
배치는 대규모 데이터 처리를 위해 주로 사용되며, 일괄 처리와 트랜잭션 관리에 매우 뛰어납니다. 그리고 스케줄러와 같이 활용하여 주기적인 작업을 자동화 하여 효율적인 프로그래밍이 가능하게 합니다.
스프링 배치의 구조
1. Job
Job은 스프링 배치의 가장 상위 개념이며, 전체의 흐름을 정의합니다.
하나 이상의 Step으로 구성되어 사용자가 맞춰 일괄 처리를 진행할 수 있죠.
2. Step
Step은 Job의 하위 개념으로 하나의 작업을 맡습니다. 각각의 Step에는
Reader, Processor, Writer로 구성됩니다. 각 Step은 이전 Step 결과에 의존할 수 있습니다.
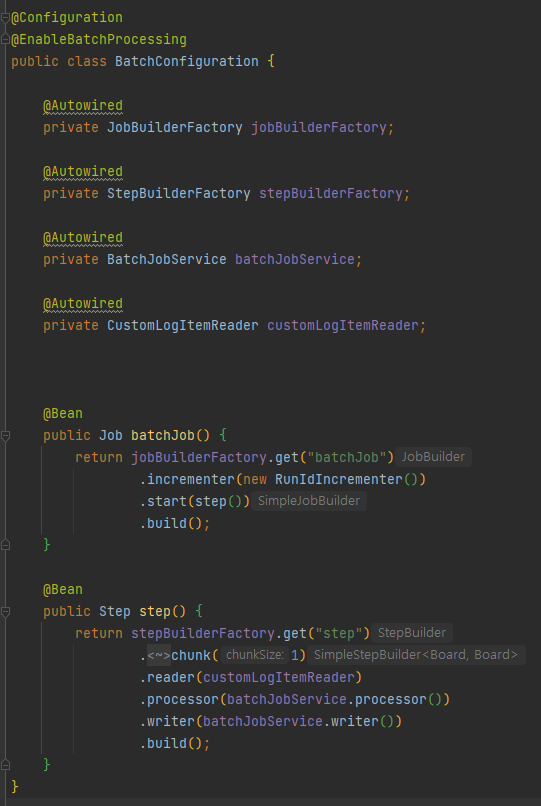
BatchConfig를 통해 Job과 Step을 정의
3. ItemReader
ItemReader는 말 그대로 파일이나 데이터를 읽고 처리하는 파이프라인 작업을 수행합니다. DB에 데이터를 저장하거나 여러 가지 일을 수행할 수 있습니다.
4. ItemProcessor
ItemProcessor는 읽어온 데이터를 가공하거나 변환하는 역할
필수는 아님. 쓰는 이유는 주로 비즈니스 로직을 분리하기 위해.
필터를 사용하여 데이터를 넘길지 체크함 예를 들어? Board 객체의
id에 admin이 포함된다던가? no가 짝/홀 이라던가를 구분해서 필터링을 할 수 있다.
5. ItemWriter
Reader에서 처리한 데이터를 데이터베이스, 파일, 메시지, 큐 등 다양한 대상에게 쓸 수 있도록 할 수 있습니다.
6. JobRepository
실행 중인 Job 및 Step의 상태 정보를 관리하고 저장하는 역할
스프링 배치의 내부 저장소, 실패한 작업을 롤백 / 재시작 할 수 있음
7. JobLauncher
Job을 실행하는 역할. Job 실행에 필요한 매개변수 설정할 수 있다.
8. Listeners
JobExecutionListener, Step, ItemWriteListener 등
작업의 진행 상황에 맞춰 모니터링 및 이벤트를 처리할 수 있습니다.
9. Chunk
Step에서 한번에 처리되는 데이터의 크기를 정의하는 단위입니다.
청크 지향 처리는 대용량 데이터를 작은 덩어리로 나누어 처리하여 메모리 사용량을 최적화하는데 큰 도움을 줍니다.
저는 파일 1개에 객체가 1개 저장되어있기 때문에, 청크를 1로 주었습니다.
