아키텍처를 가지고 있습니다. 더욱 유지보수가 가능하게 만들기 위해 더욱더 작은 여러개의(multiple) 코드로 잘라내고 마이크로서비스를 구축하고 이런 서비스를 각각 배치하고 분리해서 배포하는 서비스 메시를 도입하고 그 주변의 모든 것들을 쿠버네티스 클러스터링하곤 합니다. 우리는 이 과정이 지나치게 over-engineering 하다는 것을 느깁니다.
when we think about underengineered software we often think about monoliths that's the um thing that comes into our mind and if we think about over engineered we often think about microservices but there must be something in between and that in between is um a modular monolith
톰 홈버그의 발표 주제는 그 중간지점(middle ground)을 얘기합니다. 우리는 under-engineering을 말할 때 모놀리스에 대한 이야기를 합니다. 우리가 over-engineering을 이야기할 때는 마이크로서비스를 떠올립니다. 하지만 그 중간지점에 모듈러 모놀리스(modular monolith)가 있습니다.
톰 홈버그는 모듈러 애플리케이션에 대해 앞선 강연을 추천했습니다. (Modular Applications with Spring by Oliver Drotbohm and Michael Plöd @ Spring I/O 2022)
Modular Applications with Spring by Oliver Drotbohm and Michael Plöd @ Spring I/O 2022
즉, 이날의 강연은 모듈러 모놀리스를 준비하기 위해 코드기반을 어떻게 구성해야하는지입니다. 모듈러 모놀리스는 진흙 덩어리 모습을 한 under-engineering 이 되지 않으며 마이크로 서비스로 쪼개는 over-engineering이 필요하지 않게 충분한 구조를 가질 수 있습니다.
my definition of a monolith here is a deployment units that contains more than one bounded context whatever that is.
모놀리스에 대한 톰 홈버그의 정의는 ‘둘 이상의 바운디드 컨텍스트(bounded context)를 포함하는 배포 단위’입니다.

레이어는 눈에 보이지만 문제가 발생할까봐 건드리기 어렵습니다. 톰 홈버그는 퍼즐 조각처럼 아키텍처를 구축하는 방법을 소개해주려고 합니다. 우리는 ‘작고 구별된 컴포넌트(small distinct components)’로 아키텍처를 구성할 수 있습니다. 컴포넌트는 각각을 유연하게 교환할 수 있습니다.
Why organise code?
Michael Plöd가 말한 것과 같이 코드를 구성(organise)하는 이유는 코드상의 모듈(modules)를 갖고 싶기 때문입니다. 톰 홈버그는 이것들을 컴포넌트라고 부를 뿐입니다.
우리는 코드를 작성하면서 다음과 같은 질문을 많이 합니다.
- Where is this feature in the code?
- How can I replace this part of the code?
- What is this part of the code doing?
- How can I move this feature from this codebase to another?
- What can break if I modify this part of the code?
- Where do I add this new feature to the code?
- Who is using this part of the code?
- How does this code fit into the overall architecture?
코드가 제대로 구성되지 않으면 이러한 질문에 대한 답을 찾기 어렵고 조사를 해야하고 시간과 돈을 써야 합니다.
Goals of Code organisation
- Maintainability
- Easy to keep the codebase in a good shape
- Evolvability
- Easy to add to / remove from / modify the codebase.
- Understandability
- Easy to navigate the codebase. Get onboarded quicker.
- And more…
- What do you want from good code organisation?
유지보수성은 시간이 지남에 따라서 적은 비용을 사용해 코드를 유지하는 것입니다. Evolvability(발전 가능성)는 코드에 추가하거나 제거하는 것에 대해 모놀리식 코드인 하나의 코드 베이스에서 시작하는 것을 뜻합니다. 다중 바운디드 컨텍스트(mutiple bounded contexts)를 포함하는 모놀리스 코드는 한 번에 마이크로 서비스로 분리하고 싶지 않을 것 입니다. 실제로 의미가 있는 시점에 분리 하는 것이 좋습니다. 따라서 적절한 코드 구성이 있으면 우리는 모듈과 모듈을 꺼내어서 넣을 수 있기 때문에 발전 가능성이 높다고 할 수 있습니다. 예를들어 모놀리스에서 끄집어내어 자체적으로 배포된 마이크로 서비스에 넣을 수 있기 때문입니다.
