연속된 값이 데이터일 경우 regression을 사용하는게 알고리즘 선택으로서 적절하다는 앞선 포스팅이 있었다.
임의로 연속된 데이터를 만들어 주자.
import numpy as np
r = np.random.RandomState(10)
x = 10 * r.rand(100)
y = 2 * x - 3 * r.rand(100)x와 y의 모양을 shape를 통해 알아보자.
x.shape, y.shape
----------------
((100,), (100,))둘다 1차원 벡터인 것을 확인할 수 있다.
머신러닝 모델을 사용하기 위해선 모델 객체를 생성한다.
이 예제에서 사용할 모델은 Linear regression이다. sklearn.linear_model안에 있다.
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model
--------------------------------------------------------
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None, normalize=False)
모델을 학습시키려는 데 에러가 납니다
model.fit(x, y)
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-3-d3dc977168f5> in <module>()
----> 1 model.fit(x, y)
2 frames
/usr/local/lib/python3.7/dist-packages/sklearn/utils/validation.py in check_array(array, accept_sparse, accept_large_sparse, dtype, order, copy, force_all_finite, ensure_2d, allow_nd, ensure_min_samples, ensure_min_features, warn_on_dtype, estimator)
554 "Reshape your data either using array.reshape(-1, 1) if "
555 "your data has a single feature or array.reshape(1, -1) "
--> 556 "if it contains a single sample.".format(array))
에러가 너무 기네요....에러가 나는 이유는 간단하다. x는 지금 벡터이므로 행렬로 바꾸어 주어야 한다.
x는 numpy의 ndarray타입이니 reshape()를 사용하면 간단하게 바꿀 수 있다.
통상 feature matrics(특성 행렬)의 변수명은 X로 한다 했으니, 변수 X에 넣어주자.
X = x.reshape(100,1)다음 학습을 시켜주면 정상적으로 작동한다.
model.fit(X,y)
---------------------------------------------------------------------
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None, normalize=False)학습을 완료시켰으니 새로운 데이터를 넣어 예측을 해볼 차례이다.
새로운 데이터는 아래와 같이 임의로 생성해주자.
x_new = np.linspace(-1, 11, 100)
X_new = x_new.reshape(100,1) # vector -> matrics
y_new = model.predict(X_new)[reshape() Tip]
함수에서 나머지 숫자를 -1로 넣으면 남은 숫자를 자동으로 계산해 준다.
위 코드로 x_new의 인자갯수가 100개이므로,
(100,1) 형태나 (2, 50) 형태 등으로 변환해 줄 수 있다.
(2, -1)와 같이 인자를 넣어주면 (2, 50)의 형태로 자동 변환해준다.
X_ = x_new.reshape(-1,1)
X_.shape
-----------------------------------
(100, 1)학습된 모델이 예측을 잘 했는지 성능을 평가해보자. 성능 평가 관련된 모듈은 sklearn.metrics안에 있다. 회귀 모델(regression model)의 경우 RMSE(Root Mean Squared Error)를 사용해 성능을 평가한다.
mean squared error
위의 링크에 들어가면 RMSE는 없고 MSE만 있을 것이다. R에 해당하는 함수는 Numpy 패키지에 np.sqrt()를 사용하면 된다.
from sklearn.metrics import mean_squared_error
error = np.sqrt(mean_squared_error(y, y_new))
print(error)
----------------------------------------------------
9.299028215052264matplotlib를 통해서 확인해볼 수 있다.
plt.scatter(x, y, label='input data')
plt.plot(X_new, y_new, color='red', label='regression line')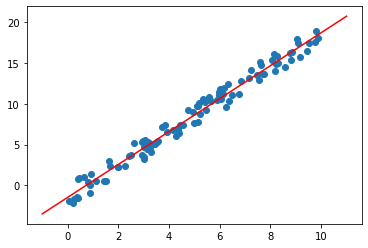
데이터 들과 예측한 선이 거의 일치하는 것을 볼 수 있다.