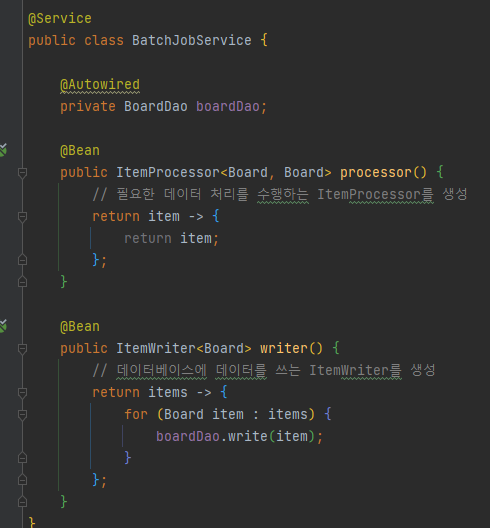
프로세서의 경우 다른 데이터 처리 로직이 없고, writer의 경우 boardDao의 write 메소드를 통해 데이터베이스에 데이터를 쓰도록 하였습니다.
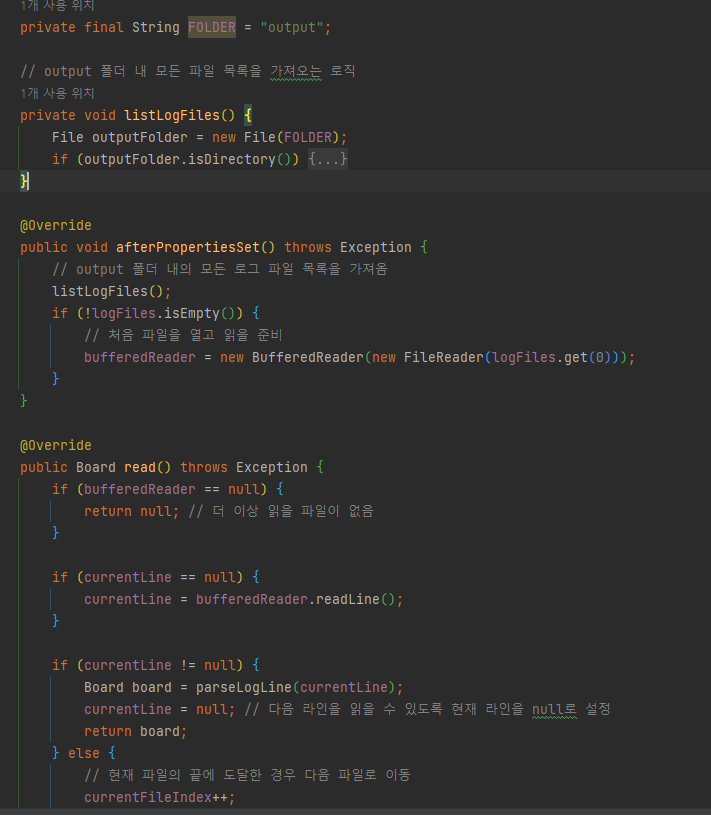
여러 개의 파일을 읽기 위한 ItemReader()

ItemReader의 경우 저는 따로 CustomItemReader()을 통해
FOLDER에 있는 여러 개의 파일을 읽어들이도록 하였습니다.
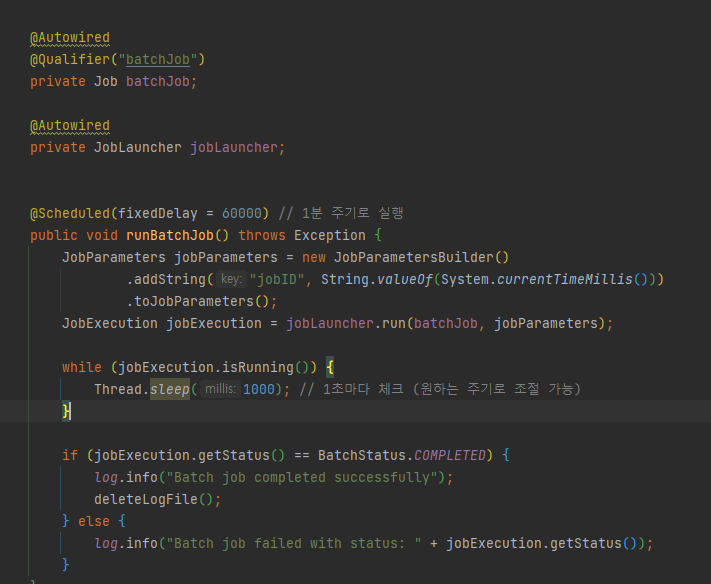
마지막으로 JobLauncher을 통해 Job을 실행하였습니다.
아직은 부족하게 사용하여 배치의 여러가지 기능에 접근하지 못했지만,
좀 더 익숙해지면 매우 유용하게 사용할 수 있을 것 같습니다.
다음은 곧 사용하게 될 젠킨스에 대해서 알아보겠습니다.