코드는 더 조직이 잘 될 수록 이해하기가 더 쉽습니다. 제대로 테스트를 할 수 있기 때문입니다.
What’s wrong with layers?
대부분의 사람들이 레어이 패턴을 많이 사용합니다. 서로 다른 코드 구성 유형에 대해서 먼저 이야기 하겠습니다. 레이어의 문제가 무엇인지 이 패턴을 보면 누구도 알 수 있습니다.
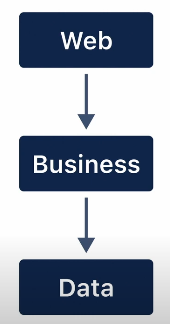
맨 위에 웹 레이어가 요청을 받아 어떤한 타입으로 매핑합니다. 도메인 모델은 비즈니스 계층으로 전달합니다. 비즈니스 계층은 데이터베이스 계층에 대한 일부 비즈니스 처리 호출을 수행합니다. 데이터베이스와 통신하는 데이터 계층은 데이터베이스에 저장을 하죠.
What’s wrong with layers?
Horizontal dependencies everywhere
The only rule is that dependencies may not go to a layer above. This meas that a lot of horizontal dependencies creep in over time.
시간이 지나면서 수평적인 의존성(같은 계층에 대한 의존성)으로 서서히 변경됩니다. 계층화된 아키텍처는 의존성 방향이 아래를 가리키토록 해야 최상위 계층이 하위 계층에 종속될 수 있습니다. 이것이 계층적 구조에서의 유일한 규칙입니다.
The business use cases are hidden
Use cases are often hidden in very broad services within the business layer and are hard to find and reason about.
시간이 지나면서 비즈니스 계층은 매우 넓어지게 됩니다. 따라서 사용자의 Use Case가 계층의 어딘가에 숨겨지게 됩니다. 우리는 Use Case를 찾거나 추론하기 어려워집니다.
Architecture / code gap
A codebase with 3 layers has 3 high-level components to reason about. The actual architecture is more complex and not evident from looking at the code. We have to do mental mapping continuously.
아키텍처를 사용할 때 아키텍처와 코드 사이의 격차가 발생할 수 있습니다. 아키텍처 다이어그램(Web → Business → Data)은 이 부분에 대해 이야기할 수 있는 3가지 컴포넌트가 있음을 의미합니다. 실제 아키텍츠는 코드로 확인할 수 없고 복잡합니다. 우리는 계속해서 계층의 존재를 의식하며 작업을 해야합니다.
A Layer is doing too much
We can’t grasp what a layer is doing because it’s too broad. Our brain can only process a couple of concepts at the same time (my brain, at least).
레이어에는 실제로 우리가 생각했던 것보다 더 많은 작업을 하고 있습니다. 코드에서 무언가를 찾아야 할 때마다 어디 있는지 머릿속으로 매핑을 하고 찾아야 합니다. 따라서 코드에 변화를 줄 때 조심해야합니다.
What’s wrong with vertical slices?
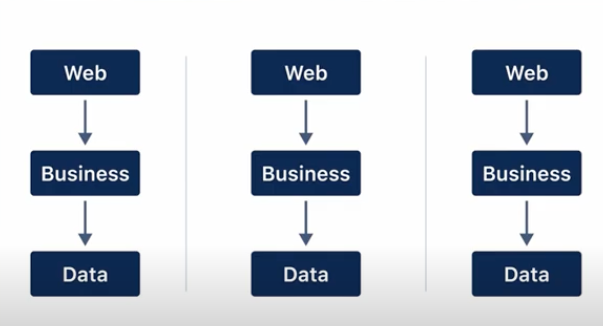
verical slices는 각각 슬라이스마다 경계가 있습니다. 이 단계는 올바르지만 실제로는 더 많은 규칙을 적용하지 않으면 문제가 발생합니다.
