결과물 미리 보기 : https://www.midubang.com/text/chat
들어가며...
요즘 개발판에서 chatGPT가 정말 핫한 것 같습니다. 개발 좀 한다는 사람들은 chatGTP를 이용해 창의적인 서비스를 만들고 계신 것 같은데요. 심지어 개발자가 아니더라도 다들 한번 쯤은 chatGPT를 사용해보신 것 같습니다...!
그리고 프론트엔드 개발자인 저는 chatGPT 덕분에 매우매우 신이 납니다...🤩
chatGPT 덕분에 백엔드 개발자 없이도 개성있는 사이트를 만들 수 있기 때문입니다!!
가장 단순한 챗봇부터 시작해서, ReadMe 생성기, 이미지 생성기, 작곡 AI 사이트, 미니 게임 사이트 등...
하지만 이 모든 것을 실제로 만들기 위해선 chatGPT API를 사용할 줄 알아야하겠죠.
그동안 제가 chatGPT api를 이용해 프로젝트를 하면서 알게된 지식들을 정리해보고, chatGPT api, Flask, React를 사용해 간단한 챗봇 사이트를 만들어보겠습니다.🎉
이 글은 chatGPT api를 처음 접하는 프론트엔드 개발자가 chatgpt api를 활용해 다양한 서비스를 자유롭게 만들 수 있도록 chatGPT api의 사용법, 프롬프트 엔지니어링 등에 대해 설명합니다.
📢 선수 학습 사항
react와 flask는 설명하지 않습니다.
✨ chatGPT API란

ChatGPT API란, OpenAI에서 만든 대화형 인공지능 모델인 ChatGPT를 API로 사용할 수 있는 API입니다.
기존에는 OpenAI의 API를 활용할 때 ChatGPT와는 다른 AI 모델을 사용하였지만, 이제는 ChatGPT에서 사용하는 모델과 동일한 모델인 gpt-3.5-turbo를 사용할 수 있게 되어씩에 대화식 채팅에 있어서 성능이 뛰어나다고 합니다.
이 chatGPT API 덕분에 누구나 ChatGPT를 기반으로 새로운 애플리케이션을 개발하거나 기존 서비스에 ChatGPT를 통합하기 용이합니다.
ChatGPT API는 HTTP 프로토콜 기반 Rest API 형태로 되어 있어 네트워크를 통해 요청을 받고 응답을 반환합니다.
✨ chatGPT API 사용 가이드
chatGPT API 사용법에 대해 A to Z로 하나하나 알아보겠습니다.
✅ 1. openAI API 회원가입
OpenAI는 API 키를 통해 ChatGPT API를 호출하는 사용자를 인증하고 이용량에 따라 과금하고있습니다. 따라서 우리는 ChatGPT API를 호출할 때 HTTP 요청에 API 키도 함께 실어 보내야 합니다.
API 키를 발급 받으려면 먼저 OpenAI에서 회원 가입을 해야합니다. 한번이라도 ChatGPT를 사용해보신 분들은 아 이미 계정이 있으실 것입니다.
계정이 없다면 회원가입을 하시고, 이미 있다면 로그인 해주세요. 참고로 구글 계정 로그인도 가능합니다.
✅ 2. Playground
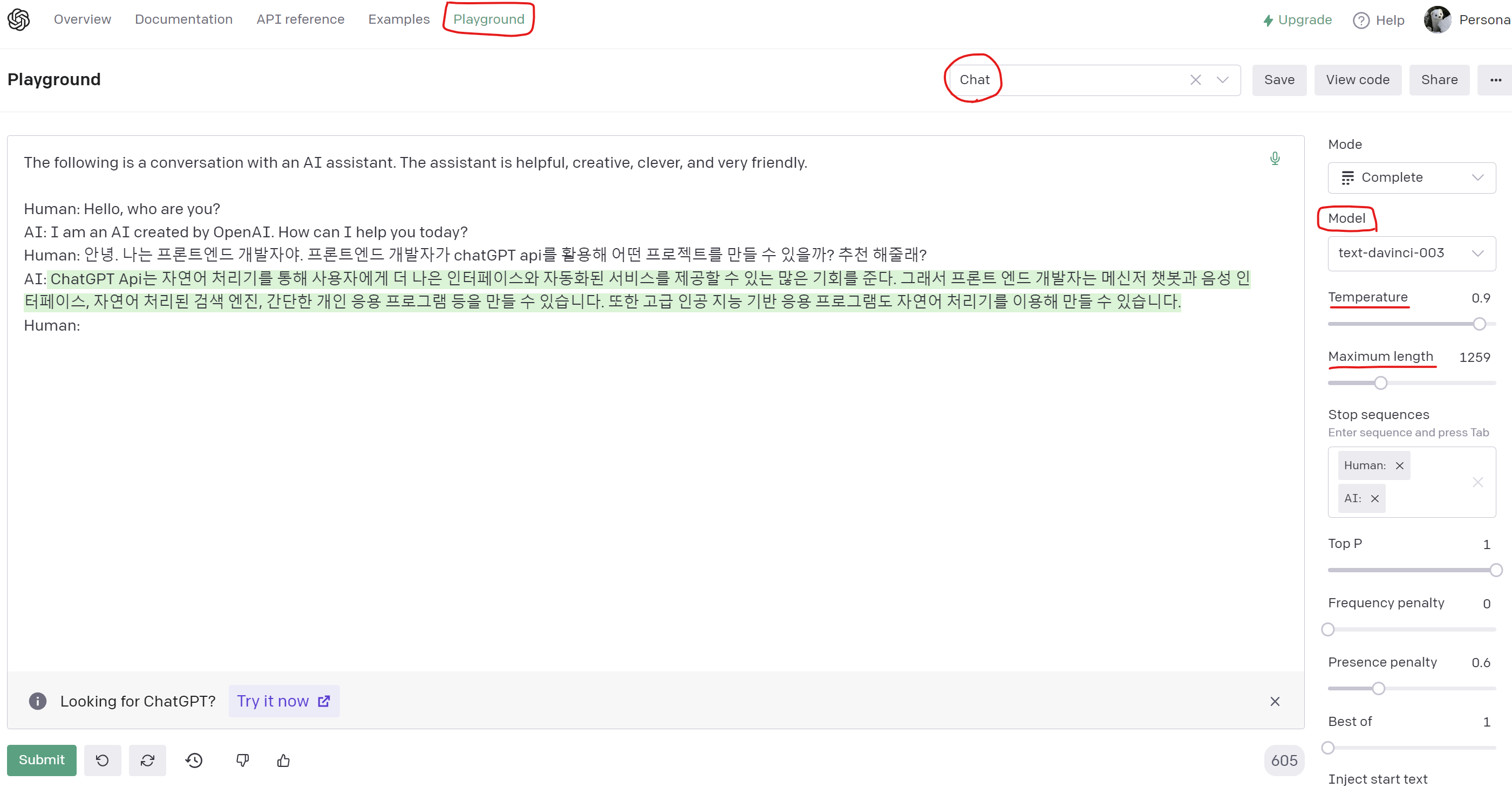
Playground에 접속하시면 openAI에서 제공하는 여러 모델을 테스트해볼 수 있습니다.
