
인덱스(Index)
인덱스(Index)는 데이터베이스에서 데이터 검색 속도를 향상시키기 위해 사용되는 데이터 구조입니다. 인덱스는 테이블의 컬럼 또는 컬럼의 조합에 대한 키(key)와 해당 키가 가리키는 행(row)의 위치 정보를 저장합니다.
일반적으로 인덱스는 B-트리(B-Tree)나 B+트리(B+Tree)와 같은 트리 기반의 자료구조를 사용하여 구현됩니다. 인덱스를 사용하면 데이터베이스에서 특정 데이터를 검색할 때 전체 테이블을 스캔하는 것이 아니라, 인덱스를 사용하여 검색 대상 데이터의 위치를 빠르게 찾아낼 수 있습니다. 이를 통해 데이터 검색 속도를 크게 향상시킬 수 있습니다.
하지만 인덱스를 사용하면 인덱스를 생성하는 비용과 유지하는 비용이 추가로 발생하므로, 인덱스를 어떤 컬럼에 생성할 것인지, 인덱스를 몇 개 생성할 것인지 등을 결정하는 것은 신중히 고려해야 합니다. 또한, 인덱스를 과도하게 사용하면 오히려 성능이 저하될 수도 있으므로 적절한 인덱스 사용이 중요합니다.
explain SELECT createdDate, memberId, count(id)
FROM post
WHERE memberId = 3 and createdDate between '2023-01-01' and '2024-01-01'
GROUP BY memberId, createdDate;- MySQL에서는 쿼리 실행 계획을 분석하는 기능인
EXPLAIN을 제공합니다.EXPLAIN을 사용하면 쿼리의 실행 계획을 확인할 수 있어, 쿼리의 성능을 분석하거나 쿼리를 최적화할 때 유용하게 사용할 수 있습니다. EXPLAIN결과는SELECT문이 실행될 때 MySQL이 사용하는 인덱스, 테이블, 조인 등의 정보를 출력합니다. 이 정보를 기반으로 쿼리를 최적화할 수 있습니다. 예를 들어, 실행 계획에서 인덱스가 사용되지 않고 있는 경우, 해당 컬럼에 인덱스를 추가하여 쿼리 성능을 향상시킬 수 있습니다.
B+Tree
B+트리는 여러 개의 데이터를 노드로 구성된 트리 형태로 저장되면, 탐색과 삽입, 삭제 수정등의 작업을 빠르게 수행할 수 있습니다.
B+트리는 이진 검색 트리(BST)와 달리, 하나의 노드에 여러 개의 데이터를 저장할 수 있습니다.
B+트리의 각 노드 특징
- 노드의 크기가 일정하다.
- 각 노드에는 키와 해당 키에 대응하는 데이터의 포인터가 저장된다.
- 리프 노드에는 키와 데이터의 포인터가 모두 저장된다.
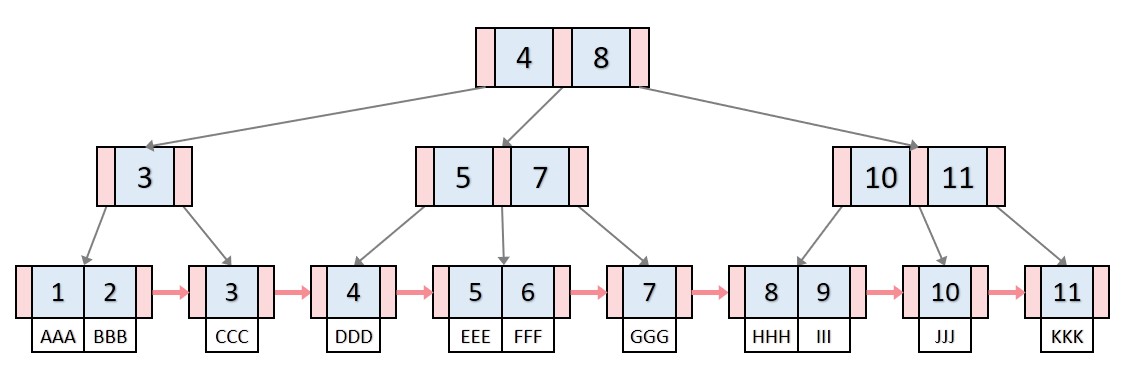
B+트리는 루트 노드에서 시작하여 하위 노드로 이동하면서 데이터를 탐색합니다. 각 노드는 일정한 범위의 키를 가지고 있으며, 자식 노드는 해당 범위보다 큰 키를 가지고 있습니다. 리프 노드에서는 키와 함께 데이터의 포인터가 저장됩니다.