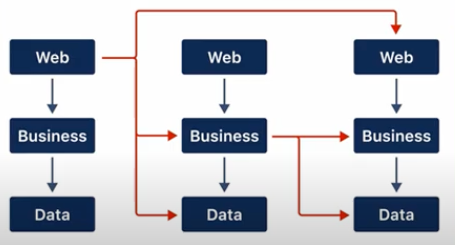
Slices have a large surface area
Slices don’t have a dedicated API, making all dependencies to other slices fair game.
수평 의존성을 강제하지 않은 경우 수직 슬라이스 사이에는 의존성이 없어야 합니다. 수평 종속성이 있는 경우 웹 계층이 비즈니스 계층을 접근하게 될 것입니다.
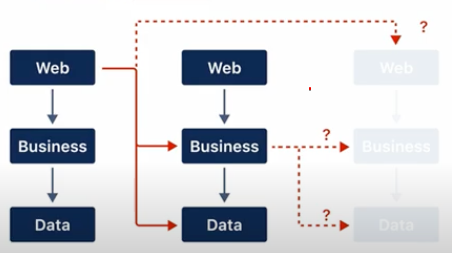
Replacing or removing a slice is risky
Moving a slice out of the codebase is hard due to accidental dependencies.
여기에 적절하게 적용하지 않으면 문제가 발생합니다. 컴포넌트를 다른 부분으로 옮기거나 제거하는 경우 코드나 마이크로서비스 또는 이 컴포넌트에게 의존성이 있는 모든 항목을 수정해야합니다.

시간이 지나면서 나무 울타리(hedge) 같이 됩니다. (계층간에 의존성이 뒤섞여 계층이 보이지 않는 다는 의미로 이해) 우리는 이 모습을 원하지 않습니다.

나무 울타리는 시간이 지나면 이렇게 변하게 됩니다. 우리는 이 안에 있고 새롭게 들어온 초보자는 어디를 봐야할지 조차 알 수 없습니다.
Clean / Hexagonal architecture?
Clean Architecture
로버트마틴이 소개한 클린 아키텍처가 있습니다. 좋은 책이지만 매우 추상적입니다. 클린 아키텍처는 여전이 계층형으로되어있지만 각각의 상단에 위치 한 것이 아니라 원을 둘러싼 레이어입니다.
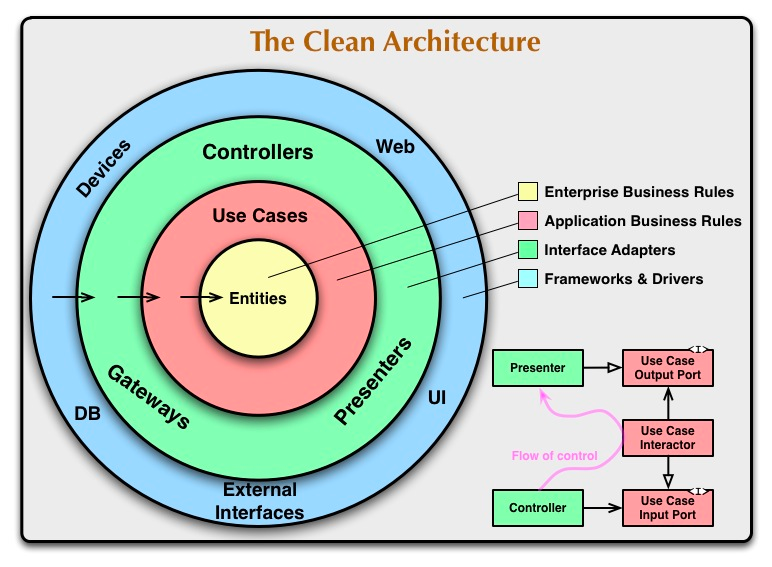
가장 바깥쪽 레이어의 외부에는 ui 컴포넌트, 데이터 베이스가 있을 수 있고 컨트롤러에는 일부 비즈니스 로직을 구현하는 Use Cases가 있고 가운데에는 엔티티라고 불리는 도메인 모델이 있습니다. 도메인 모델은 의존성들로부터 보호됩니다. 도메인 모델은 둘러싸여있고 오직 한 방향의 의존성들이 이 도메인 모델을 가리키며 바깥을 향하지 않습니다.