코딩을 모르는 사람이라도 OpenAI Playground에서 openAI의 다양한 모델을 직접 테스트 해볼 수도 있습니다.
목적에 따른 모델을 추천해주고, Temperature, Max length 등의 parameter도 조절 가능해서 api 사용 전에 간단히 테스트 해보기 좋은 환경입니다.
✅ 3. API reference tab
API reference tab에서 api 사용법에 관한 정보를 얻을 수 있습니다.
✅ 4. API secret key 발급 받기
Personal tab에서 api key를 발급받고 관리할 수 있습니다.
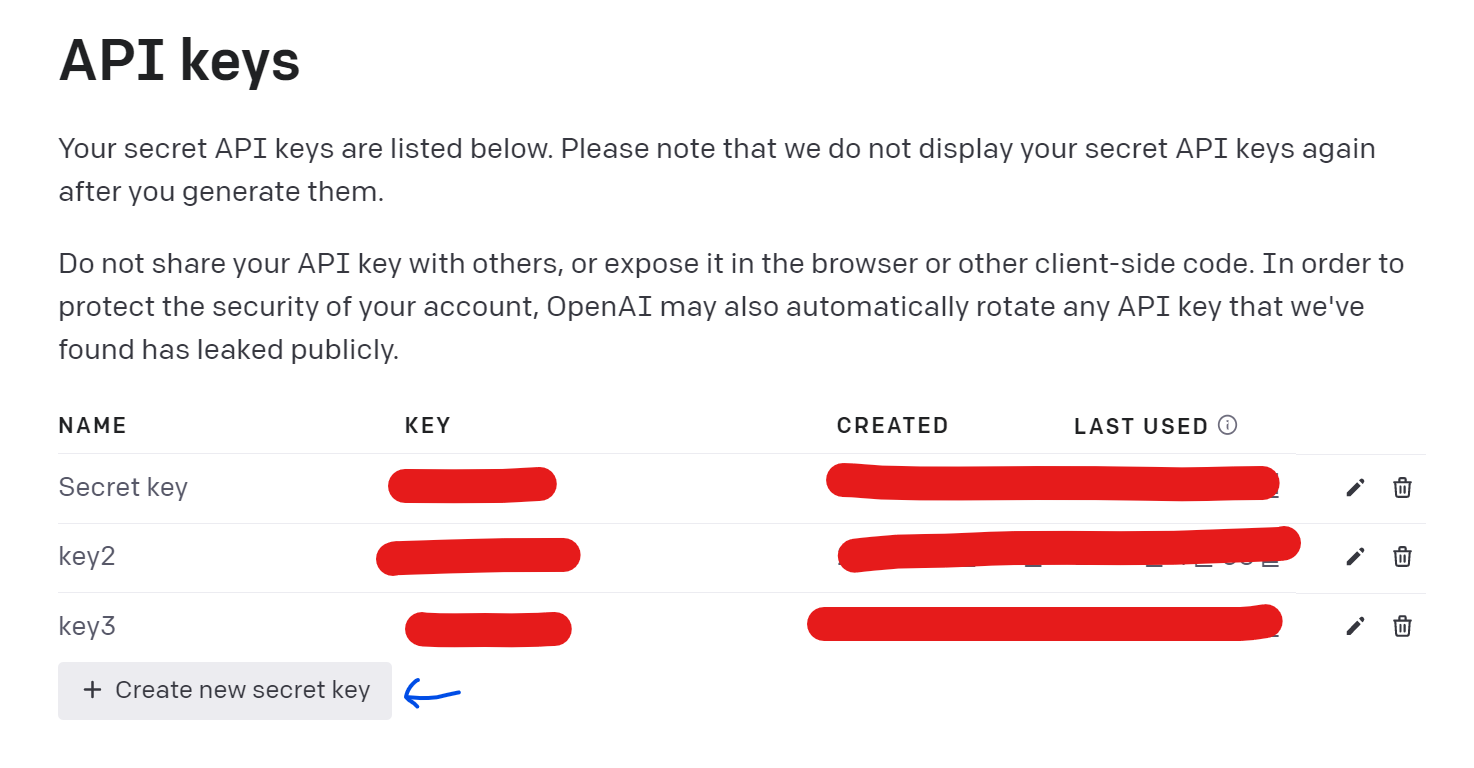
+ create new secret key를 눌러 시크릿 키를 발급받아주세요.
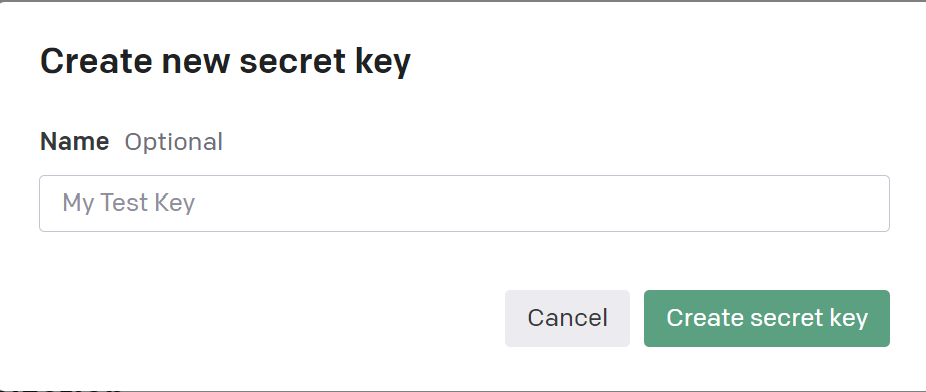
key 이름은 아무거나 입력하면 됩니다.
OK 버튼을 누르기 전에 key를 복사해 안전한 곳에 저장해두셔야합니다.
한번 OK 버튼을 누르면 다시 key를 열람할 수 없이 때문입니다.
🚨 API 키 관리 주의
secret key는 절대!!!!!!!!! 외부에 노출하면 안됩니다. API 키가 실수로라도 프로그램 코드를 통해 노출되지 않도록 각별히 주의해주세요.
(필자는 한번 실수로 secret key가 존재하는 .env를 깃허브에 올렸다가 api key expire만 10번 정도 겪었습니다 ... 레포를 지우지 않는 이상 해결이 안되고, 재발급한 key까지 계속 expire됩니다. 이럴 땐 openAI 다른 계정으로 key를 다시 발급 받는 것이 정신 건강에 좋습니다.)
✅ 5. 개발환경 설정 및 Python openai 라이브러리 설치
시크릿 키를 발급 받았으니 이제 api를 사용해보겠습니다.

위처럼 openAI에서 api 사용 예제를 python과 javascript로 제공해주고 있는데요,
저는 python으로 작업하겠습니다.
JS보다 python을 사용한 레퍼런스가 훨씬 많기도 하고, 저는 Flask api server를 구축할 것 이기 때문입니다.
