
📌 나이브 베이즈란?
테니스를 좋아하는 사람이 있다. 만약 이 사람이 날씨가 좋고 습도가 낮은 날에 테니스를 칠 확률은 얼마일까? 과거 데이터에 따라 학습을 시킨 모델을 기반으로 어떤 날씨가 주어졌을 때 이 사람이 테니스를 칠지 안 할지 판단하는 것이다.
조건부 확률과 베이즈 정리 기반의 지도학습 분류 모델이다.
나이브(Naive)는 순진,단순하다는 뜻으로, 예측에 사용되는 특성치(x)가 상호 독립적이라는 가정 하에 확률 계산을 단순화하기 위해 나이브라고 이름이 붙여졌다.
즉, 모든 특성치 간에 서로 아무런 상관관계가 없다는 가정을 한다. 스팸 메일 탐지와 같은 텍스트 분류에 많이 활용하는 알고리즘이다.
💡 특징
- 이론적으로 쉽고 훈련과 예측 속도가 빠르다.
- 비교적 매개변수에 민감하지 않다.
- 실시간 분류 또는 텍스트 분석에 주로 사용된다.
- 특성치들 간의 독립성을 가정하기 때문에 적은 샘플로도 학습이 가능하다.
BUT, 특성치 간의 상호작용을 포착하지는 못한다.
📌 베이지안 기법
💡 조건부 확률
특정 사건이 발생했다는 가정하에 다른 사건이 발생할 확률
두 사건 A,B에 대하여 서로를 조건으로 하는 조건부 확률은 다음과 같이 정의된다.
🔹 사건 A 조건 하에 사건 B 발생 확률
🔹 사건 B 조건 하에 사건 A 발생 확률
이처럼 먼저 발생한 사건의 확률이 분모로, 두 사건이 같이 일어난 확률이 분자로 간다. 여기서 먼저 발생하는 사건의 확률이 0이어서는 안된다.
💡 베이즈 정리
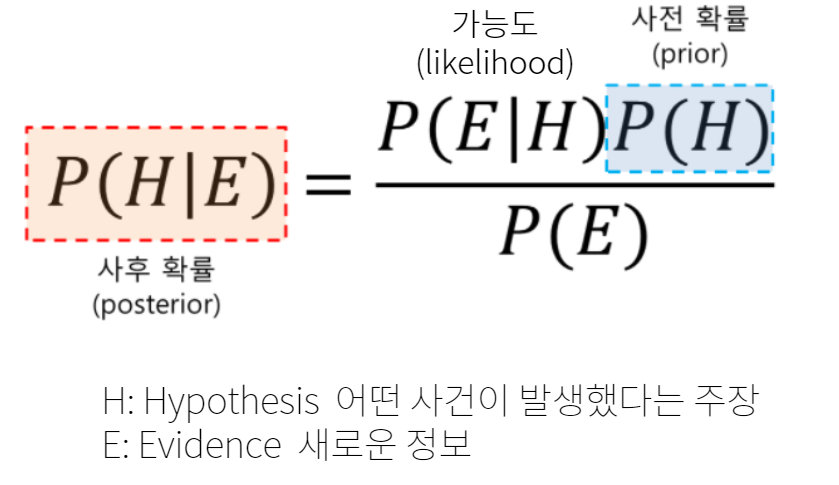
베이즈 정리는 새로운 정보를 토대로 어떤 사건이 발생했다는 주장에 대한 신뢰도를 갱신해 나가는 방법으로, 사전 확률과 조건부 확률을 토대로 사후 확률을 추론하는 과정이다.
베이지안 확률은 표본이 특정 사건에 포함된다는 주장에 대한 신뢰도를 의미한다.
| 확률 | 의미 |
|---|---|
| 사전확률(Prior) | 어떤 사건이 발생한 확률 |
| 가능도(Likelihood) | 사건이 발생했다는 가정 하에 새로운 정보가 관측될 확률 |
| 사후확률(Posterior) | 새로운 정보에 의해 갱신된 사건이 발생할 확률 |
📌 나이브 베이즈 종류
💡 가우시안 나이브 베이즈 (GaussianNB)
- 연속적인 어떤 데이터에도 적용 가능
- 매우 고차원적인 데이터셋에 많이 사용
- 특성치들이 정규분포를 따른다는 가정 하에 조건부확률을 계산
💡 베르누이 나이브 베이즈 (BernoulliNB)
- 특성치의 출현 여부 = 0과 1 이진 데이터에 적용
- 모델의 복잡도 조절하는 매개변수 alpha 존재
alpha 크면 모델이 복잡도 낮아짐
alpha에 따른 알고리즘 성능 변동은 비교적 크지 않아서 성능 향상에 크게 기여한다고는 할 수 없지만, 정확도를 높일 수는 있다.
💡 다항분포 나이브 베이즈 (MultinomialNB)
- 특성치의 개수를 활용한 분석 (예를 들면, 문장에 나타난 단어의 횟수)
- 0이 아닌 특성이 비교적 많은 데이터셋에서 베르누이보다 성능이 높다.
- 모델의 복잡도 조절하는 매개변수 alpha 존재 (베르누이와 동일)
📌 나이브 베이즈 보정
확률 연산이 불가능한 경우, 확률값을 보정한다.
💡 라플라스 스무딩 (Laplace Smoothing)
훈련에 자주 사용된 데이터가 들어온 경우에는 분류기가 잘 잘동하지만, 훈련 데이터에 없던 값이나 이상치가 들어올 경우에는 정상적인 분류를 하지 못한다. 즉, 학습 데이터에 없는 신규 데이터는 조건부 확률이 0이므로 분류하지 못하기 때문에 라플라스 스무딩 기법으로 보정하여 분류한다.
학습 데이터에 없던 데이터의 빈도수에 매개변수 alpha를 더해 특징 x에 대한 우도가 0이 될 일이 없게 만드는 것이 라플라스 스무딩이다.
하지만, 라플라스 스무딩을 적용한 후에도 분류기가 월등하게 잘 분류한다고 는 할 수 없다. 값을 보정하여 잘 분류할 가능성을 조금이라도 증가시킨다는 점에 포인트를 둬야한다.
💡 언더플로우(Underflow) 현상
조건부 확률이 너무 작아져 비교가 불가능한 현상을 말한다. 확률은 항상 0에서 1 사이의 값을 가지며, 나이브 베이즈는 모든 확률들을 곱하기 때문에 언더플로우 현상이 나타난다. 이를 방지하기 위해 값에 로그를 취하기도 한다.