클린 아키텍처는 도메인 모델을 외부에 대한 종속성으로부터 보호하고 있습니다. 그 이유는 도메인 모델이 외부에 종속되면 외부의 것이 변경되었을 때 도메인 모델도 변경되기 때문입니다. 우리의 도메인 모델은 모든 비즈니스 규칙이 있는 가장 중요한 것이어서 이 내용이 가장 중요합니다.
우리가 비즈니스 규칙이 변경을 원하지 않을 때 바깥의 무언가의 변화에도 영향을 받지 않으면 클린 아키텍처라고 할 수 있습니다. 하지만 이것은 추상적이고 구현하기 어렵습니다.
Hexagonal Architecture
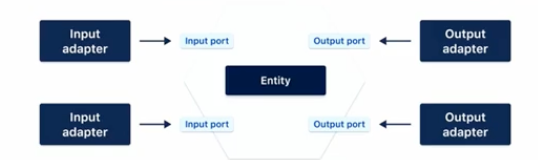
헥사고날 아키텍처는 여전히 레이어가 있고 내부로 향하는 의존성의 방향이 있다는 점에서 클린 아키텍처와 유사합니다. 가장 바깥쪽 레이어를 우리는 어댑터라고 부르고 이것을 input adapter과 output adapter으로 부릅니다. input adapter는 대표적으로 http 요청을 받는 web adapter가 있고 out adpater는 대표적으로 database adpater가 있습니다.
다음 계층은 포트입니다. input ports와 output ports는 기본적으로 인터페이스들로 되어있습니다. 이 인터페이스는 output adapter에 구현이 되어있거나 input adapter에 구현이 되어있습니다.
그리고 중간에 또다시 도메인 모델이 엔티티와 use case의 구현체로 되어있습니다. 이것의 비즈니스 규칙은 클린 아키텍처와 유사하게 도메인을 보호하는 바깥쪽에서 안쪽을 향하는 의존성으로 구현이 되어있습니다.
하지만 헥사고날 아키텍처에 더많은 구조를 넣으려면 우리는 어댑터, 포트, 및 작업하기 위한 도구를 위해 더 많은 개념을 구체화해야합니다. 작업하기 쉬운 클린 아키텍처보다는 더 많은 것을 구현해야합니다. 또한 몇가지 결함이 있습니다. 깨끗한 육각형 아키텍처는 ‘풍부한 도메인 모델(rich domain model)’에 적합합니다. 풍부한 도메인 모델은 도메인 기반 디자인(Domain Driven Design)을 적용한 것과 같습니다.
It’s great for a rich domain model
비즈니스 규칙이 포함된 풍부한 도메인 모델과 그로부터 모델링 된 객체들은 중요합니다. 만약 당신이 보호하고 싶은 풍부한 도메인 모델이 있고 이 아키텍처가 그 일을 하고 있다면 훌륭하게 해낸것입니다.
하지만 풍부한 도메인 모델이라고 부를 수 있는 코드에서 개발을 한사람은 많지 않습니다. 이것이 바로 헥사고날 아키텍처가 과잉(over-engineering)이라고 많은 사람들이 생각하는 이유입니다. 우리의 대부분은 풍부한 도메인 모델을 가지고 있지 않습니다. 다만 풍부한 도메인 모델이 없어야 한다는 말은 아닙니다.
We often don’t have a rich domain model!
풍부한 도메인 모델이 되지 못하는 이유는 다양합니다. 그것을 고려하지 못했거나 시도하고 실패했거나 적합하지 않기 때문일 수도 있습니다. 우리가 구축하는 애플리케이션에 이르기까지 풍부한 도메인 모델을 보장하지 못하는 애플리케이션 유형들이 분명 존재합니다.