(+ client server와 api server를 분리하는게 이상적이기도 하구요)
5-1 .env 파일에 secret key 보관
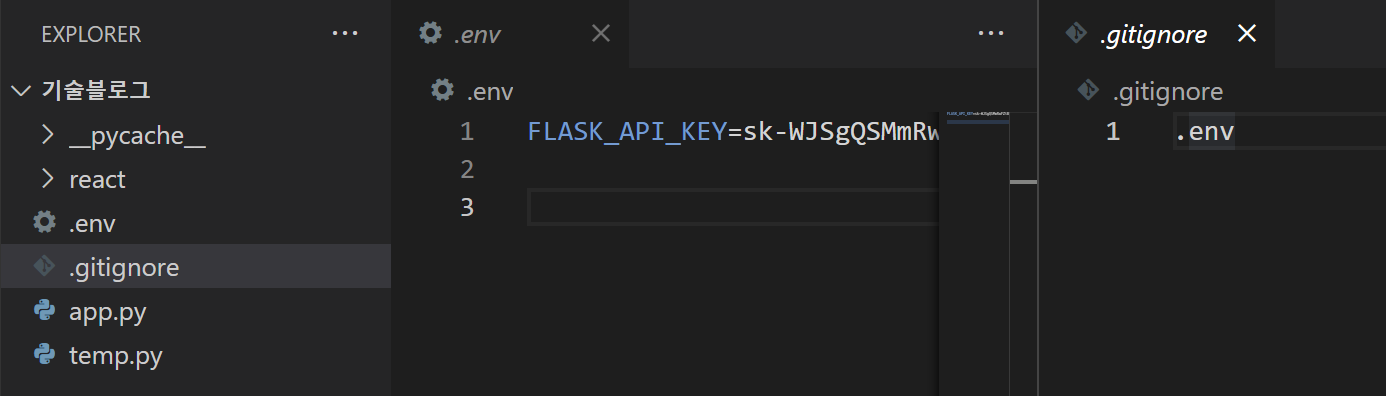
flask 프로젝트 root에 .env 파일을 만들고 다음과 같이 작성해주세요.
FLASK_API_KEY=아까 발급 받았던 secret keykey는 " " 안에 감쌀 필요 없습니다. 그냥 있는 그대로 넣어주세요!
그리고나서 .gitignore 파일을 만들고 .env 를 써주세요. 깃허브에 .env 파일을 올리지 않겠다는 뜻입니다. secret key가 깃허브에 커밋되면 안되기 때문에 가장 중요한 부분입니다!
5-2 필요한 모듈과 라이브러리 세팅
API Key 발급을 잘 받으셨다면 개발 환경을 설정하고 Python OpenAI 라이프러리를 설치 하여 코드 작성할 준비를 해보겠습니다.
참고로 Python에서 OpenAI API를 사용하여 애플리케이션을 개발하려면 컴퓨터에 Python 3.6 이상이 설치되어 있어야 합니다.
그리고 http를 통해 openai api를 사용하기 위해선 openai라는 모듈을 다운 받아야합니다.
명령어 창에 다음과 같이 작성해주세요.
pip install openai저는 Flask 서버를 만들 것이기 때문에 다음 모듈도 다운 받아줍니다. 저는 나중에 flask 서버를 배포해 사용할 것이기 때문에 CORS 허용도 추가해줬습니다.
pip install Flask flask_cors마지막으로 app.py에 아래 처럼 작성해주세요. 필요한 모듈을 import 하는 코드입니다.
# app.py
from flask import Flask
from flask import request, jsonify
from flask_cors import CORS
import openai
import os
app = Flask(__name__)
CORS(app)flask 서버를 실행하고 싶다면
flask run을 실행하면 됩니다.
✅ 6. API 호출 예제
#app.py
API_KEY= os.getenv("FLASK_API_KEY")
def chatGPT():
# set api key
openai.api_key = API_KEY
# Call the chat GPT API
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": f"한국의 대통령은 누구입니까?"},
],
temperature=0,
max_tokens=2048
)
return completionchatGPT api를 호출하는 간단한 함수입니다.
가장 먼저 os.getenv라는 코드를 통해 .env파일에 있는 api secret key를 가져왔습니다. openai.api_key = API_KEY로 openai 객체에 키를 등록합니다.
그리고 openai.ChatCompletion.create을 통해 ChatGPT API를 객체를 생성합니다.
completion 객체의 구성은 다음과 같습니다.
- model : api의 모델 (ChatGPT에서 사용된 모델을 사용하기 위해서는
gpt-3.5-turbo로 지정해야함)- message : 메세지 내용, 사용자의 입력과 모델의 출력이 포함됨 (chatGPT에서 프롬포트에 작성하던 그 부분이다.)
- temperature : 답변의 다양성을 지정하는 파라미터.
- max_token : 답변의 길이 제한
6-1 Role
역할(Role)은, 시스템(System), 보조자(Assistant), 사용자(User)로 구분 됩니다. 각 역할의 용도가 다릅니다.
1. 시스템 (System)
ChatGPT에게 어떤 행동을 해야하는지 지정하는 기능입니다.
보통은 ChatGPT에서 상황을 설정하거나, Act as a ___ , 너는 변호사 로봇이다와 같이 역할을 부여할 때 사용됩니다.
2. 보조자(Assistant)
chatGPT api는 기본적으로 세션이 유지되지 않아 이전 대화 내용을 기억하지 못합니다.
assistant를 사용하면 이전 대화를 저장하고 연속성을 유지하기 위해 사용되며 이어지는 답변에 영향을 줄수 있습니다. 이전 내용을 바탕으로 프롬프트를 요청 하고자 할때 사용 하실 수 있습니다.
즉 이전 대화 기록을 참조할 수 있도록 정보를 제공하는 용도입니다.
3. 사용자(User)
User는 chatGPT에게 질문하는 질문 내용입니다. 사용자의 역할은 보조자(Assistant)와 마찬가지로 이전 대화를 저장하고 연속성을 유지하기 위해 사용되며 이어지는 답변에 영향을 줄수 있습니다.
6-1-1 Role 사용 예시
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a machine that determines whether two sentences are similar."},
{"role": "system", "content": "The following two sentences are special provisions of monthly rent contracts in Korea."},
{"role": "system", "content": "Determine if both special contracts are written for similar cases."},
{"role": "system", "content": "If the purpose of the two clauses is the same, if one sentence includes the other sentence, or if the core meaning of the two sentences is the same, the evaluation is 'yes'."},
{"role": "system", "content": "The answer format should be yes or no only."},
{"role": "user", "content": f"answer yes or no => s1. {st1} 2. {st2}"}
],
temperature=0,
max_tokens=10,
)
return completion["choices"][0]["message"]["content"].encode("utf-8").decode()실제 적용하면 이렇습니다. 위 예제는 두가지 특약이 비슷한 효력을 가진 특약인지 판단하는 gpt API 코드입니다.
system role을 사용해 답변 형식을 지정하고 지시 사항을 보다 명확하게 고쳤습니다.
