
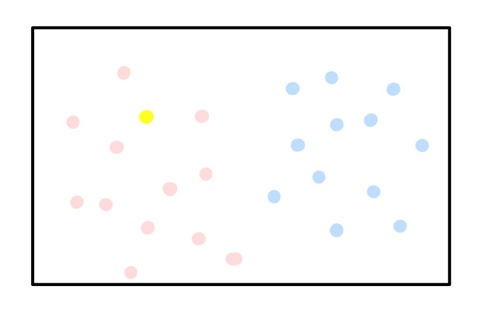
📌 노란색은 어느 집단에 속하는가?
위 그림과 같은 데이터가 주어졌을 때, 노란색 데이터는 빨간색과 파란색 집단 중 빨간색 집단에 속한다고 말할 수 있다. 노란색 주위에 가까운 데이터들이 모두 빨간색이기 때문이다.
📌 KNN이란?
위와 같이 주변의 가까운 K개의 데이터의 속성에 따라서 해당 데이터가 속할 집단을 분류하는 알고리즘을 K-최근접이웃(KNN) 알고리즘이라 한다.
KNN은 지도학습 분류 모델이며 분류와 회귀 모두 사용 가능한 비모수 방식이다.
KNN은 모델이 없다?
다른 머신러닝 알고리즘의 경우에는 학습 데이터를 가지고 훈련을 통해 모델을 생성하지만 KNN은 그대로 훈련 데이터를 가지고 있을 뿐 모델(분류기)을 생성하지는 않는다. 따라서 학습은 빠르지만 예측 시 시간이 많이 소요된다는 단점을 가진다.
새로운 데이터가 들어왔을 때, 그제서야 기존 데이터와의 거리를 구해 이웃들을 뽑는 방식이다. 기존 데이터와의 단순 비교이기 때문에 분류기가 필요 없는 모델이며 이 때문에 게으른 모델 (Laze Model)이라고도 불린다.
📌 어떻게 분류하는가?
각 데이터들 간의 거리를 측정하여 가까운 k개의 다른 데이터 레이블을 참조하여 분류한다. 여기서 거리는 일종의 유사도 라고 생각하자. 거리가 가까울수록 그 특성들이 비슷하다는 뜻이다. 데이터 간의 거리는 주로 유클라디안 거리(기본값)를 사용하여 측정한다.
🔍 유클라디안 거리 (p=2)
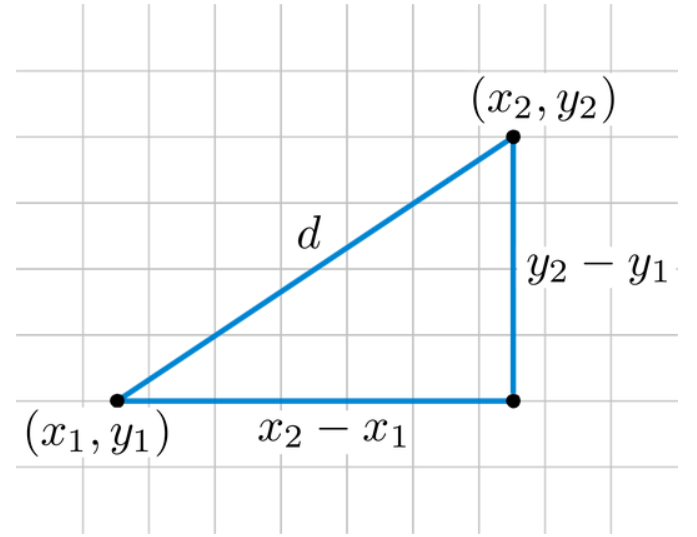
- 데이터 간 거리를 구하는 값 중 두 점 사이의 거리를 구할 때 사용하는 방법으로 피타고라스 정리를 이용한다.
- 좌표 (x1,y1) (x2,y2) 사이의 거리를 d라고 할 때 위의 수식으로 구할 수 있다. 여기서 좌표끼리의 차가 음수 값이 나올 수 있기 때문에 제곱한 후 루트를 씌웠다.
- p=1은 맨하탄 거리 지정 하이퍼파라미터이다.
🔍 특징
- 비교적 단순하기 때문에 다른 알고리즘에 비해 구현이 쉽다.
- 훈련 단계가 빠르게 수행되는 장점을 가진다.
- 간단한 알고리즘이지만 이미지 처리나 영상 속 글자나 얼굴 인식, 상품 추천 등 다양한 분야에서 응용된다.