Everybody interprets it differently
클린 아키텍처는 매우 추상적입니다. 클린 아키텍처를 구현하는 방법은 5가지 정도 방법이 있습니다. 헥사고날 아키텍처는 구글에 검색하면 구현하는 10가지 방법을 찾을 수 있습니다. 구현하는 방법이 가지각색입니다.
We need simplicity!
우리에게 필요한 것은 단순성(simplicity)입니다. 코드를 구성하는데 사용할 수 있는 매우 간단한 코드 구성 패턴(code organization pattern)을 갖고 싶어합니다. 이것이 현재 우리가 해결하고 싶은 문제입니다.
Component-based Architecture
모듈이라고도 불리는 컴포넌트가 의미하는 것은 함께 작업을 수행하고 함께 속해있거나 높은 응집력을 가진 클래스들의 그룹입니다. 이 컴포넌트는 다음과 같은 아키텍처의 모습을 가집니다.
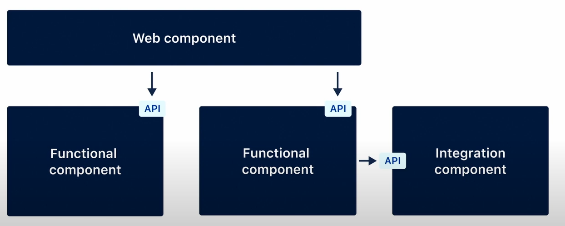
이 모습은 계층화된 아키텍처의 웹 레이어와 유사합니다. 어디에서 무엇을 입력해서 컴포넌트로 무언가를 넣을 겁니다. 그리고두가지의 ‘기능 컴포넌트(Functional component)’와 하나의 ‘통합 컴포넌트(Integration component)’를 가지고 있습니다.
이 응집력있는 클래스들의 집합은 전용 API가 있습니다. 이것이 일반적인 레이어 아키텍처와 일반적인 vertical slices 형태와 다른 점입니다. 웹 컴포넌트는 functional components를 이 api를 통해서만 호출을 할 수 있습니다. 예를 들어 middle functional component(이미지상 가운데에 있는 컴포넌트)는 오른쪽에 있는 integration component를 호출할 것입니다. integration component는 데이터베이스나 혹은 서드파티 시스템 혹은 이외의 것을 연결할 것입니다.
vertical slices에서 전용 api가 추가된 것과 매우 유사합니다. 그리고 이 컴포넌트들 안에 nested components를 추가합니다.
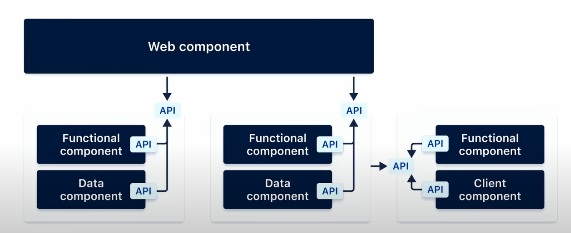
nested component는 다른 다양한 sub component 들을 구성할 수 있습니다. 우리의 parent functional components(첫번째 이미지의 합쳐진 Functional component)는 안에 functional inner component로 구성되어있습니다. 그리고 그것은 use cases와 데이터베이스나 데이터를 저장할 수 있는 저장소역할을 할 수 있는 것과 연결할 수 있는 data component로 구현되어있습니다. 따라서 각 Data component(이미지 속 2개의 data component)는 서로가 누군지 모릅니다. 다른 데이터베이스, 스키마이어도 무관합니다.
각각의 internal components나 sub components는 parent component와 같은 방식으로 전용 API를 가지게 만들었습니다. 이것은 sub components로 다시 구현될 수 있을 겁니다.
각 컴포넌트는 API 클래스에 대한 접근 권한이 있습니다. 이는 헥사고날이나 클린아키텍처와 같은 ‘의존성 역전(dependency inversion)’을 적용해서입니다. 이 그림에서 API가 가장 중요합니다. 몇몇의 도메인 클래스들을 이곳에 두고 우리는 바깥의 의존성이 들어오는 것을 보호합니다. 모든것은 이 API 패키지를 통해서 들어옵니다.