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": f"Q: For the sentence pair '계약 연장은 계약 만기 3달 전까지 갱신 의사를 밝혀야만 가능하다.' and '계약 만기 5개월 전 까지 재계약 의사를 밝히지 않은 경우, 계약은 만료되는 것으로 간주한다.', do these two sentences have the same semantics?"},
{"role": "assistant", "content": " First, identify the key differences between the two sentences. Second, consider the impact of the difference in wording. Third, consider the overall meaning of the two sentences. Therefore, given that the two sentences convey the same general idea, despite the difference in wording, we can conclude that they have the same semantics. The answer (yes or no) is: yes."},
{"role": "user", "content": f"Q: For the sentence pair {st1} and {st2}, do these two sentences have the same semantics? The answer (yes or no) is: ____"}
],
temperature=0,
)또 다른 예시 입니다. 이번엔 assistant role을 사용했는데요,
두가지 특약 문장이 비슷한 효력을 가지는지 판별하는 질문에 assistant가 답변한 내용을 참조할 수 있게 제공한 것입니다.
이를 통해 gpt가 어떤 논리와 과정으로 답변을 추론해야하는지에 대한 힌트를 얻는 것입니다. 이런 프롬포트 엔지니어링 전략을 CoT라고 합니다.
CoT (Chain-of-Thought)란?
단지 답변을 내놓기 위한 것이 아닌, 답변에 도달하는 과정을 학습시키는 것을 목적으로 본 질문 전에 미리 태스크와 추론 과정을 포함한 답변 예제를 AI에게 제공하는 프롬포트 전략입니다.
6-2 Temperature
role 말고도 중요하게 사용되는 파라미터로 temperature, max_tokens이 있습니다.
temperature의 경우 답변의 다양성(degree of diversity) 정도를 나타내며 높을수록 창의적인 결과물을 만들어줍니다.
temperature이 높을수록 모델이 생성하는 문장이 더 다양해지고, 값이 낮을수록 더 일관성 있는 문장이 생성되는 것입니다.
temperature값이 높은 경우, 다양한 선택지를 고려하여 텍스트를 생성합니다. 반면에, temperature 값이 낮은 경우, 모델은 가능한 선택지 중에서 가장 확률이 높은 것을 선택하게 됩니다. 그래서 temperature 값이 낮을 셩우 일관성 있는 텍스트 결과가 만들어지고 일반적이거나 예상 가능한 결과를 만들 수도 있습니다.
temperature의 범위는 0에서 무한대이지만 일반적으로 0.5 ~ 1.0 사이의 값이을 주로 사용합니다.
정보성 글일때는 낮은 온도를, 창의성이 필요한 경우에는 높은 온도로 설정하여 사용합니다. 참고로 default값은 0.7입니다.
대한민국의 대통령을 물어본다고 가정했을때, temperature에 따른 답변은 다음과 같습니다.
# temperature=0인 경우
{
"result": "현재 대한민국의 대통령은 문재인입니다."
}# temperature=1.0인 경우
{
"result": "저는 인공지능으로써 정치적 중립성을 유지해야 하므로 대한민국의 대통령에 대해 언급하지 않습니다."
}6-3 max_tokens
텍스트의 최대 길이(max_tokens)는 생성되는 텍스트의 최대 길이를 지정하는 값입니다. 기본값은 256이며 최대값은 2048입니다.
prompt = f"대한민국의 대통령은 누구입니까?"
# set api key
openai.api_key = API_KEY
# Call the chat GPT API
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": prompt},
],
temperature=0.8,
max_tokens=10
)위처럼 max_token은 너무 짧게 지정하면 답변 길이가 잘려서 반환됩니다.
# 답변
{
"result": "현재 대한민국의 대"
}6-4 response
gpt api의 response 값을 출력해보면 다음과 같이 생겼습니다.
{
"result": {
"choices": [
{
"finish_reason": "stop",
"index": 0,
"message": {
"content": "저는 인공지능 어시스턴트이기 때문에 현재 시점에서 대통령이 누구인지 파악할 수 없습니다. 하지만 2021년 8월 기준으로 대한민국 대통령은 문재인 대통령입니다.",
"role": "assistant"
}
}
],
"created": 1684061777,
"id": "chatcmpl-7G3gfKva4UNOd9dzcnBnOBYlJel3j",
"model": "gpt-3.5-turbo-0301",
"object": "chat.completion",
"usage": {
"completion_tokens": 82,
"prompt_tokens": 27,
"total_tokens": 109
}
}
}이 중 우리는 gpt의 답변 부분인 "content"만 뽑아서 사용하면 됩니다.
completion["choices"][0]["message"]["content"].encode("utf-8").decode()위처럼 수정해서 return하면 됩니다.
6-5 model
보통 chatGPT api라 하면 gpt3.5-terbo 모델을 뜻하는데요.
하지만 챗봇이 아닌 다른 목적으로 gpt api를 사용하시는 경우라면 다른 모델을 선택하는 것도 좋은 방법입니다. 각 모델은 저마다 잘하는 일이 다르기 때문입니다.
- Davinci
- 주요 기능: 1,750억 개의 매개변수가 있는 가장 크고 가장 유능한 GPT-3 모델로, 매우 일관되고 상황에 맞는 응답을 생성합니다.
- 작동 방식: 입력 프롬프트를 분석하고 방대한 양의 데이터에서 학습한 패턴을 기반으로 응답을 생성하여 작동합니다.
- 적용 사례: Davinci는 언어 번역, 콘텐츠 생성 및 제품 추천과 같은 복잡한 작업에 이상적이라 할 수 있습니다.
- 비용: 0.02달러 / 1000 토큰.
- Curie
- 주요 기능: 67억 개의 매개변수가 있는 GPT-3 모델로, 컨텍스트 이해가 필요한 자연어 처리 작업에 이상적입니다.
- 작동 방식: 입력 프롬프트를 분석하고 방대한 양의 데이터에서 학습한 패턴을 기반으로 응답을 생성하여 작동합니다.
- 적용 사례: Curie는 챗봇, 콘텐츠 생성 및 언어 번역에 이상적입니다.
- 비용: 0.002달러 / 1000 토큰.
- Babbage
- 주요 기능: 13억 개의 매개변수가 포함된 GPT-3 모델로, 더 단순한 자연어 처리 작업에 이상적입니다.
- 작동 방식: 입력 프롬프트를 분석하고 방대한 양의 데이터에서 학습한 패턴을 기반으로 응답을 생성하여 작동합니다.
- 적용 사례: Babbage는 간단한 챗봇, 언어 번역 및 Q&A 애플리케이션에 이상적입니다.
- 비용: 0.005달러 / 1000 토큰.
- Ada
- 주요 기능: 12억 개의 매개변수가 포함된 GPT-3 모델로, 텍스트 프롬프트에 대해 일관되고 적절한 응답을 생성하는 데 이상적입니다.
- 작동 방식: 입력 프롬프트를 분석하고 방대한 양의 데이터에서 학습한 패턴을 기반으로 응답을 생성하여 작동합니다.
- 적용 사례: Ada는 챗봇, 콘텐츠 생성 및 언어 번역에 이상적입니다.
- 비용: 0.0004달러 / 1000 토큰.
