[Dream to Control] 용어 정리
아래의 링크를 통해 공부하고, 때로는 그대로 옮겨 적었습니다. 아래의 작가님들에게 무한한 감사를 드립니다! 🙇🏼♂️
지능적인 에이전트(artificial agent)
자신의 감각기관 (sensor)을 통해 환경 (environments)를 인지 (percept) 하여 작용기 (effectors)를 통해 그 환경에 반응 (action)하는 시스템을 말한다.
- agent는 사용자를 대신해 사용자가 원하는 작업을 자동적으로 해결하는 자율적 프로세스로서 주로 분산환경에서 동작하며 자신만의 일을 수행할 수 있는 독립된 기능을 가진 하나의 소프트웨어 시스템이다.
- agent는 독립된 기능을 수행하기 위해 지식 (knowledge)이라는 비절차적 처리 정보 (non-procedural process information)가 저장된 데이터베이스를 이용하여 자신의 추론 방법을 통해 다른 agent와 상호작용 한다.
- 또한 경험을 바탕으로 한 학습 기능 및 목적 지향적 능력을 가지고 지속적인 행동을 한다.
Model-Based vs Model-Free
RL 알고리즘 선택지 간에 가장 중요한 분기점은 'Agent 가 환경(Environment)에 대해 알고있는지'이다. 여기서 환경을 안다는 것은 상태 변화와 보상을 예측할 수 있다는 것이다.
환경을 알 때의 장점은
- 에이전트가 어떤 액션을 하면 어떤 일이 일어날지를 미리 예측하고 그중 나은 것을 결정할 수 있다는 것이다.
- 에이전트는 이처럼 미리 계획한 것을 학습된 정책으로 옮길 수 있다.
- 이렇게 하면 (환경)모델을 모를때 쓰는 방법 보다 Sample Efficiency를 크게 향상 시킬 수 있다.
*sample efficiency: Sample Efficiency denotes the amount of experience that an agent/algorithm needs to generate in an environment (e.g. the number of actions it takes and number of resulting states + rewards it observes) during training in order to reach a certain level of performance
모델을 쓰는 알고리즘을 Model-Based 방식, 모델을 쓰지 않는 알고리즘을 Model-Free방식이라고 한다.
환경과 상호작용
마르코프 결정 과정 (Markov Decision Process)
강화학습 문제를 수학적으로 공식화하는 가장 일반적인 방법
- 에이전트는 환경에서 특정한 행동을 취할 수 있음
- 이러한 행동은 때로 보상으로 이어짐
- 행동은 환경을 변화시키고 에이전트가 다른 행동을 취할 수 있는 새로운 상태로 만듬
- 이러한 행동을 선택하는 방법에 대한 규칙을 정책 (policy)이라고 함
마르코프 결정 과정은 상태의 행동과 집합, 한 상태에서 다른 상태로 전이하는 규칙과 보상으로 구성
그리고 다음 상태의 확률은 오직 현재의 상태와 행동에만 영향을 받고, 이전의 상태와 행동에는 영향을 받지 않음
차감된 미래와 보상 (Discounted Future Reward)
에이전트가 오랫동안 잘 동작하게 하려면 즉각적인 보상뿐만 아니라 미래의 보상도 고려
큐러닝 (Q-learning)
주어진 상태에서 동작을 수행할 때 차감된 미래의 보상을 나타내는 큐함수 (Q-function)를 정의합니다.
큐함수는 '주어진 상태에서 행동을 수행한 후 게임이 끝날 때 가능한 최고의 점수'를 의미합니다.