B+트리는 삽입과 삭제가 발생할 때마다 균형을 유지하기 위해 리밸런싱 작업을 수행해야 합니다. 이러한 작업은 일반적으로 자동으로 수행되며, B+트리는 균형 잡힌 트리이므로 검색, 삽입, 삭제 등의 작업이 모두 O(log n)의 시간 복잡도로 수행됩니다.
인덱스(index)의 관리 이슈
DBMS는 index를 항상 최신의 정렬된 상태로 유지해야 원하는 값을 빠르게 탐색할 수 있다. 그렇기 때문에 인덱스가 적용된 컬럼에 INSERT, UPDATE, DELETE가 수행된다면 각각 다음과 같은 연산을 추가적으로 해주어야 하며 그에 따른 오버헤드가 발생한다.
INSERT: 인덱스를 생성할 때는 데이터베이스의 스키마를 변경해야 하므로 비용이 발생합니다. 따라서 인덱스를 생성할 때는 해당 테이블이 자주 변경되지 않을 것으로 예상되는 경우에만 생성하는 것이 좋습니다.UPDATE: 데이터를 추가, 수정, 삭제할 때는 해당 데이터에 대한 인덱스도 함께 업데이트되어야 합니다. 이 때 업데이트 비용이 발생하므로, 대량의 데이터를 추가, 수정, 삭제하는 경우에는 인덱스를 임시적으로 비활성화하는 것이 성능상 이점이 있을 수 있습니다.인덱스 fragmentation:인덱스는 데이터베이스의 검색 성능을 향상시키기 위해 사용되지만, 데이터를 추가, 수정, 삭제하는 경우에는 인덱스의 조각화(fragmnetation)가 발생할 수 있습니다. 이러한 조각화는 검색 성능을 저하시키므로 주기적으로 인덱스를 재구성하거나 재조직하는 것이 좋습니다.인덱스 deadlock: 인덱스를 사용하는 쿼리와 데이터를 추가, 수정, 삭제하는 쿼리가 동시에 실행될 때 데드락(deadlock)이 발생할 수 있습니다. 이러한 문제를 해결하기 위해서는 트랜잭션 격리 수준을 조정하거나 인덱스에 대한 락(lock)을 최소화하는 방법을 고민해야 합니다.
인덱스를 사용하는 경우에는 위와 같은 이슈를 고려하여 적절한 인덱스 설계와 관리를 해야 합니다. 또한, 대량의 데이터를 추가, 수정, 삭제하는 경우에는 인덱스를 임시적으로 비활성화하거나, 인덱스를 먼저 삭제한 후 데이터를 처리한 후에 다시 인덱스를 생성하는 방법도 고려할 수 있습니다.
인덱스(index)의 장점과 단점
데이터베이스의 성능을 향상시키는 데 큰 도움이 되지만, 잘못된 인덱스 설계나 관리는 오히려 성능을 저하시킬 수 있으므로 주의해야 합니다.
장점
- 빠른 검색 성능: 인덱스를 사용하면 데이터베이스에서 원하는 데이터를 빠르게 검색할 수 있습니다. 인덱스가 없는 경우에는 모든 레코드를 스캔해야 하지만, 인덱스가 있다면 인덱스를 검색하여 레코드를 빠르게 찾을 수 있습니다.
- 높은 처리 성능: 인덱스를 사용하면 데이터를 추가, 수정, 삭제할 때도 빠른 처리 성능을 보장할 수 있습니다. 인덱스가 잘 설계되어 있다면 데이터를 검색하고 수정하는 데 필요한 시간을 크게 줄일 수 있습니다.