위에서 확인할 수 있는 것처럼 매개변수를 가장 많이 사용한 다빈치 (Davinci) 모델이 가장 파워풀하며 음악 작곡이나 스토리 텔링과 같은 창의적인 작업의 프롬프트 엔지니어링에 가장 적합하다고 합니다.
이에 대조적으로 Ada 모델의 경우 12억 개의 매개변수만을 통해 학습되었기에 창의적인 작업보다는 단순 언어 번역 등에 적합하다 할 수 있을 듯하며 비용적인 측면에서도 1000 토큰 당 0.0004 달러로 가장 저렴함을 알 수 있습니다.
✅ 7. Rate limit
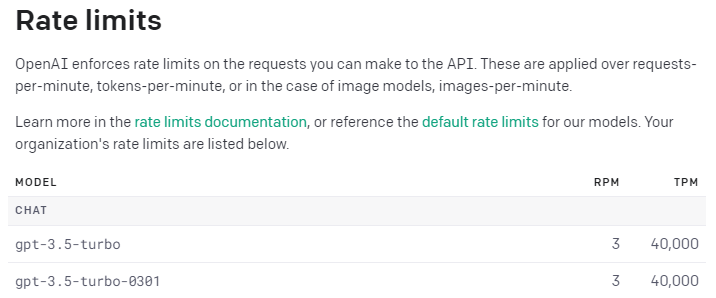
openAI의 api는 RPM과 TPM이라는 limit이 있습니다.
RPM과 TPM은 GPT API의 사용량 및 처리 속도를 추적하고 제한하는 데 사용되는 지표입니다. API 요청을 할 때 이러한 제한 사항을 고려하셔야 API를 효율적으로 사용할 수 있습니다.
7-1 RPM (Requests per Minute)
RPM은 GPT API에서 처리할 수 있는 요청의 수를 분 단위로 나타냅니다. 이는 클라이언트가 GPT API로 보낼 수 있는 최대 요청 수를 나타내며, 초과하면 추가 요청은 거부될 수 있습니다.
그리고 최근 gpt-3.5-turbo 모델의 무료 api의 Requests per Minute이 많이 줄었습니다.
2023년 3월까진 무료 api의 RPM이 분당 20회였는데, 4월 쯤 부턴 분당 3회로 대폭 줄었습니다 ㅠㅠ
7-2 TPM (Tokens per Minute)
TPM은 GPT API가 처리할 수 있는 토큰(단어 또는 문자)의 수를 분 단위로 나타냅니다.
GPT-3.5 모델의 경우, 요청하는 문장의 길이에 따라 처리할 수 있는 토큰의 수가 달라집니다. 예를 들어, 긴 문장은 더 많은 토큰을 사용하므로 TPM이 상대적으로 낮아질 수 있습니다.
그리고 영어에 비해 한글은 토큰에서 손해가 큽니다. 이는 같은 길이일 때 영어보다 한글의 토큰수가 더 크다는 뜻입니다.
openai에서 텍스트의 토큰을 계산해주는 Tokenizer를 제공해주고있습니다.
토큰 계산기 사용해보기 >>
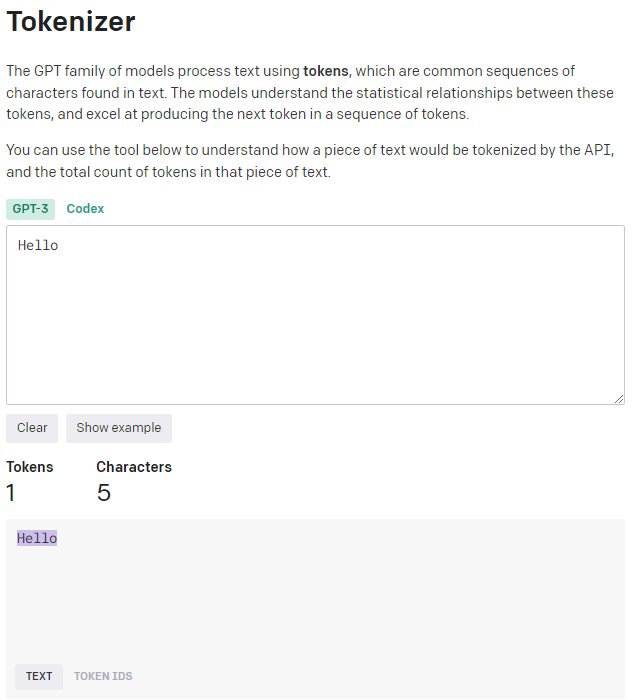
영어는 다섯자 (Hello)가 1토큰인데 비해,
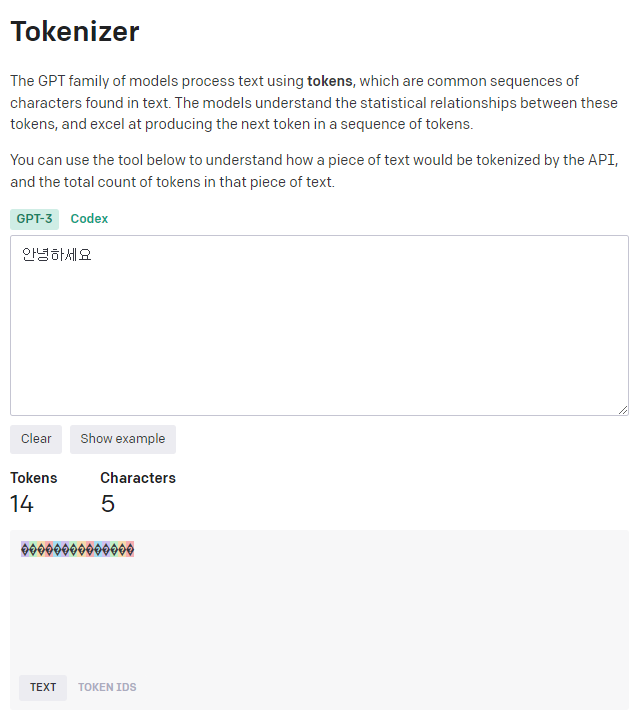
한글 다섯글자는 14토큰입니다.
이런 한글의 특성 때문에 message를 한글로 구성할 경우 토큰 제한을 고려해야합니다.