- 특징과 클래스 간의 관계까지 파악하기에 제한적이다.
이는 각 변수와 클래스 간의 관계를 미리 파악하여 이를 알고리즘에 적용해야한다는 의미이다. - 특성간의 단위 차이에 영향을 많이 받으므로 전처리로 스케일링 작업이 필요하다.
- 특성치가 너무 많거나 대부분의 값이 0으로 구성된 데이터셋에서 성능이 나쁘다.
📌 K는 무엇인가?
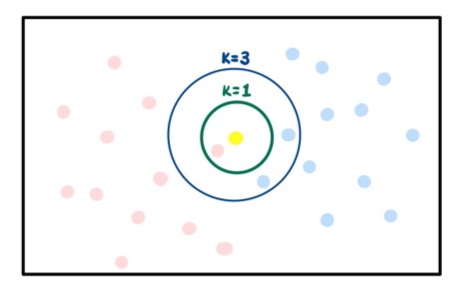
K는 이웃 수 (n_neighbors)라고도 하며, 새로운 데이터 포인트를 분류할 때 확인할 데이터의 개수를 지정하는 하이퍼 파라미터이다. K값에 따라서 분류가 달라질 수 있는데, 위의 그림은 노란색 데이터를 중심으로 k를 설정한 것이다. K=1인 경우에는 빨간색 집단으로 분류하고, K=3인 경우에는 파란색 집단으로 분류할 것이다.
최적의 K 수는 일반적으로 3~10 범위 내에서 찾으며 항상 분류가 가능하도록 홀수로 설정하는 것이 좋다. 짝수인 경우에는 두 집단의 수가 동일하게 나와 분류가 불가능한 상황이 생기기 때문이다.
계산을 이용할 때에는 데이터 수의 제곱근 값으로 정하기도 한다. 하지만 기준 변수의 수와 데이터 수에 따라 다르기 때문에 다양한 K값을 탐색해야한다.
K값이 작을수록
주변에 가장 가까운 1개의 케이스를 참조하기 때문에 더 민감하여 정교하게 분류할 것이다. 그러나 분류의 정확도가 높다고는 할 수 없다. 이 경우 학습 데이터는 매우 좋은 결과를 보이지만 테스트 데이터는 과대적합이 발생할 수 있다.
K가 클수록
주변에 많은 케이스들의 평균적인 군집과 평균값으로 분류와 예측을 하기 때문에 학습 데이터의 정확도와 성능 지표가 좋지 않고 과소적합이 발생할 수도 있다.
따라서 최적의 K 값을 찾기 위해 그리드 서치나 랜덤 서치를 적용하는 것이 적합하다.
📌 K는 어떻게 정하는가?
🔍 그리드 서치
Grid = 격자
모든 경우를 테이블로 만든 뒤 격자로 탐색한다!
하이퍼 파라미터에 넣을 수 있는 값들을 순차적으로 입력한 뒤, 가장 높은 성능을 보이는 하이퍼 파라미터를 찾는 탐색 방법
결국 가장 우수한 성능을 보이는 모델의 하이퍼 파라미터를 찾기 위해서 그리드 서치를 사용한다. 모든 경우의 수를 적용하여 가장 성능을 좋게 만드는 값을 찾기 때문에 탐색하는데 시간이 오래 걸린다.
🔍 랜덤 서치
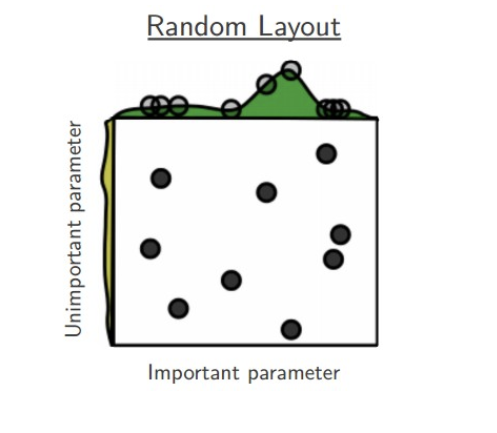
하이퍼 파라미터 값을 랜덤하게 넣어보고 그 중 우수한 값을 보인 하이퍼 파라미터를 활용하여 모델을 생성하는 방법이다. 그리드 서치보다 불필요한 탐색 횟수를 줄이기 때문에 더 효율적이라고 할 수 있다.