- 데이터 중복 최소화: 인덱스는 데이터를 중복으로 저장하지 않기 때문에 데이터베이스의 저장 공간을 절약할 수 있습니다. 또한, 중복된 데이터를 최소화하면 데이터 일관성과 정확성을 유지할 수 있습니다.
단점
- 인덱스 생성 시 추가 비용 발생: 인덱스를 생성할 때는 추가적인 비용이 발생합니다. 인덱스를 생성하는 데 필요한 시간과 저장 공간이 추가로 필요하기 때문입니다.
- 데이터 삽입, 수정, 삭제 시 더 많은 비용 발생: 인덱스가 있는 테이블에 데이터를 삽입, 수정, 삭제할 때는 추가적인 비용이 발생합니다. 이는 인덱스를 업데이트하기 위해 더 많은 작업이 필요하기 때문입니다.
- 인덱스 설계 오류: 인덱스를 잘못 설계하면 데이터베이스 성능에 부정적인 영향을 미칠 수 있습니다. 잘못된 인덱스 설계로 인해 검색 성능이 저하되거나 데이터 일관성이 깨질 수 있습니다.
인덱스 사용 주의사항
- 인덱스 필드 가공
SELECT * FROM Member WHERE age * 10 = 10이면 age 필드에 가공이 들어갔으므로 인덱스를 사용할 수 없다.SELECT * FROM Member WHERE age = '1'이면 age 필드의 값을 문자열로 가공하여 검색하게 되므로 인덱스를 사용할 수 없다.
- 복합 인덱스
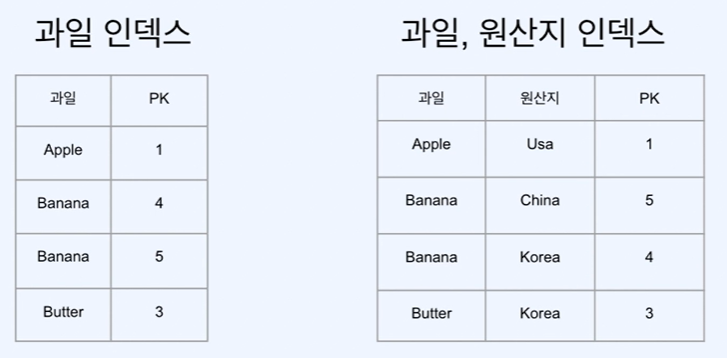
 오른쪽 그림은 과일, 원산지 두개의 복합 인덱스를 사용한 예제이다. 데이터는 먼저 1번 인덱스 과일에 대하여 정렬되고 과일이 같다면 원산지에 대하여 정렬된다.
오른쪽 그림은 과일, 원산지 두개의 복합 인덱스를 사용한 예제이다. 데이터는 먼저 1번 인덱스 과일에 대하여 정렬되고 과일이 같다면 원산지에 대하여 정렬된다.- 만일,
WHERE절에서 원산지에 대하여 검색하면 MySQL은 먼저 과일 컬럼을 보게되고 검색하는 자료가 없으므로null로 반환하게 된다. - 검색시 과일 혹은 과일, 원산지에 대하여 검색하여야 한다.
- 만일,
- 하나의 쿼리에는 하나의 인덱스만
WHERE절에 여러개의 조건을 넣더라도 하나의 인덱스만 사용하게 된다. 따라서WHERE,ORDER BY,GROUP BY를 사용할 경우 인덱스를 잘 확인해야 한다.
- 의도대로 인덱스가 동작하지 않을 수 있으므로
explain으로 확인하는 것이 좋다. - 인덱스도 비용이다. 쓰기를 희생하여 조회를 얻는 것이므로
클러스터 인덱스
- 클러스터 인덱스는 데이터 위치를 결정하는 키 값이다.
- 클러스터 키 순서에 따라서 데이터 저장 위치가 변경 된다.