Component rules
- Namesapce
- Each component has a unique namespace
- 우리는 java의 package와 같이 컴포넌트를식별할 수 있어야 합니다.
- Each component has a unique namespace
- API
- Each component has a dedicated API package
- java로 보면 api 패키지 같은 것입니다. 또한 그 패키지는 상위 패키지로 parent component가 있고 sub package로 api가 있습니다.
- Each component has a dedicated API package
- Internal
- Each component has a dedicated “internal” package.
- internal classes를 포함하며 밖에 어느것도 이 패키지에 접근할 수 없어야 합니다. 바깥에서 들어오는 모든 것은 api 패키지를 통해서만 들어오고 내부 패키지는 접근할 수 없어야 합니다.
- Each component has a dedicated “internal” package.
- Nesting
- It’s compontnets all the way down
- nesting components는 모두 하위의 방향성으로 가야합니다.
- It’s compontnets all the way down
Namespace

우리는 같은 컴포넌트들을 같은 코드 베이스에 넣을 수 있습니다. 이들은 각각 패키지로 분리되어 같은 메이븐 혹은 그래들 모듈로 넣어 한 jar 파일로 묶을 수 있습니다.
또한 각각의 컴포넌트를 소유한 메이븐 혹은 그래들 모듈로만들 수 있습니다.

이조차도 각각의 코드베이스로 격리할 수 있습니다. 컴포넌트들이 각각 본인 스스로의 코드베이스가 있더라도 우리는 여전이 이것들을 모놀리스로 배포할 수 있습니다. 이들의 코드페이지에서 댕겨서 코드 페이지는 자바 파일들을 만들고 자바 파일을 결합합니다. 그리고 이것을 모놀리스처럼 배포할 수 있습니다. 만약 우리가 격리 수준을 가지고 있다면 우리도 또한 분리적으로 이 컴포넌트들을 배포할 수 있습니다.
이 component-based architecture가 작동하는 방식을 선택하는 것은 중요하지 않습니다.
API & Internal
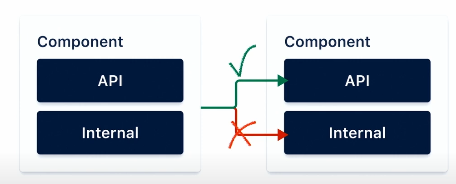
각 구성요소에는 api와 내부 패키지가 있습니다. api 패키지는 바깥에 있는 internal 패키지로부터 접근할 수 없다는 룰이 있습니다.
Nesting
왜 중첩이 하나의 컴포넌트만을 빌드하기로 결정할 수 있을까요. 전용 API가 있는 큰 컴포넌트는 여전이 우리가 정의한 컴포넌트와 같습니다. 하지만 우리는 컴포넌트의 내부구조를 신경써야합니다. 왜냐하면 API를 통하는 바깥으로부터 clean 해져도 만약 이것이 커다란 컴포넌트가 되면 내부의 모든것들은 어지러워져도 밖에서 봤을 때는 여전히 괜찮아보입니다. 만약 어떤것을 수정할 때 이것이 유지보수 불가능한 어지러운 코드여도 우리는 이 코드에서 작업해야 한다.
톰 홈버그가 제안하는 것은 다양한 sub 컴포넌트로 하나의 커다란 컴포넌트로 빌딩하여 큰 소프트웨어를 만드는 것 입니다. 다른 산업에서도 볼 수 있습니다. 자동차는 3개의 계층으로 만들어있지 않습니다. 자동차는 여러 sub components로 만들어집니다.