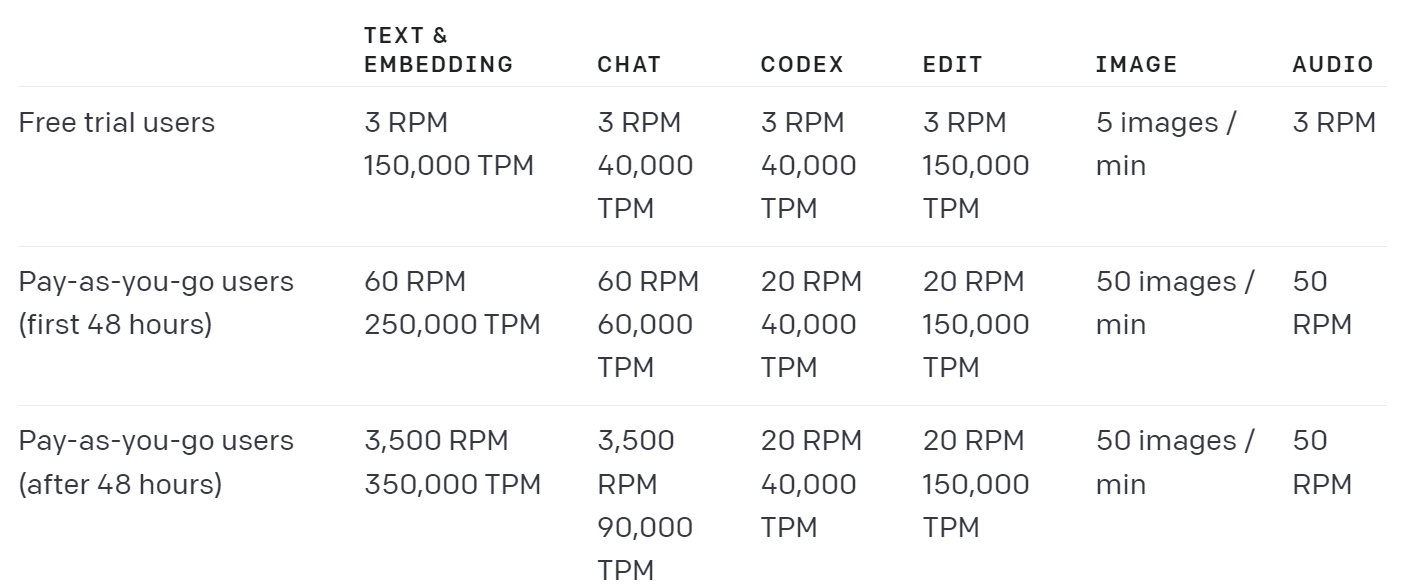
그리고 rate limit은 유료 결제를 할 경우 매우 널널해집니다.
저는 결제하고 사용하시는 것을 적극 권장드리고 싶습니다.
ChatGPT에 사용되는 gpt-3.5-turbo 모델의 경우 1,000 토큰당 0.0002 달러로 상당히 저렴합니다.
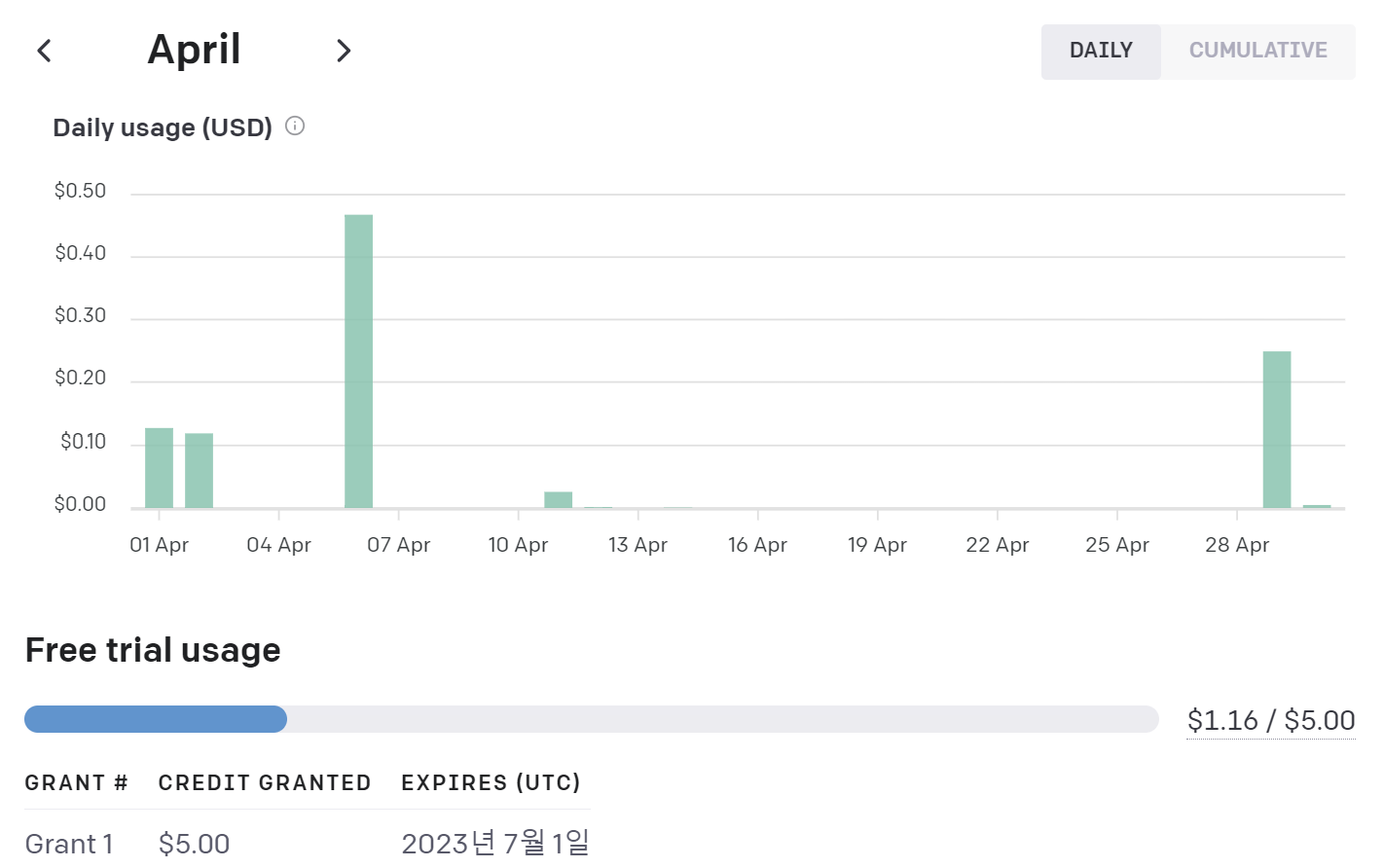
위 사진은 제가 졸업 프로젝트 개발을 위해 3월부터 5월까지 사용한 api 사용량입니다. 보시다싶이 Free trial usage로 제공되는 $5도 아직 다 못쓴 상황입니다. 그만큼 무료 제공량이 널널합니다.
rate limit에 대한 더 자세한 내용은
open ai rate limit documents 에서 확인할 수 있습니다.
✅ 8. 그 외 알고있으면 좋은 팁
- 위에서 이미 눈치채셨겠지만, gpt api 는 real-time 시스템이 아니기 때문에 실시간 데이터를 요구하는 질문은 할 수 없습니다. 대략 2021년까지의 데이터를 학습한 상태이므로, gpt에게 한국의 대통령이 누구인지 물어보면 문재인이라 답하는 것이 이 때문입니다.
- gpt api가 평소에는 잘 작동하다가 이상하게 특정 시간에만 느려질 때가 있습니다. 이는 openAI 사용자가 몰리기 때문에 발생합니다. 특히 밤 시간대는 외국 사용량이 많아져 속도가 저하될 수 있습니다.
✨ Flask로 chatGPT API 호출하기
chatGPT api에 대해 전반적으로 알아보았으니, 이제 프로젝트에 적용해보겠습니다.