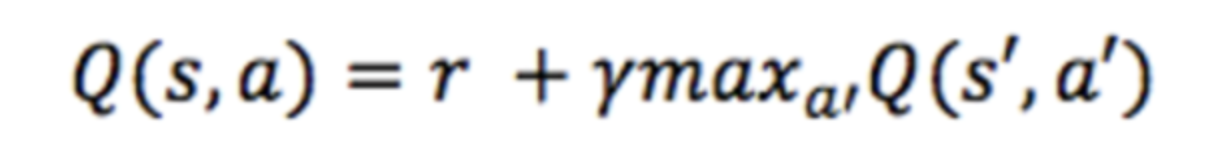
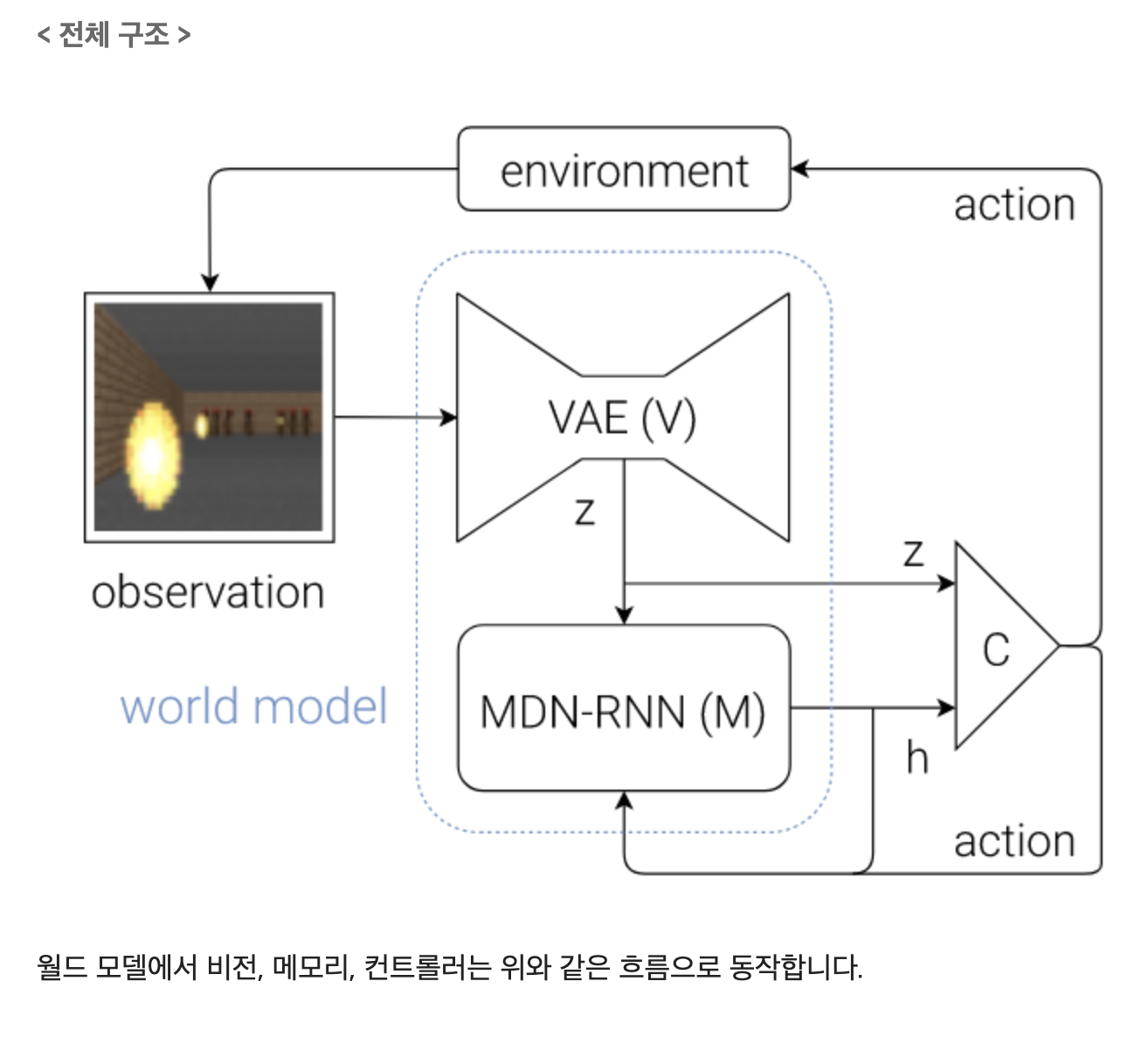
월드 모델 World Model