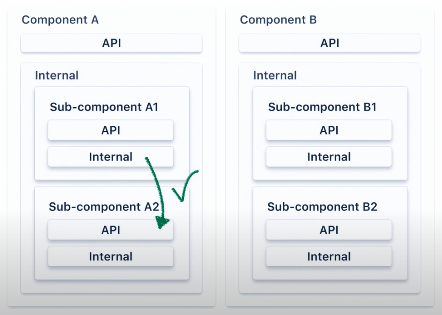
우리의 의존성은 어떻게 중첩적으로 작동할까요? 이 이미지에서는 우리는 A, B라는 두개의 컴포넌트를 가지고 있습니다. 각각의 컴포넌트는 그들 소유의 API 패키지를 가지고 있습니다. 그리고 그들은 internal packages를 가지고 있고 internal packages는 각각 A1,A2 혹은 B1,B2 sub 컴포넌트를 (예시에서는 2개의) 가지고 있습니다.
A1 컴포넌트가 A2 컴포넌트에 대해서 접근이 필요할 때 우리는 A2의 API 패키지로만 호출할 수 있을 것 입니다. 우리는 B1, B2 컴포넌트를 A1컴포넌트에서 호출할 수 없습니다. 왜냐하면 A1은 B1,B2에 대해 어느것도 알 수 없기 때문입니다.
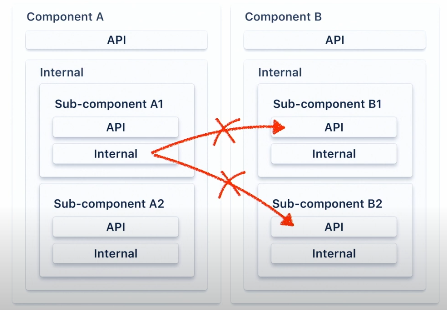
왜냐하면 이것은 parent package의 internal package에 숨겨져있기 때문입니다. 그래서 만약 A1 컴포넌트가 B1, B2 컴포넌트가 구현하는 모든 컴포넌트 접근이 필요해도 허용되지 않습니다.
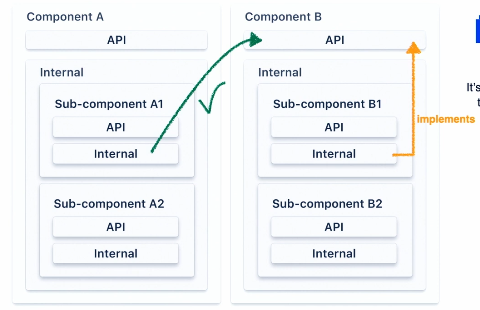
component A1에서 컴포넌트 B1의 구현 기능이 필요한 경우는 컴포넌트 B에 노출된 API를 거쳐서만 기능적으로 접근할 수 있습니다. 우리는 컴포넌트 B는 호출이 가능합니다. 왜냐하면 기능적으로 public으로 노출된 것과 유사하기 때문입니다.

유사하게 같은 parent component에 속한다 하더라도 A1 컴포넌트는 A2 내부 패키지를 호출할 수 없습니다. 그렇게 하려면 컴포넌트 A2의 API에서 필요한 기능을 노출해야 하는 것과 동일한 작업을 수행해야 하며 그 다음 API를 호출할 수 있습니다.
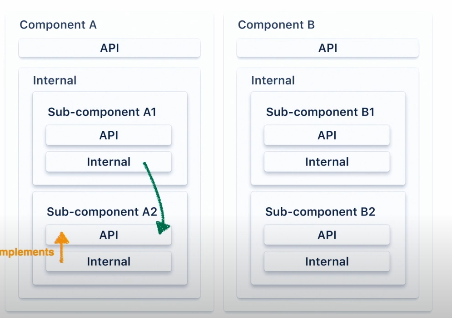
이 방법은 우리에게 API 내부에 대한 완전한 제어를 제공합니다. 우리는 API에 영향을 미치지 않기 때문에 컴포넌트의 내부 패키지 내에서는 무엇이든 리팩토링할 수 있습니다.
발표 영상을 정리하는 것이 처음이다보니 내용 및 번역에 대해 문제가 많을 수 있습니다. 피드백 주시면 반영하겠습니다 :)
Reference
Let's build components, not layers