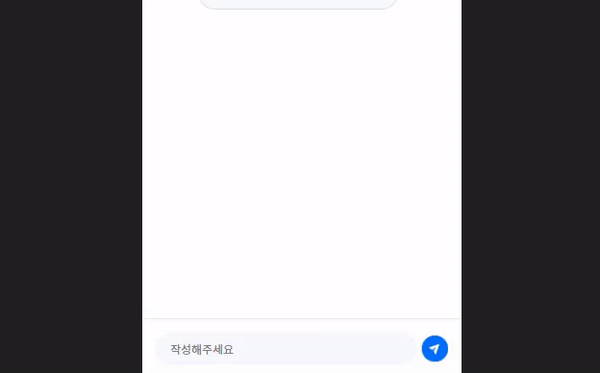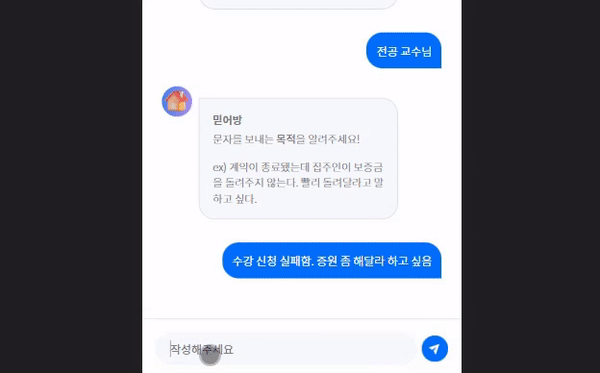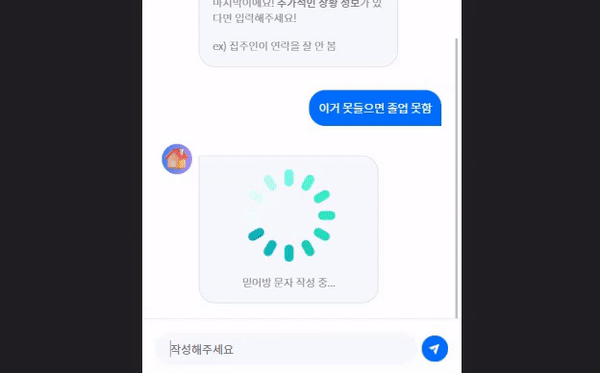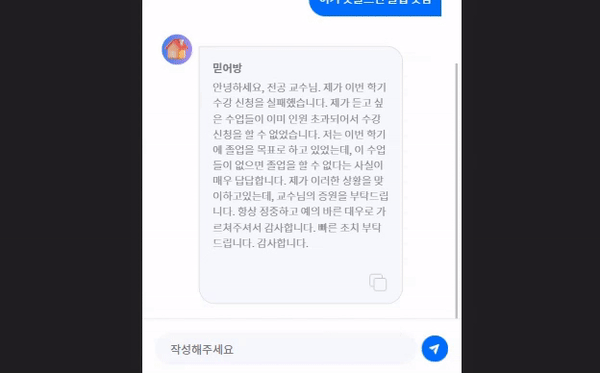
저는 제가 원하는 메일이나 문자를 작성해주는 챗봇을 만들고 싶습니다.
먼저 api 코드를 작성했습니다.
#app.py
from flask import Flask
from flask import request, jsonify
from flask_cors import CORS
import openai
import os
app = Flask(__name__)
CORS(app)
API_KEY= os.getenv("FLASK_API_KEY")
@app.route("/api/text", methods=["POST"])
def TextMassageMaker(API_KEY=API_KEY):
input = request.get_json()
# request body 값
receiver = input["receiver"]
purpose = input["purpose"]
tone = input["tone"]
more_info = input["more_info"]
# set api key
openai.api_key = API_KEY
# Call the chat GPT API
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "너는 문자를 작성하는 문자 마법시이다. 조건에 맞게 문자를 최대한 길게 작성하라."},
{"role": "system", "content": "문자의 시작은 '안녕하세요'로 한다\n- 도입에 내가 누구인지 밝힌다.\n- 서론, 본론, 결론의 구성으로 작성하고 문단별로 줄바꿈을 한다.\n- 문자 내용만 출력한다."},
{"role": "user", "content": f"1. 수신자 : ${receiver}\n2. 문자 쓰는 목적 : ${purpose}\n3. 문자의 어조 : ${tone}\n4. 추가적인 상황 정보 : ${more_info}"},
],
temperature=0.8,
max_tokens=2048
)
message_result = completion["choices"][0]["message"]["content"].encode("utf-8").decode()
return jsonify({"result": message_result})
if __name__ == '__main__':
app.run(host = '127.0.0.1', debug=True, port=5000)request body를 통해 네가지 파라미터를 받았습니다.
- receiver : 수신자
- purpose : 메일(문자)를 보내는 이유
- tone : 텍스트의 어조
- more_info : 메일(문자) 작성에 필요한 추가적인 상황 정보
그리고 system role을 사용해 gpt가 메일(문자)를 더 잘 쓸수 있도록 프롬포트를 작성했습니다.
- 역할 부여 : 너는 문자를 작성하는 문자 마법시이다.
- 명령 : 조건에 맞게 문자를 최대한 길게 작성하라.
- 조건 : 문자의 시작은 '안녕하세요'로 한다 \n 도입에 내가 누구인지 밝힌다. \n 서론, 본론, 결론의 구성으로 작성하고 문단별로 줄바꿈을 한다.\n 문자 내용만 출력한다.
이렇게 프롬포트를 잘 작성하는 것이 매우 중요합니다.
그래야 내가 원하는 일관적인 답변을 얻을 수 있기 때문입니다!
Postman 테스트 결과
postman으로 답변이 잘 오는지 테스트 해보았습니다.