- 클러스터 키 삽입/갱신시에 성능 이슈 발생
- 클러스터 키 순서에 따라서 데이터 저장 위치가 변경 된다.
- MySQL의 PK는 클러스터 인덱스이다.
- PK 순서에 따라서 데이터 저장 위치가 변경된다.
- PK 키 삽입/갱신시에 성능 이슈 발생
- PK 순서에 따라서 데이터 저장 위치가 변경된다.
- MySQL에서 PK를 제외한 모든 인덱스는 PK를 가지고 있다.
- 세컨더리 인덱스만으로는 데이터를 찾아갈 수 없다.
- PK 인덱스를 항상 검색해야함
- 세컨더리 인덱스만으로는 데이터를 찾아갈 수 없다.
클러스터 인덱스를 이용한 데이터 검색
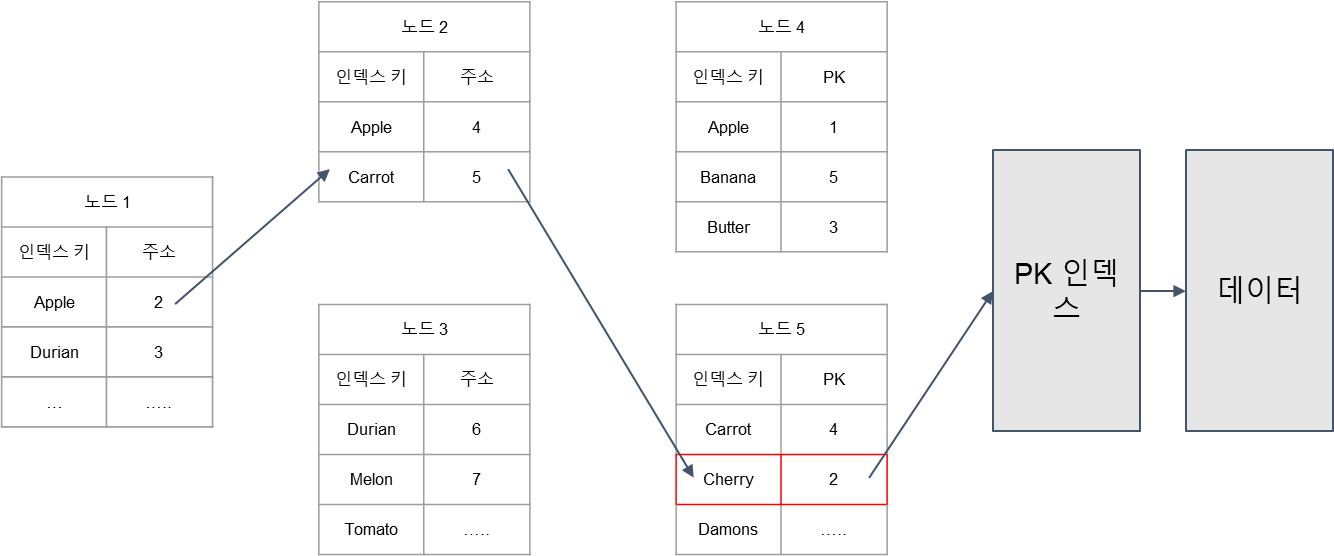
클러스터 인덱스는 데이터 위치를 결정하는 키 값이다. 위에서는 Cherry라는 데이터를 찾으려고 한다.
인덱스 키는 정렬되어 있는 상태이다. 또한 세컨더리 인덱스만으로는 데이터를 찾을 수 없으므로 PK 인덱스을 검색해야만 한다.
- Apple과 Durian중 Apple을 선택하고 Apple이 가르키는 노드 위치 2로 이동
- Apple과 Carrot중 Carrot을 선택하고 Carrot이 가르키는 노드 위치 5로 이동
- Cherry를 발견하고 PK 2번의 PK 인덱스 테이블로 이동
- 인덱스 테이블에서 Cherry 데이터 확인
클러스터 인덱스 장점
- PK를 활용한 검색이 빠름. 특히 범위 검색!
- 세컨더리 인덱스들이 PK를 가지고 있어 커버링이 유리