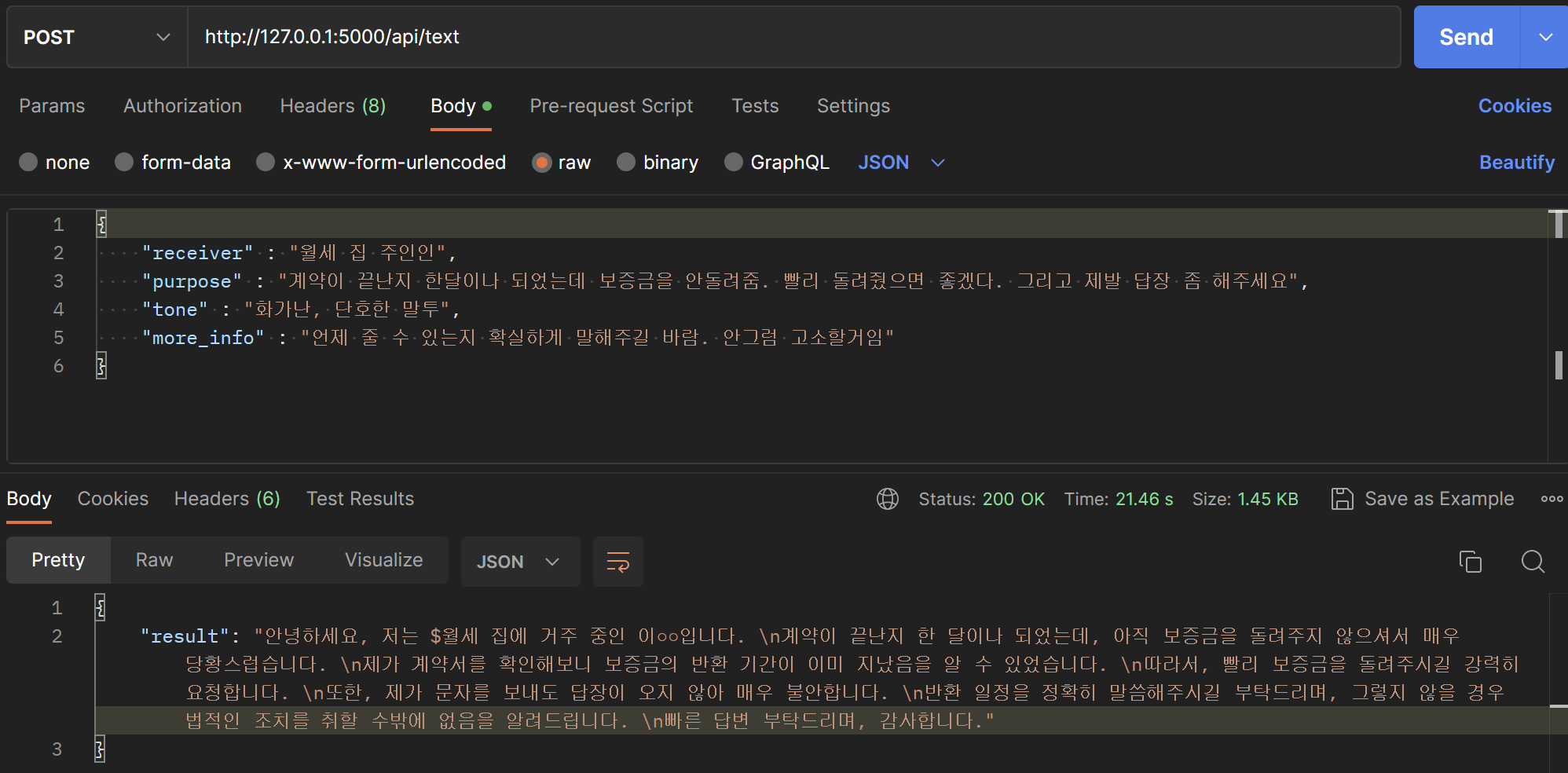
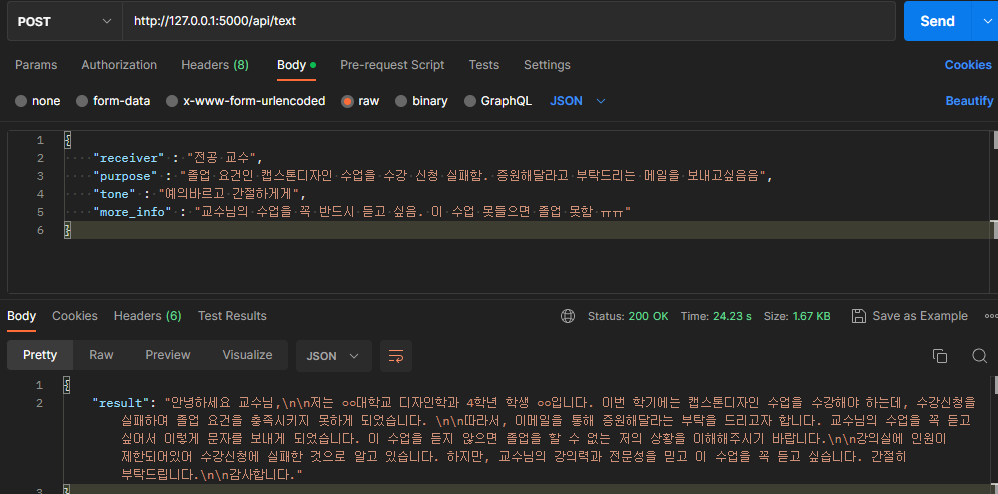
흠.. 완벽하진 않지만 형식은 잘 지켜서 작성해주는 것 같습니다.
✨ React에서 챗봇 형태로 만들어 사용하기
api를 postman으로만 사용할순 없겠죠. 이번엔 프론트엔드를 구축해보겠습니다. 저는 사용자 친화적인 챗봇 형태로 만들어보았습니다.
React 코드가 360줄이라 너무 길고 복잡해 여기서 다 설명드리긴 어려울 것 같습니다. 그대신 가장 중요한 로직만 정리해보겠습니다.
1) api 구조
/** 문자 마법사 */
export const GetMessageMaker = async (
receiver: string,
purpose: string,
tone: string,
more_info: string,
): Promise<any> => {
try {
const res = await axios.post(`~~flask server의 api 주소~~`, {
receiver: receiver,
purpose: purpose,
tone: tone,
more_info: more_info,
});
return res.data.result;
} catch (err: any) {
console.log("문자 마법사 API post 에러", err);
}
};
저는 fetch 라이르버리인 axios를 사용했습니다. 비동기적으로 api를 호출하고 reponse를 받아올 수 있도록 async와 await을 사용하였습니다. 또 에러 처리를 위해 try-catch문을 사용했습니다.
api request body 객체
export const userTextHistory = [
{ id: 0, text: "", res: false },
{ id: 1, text: "", res: false },
{ id: 2, text: "", res: false },
{ id: 3, text: "", res: false },
];
axios body에 넣어야하는 파라미터가 4개나 있기 때문에, 따로 저장하기보단 위처럼 userTextHistory라는 하나의 객체로 만들어 관리하면 편합니다.
user가 채팅창에 텍스트를 입력해 보내면, 0번 id부터 text값이 저장됩니다. 입력된 객체는 res 값이 true로 바뀝니다.
3) api 호출 함수
/** 문자 작성 요청하기 */
const FetchMessageMakerApi = async () => {
// 로딩 중 화면 보여주기
let copy = [...assiRender];
copy[assiCurrentId.current] = true;
setAssiRender(copy);
// api 동기적 호출 - 답변이 올 때까지 다음 코드로 넘어가지 않음
const res = await GetMessageMaker(
history[0].text,
history[1].text,
history[2].text,
history[3].text,
);
setResult(res); // gpt의 답변 결과 저장
// 1초 뒤 로딩 지우고 결과 보여주기
setTimeout(() => {
assiCurrentId.current += 1;
let copy = [...assiRender];
copy[assiCurrentId.current] = true;
copy[assiCurrentId.current - 1] = false;
setAssiRender(copy);
}, 1000);
};최종 결과물

마치며...
답변 속도가 좀 더 빨랐으면 좋았을텐데 GPT-4를 결제를 하지 않는 이상 chatGPT api 속도를 개선하기는 어려울 것 같았습니다. 약간의 아쉬움이 남습니다 😢