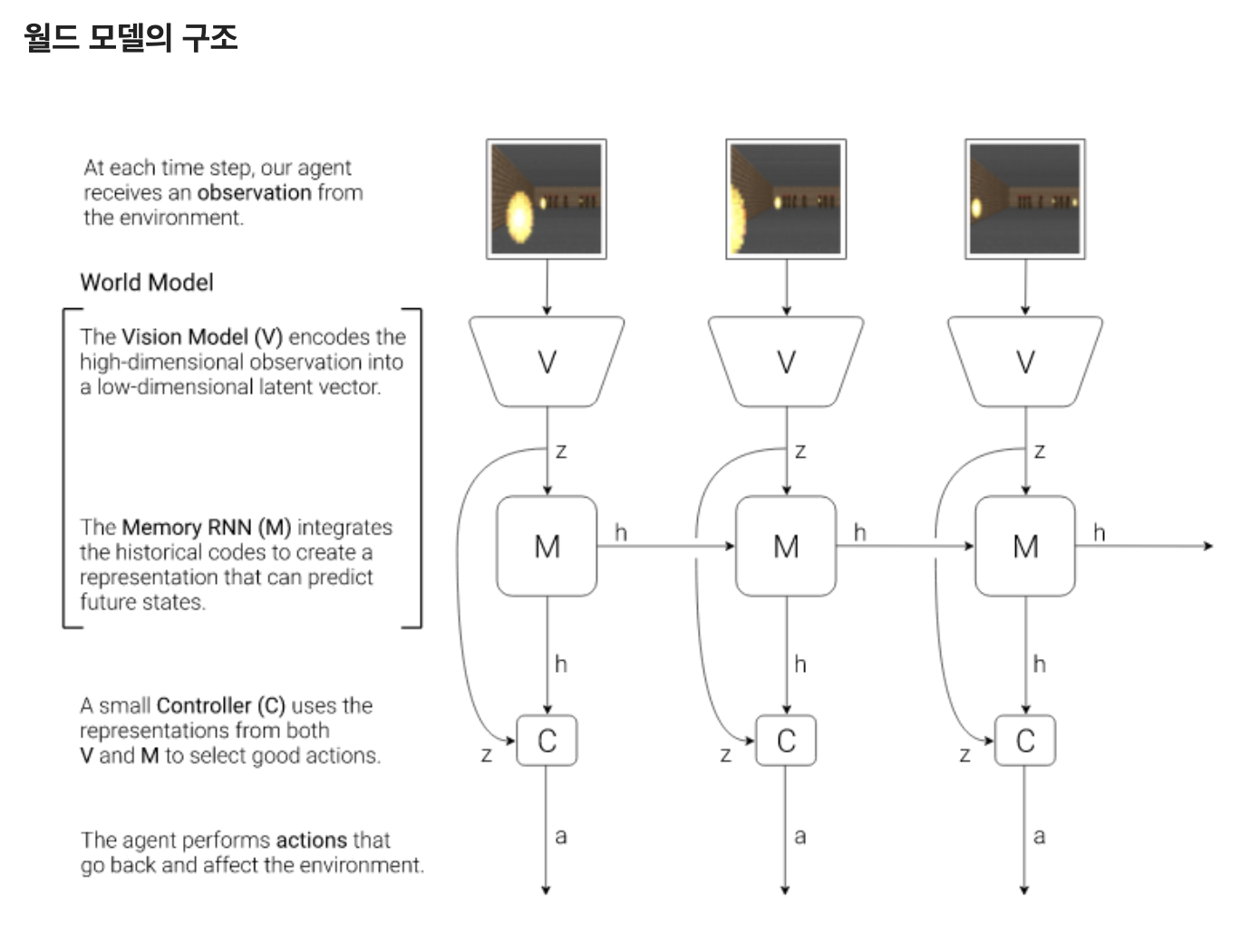
월드모델은 위의 그림과 같이 비전, 메모리, 컨트롤러의 세 부분으로 이루어져 있습니다. 비전은 화면인식, 메모리는 기억 및 예측, 컨트롤러는 행동 및 학습을 수행합니다.
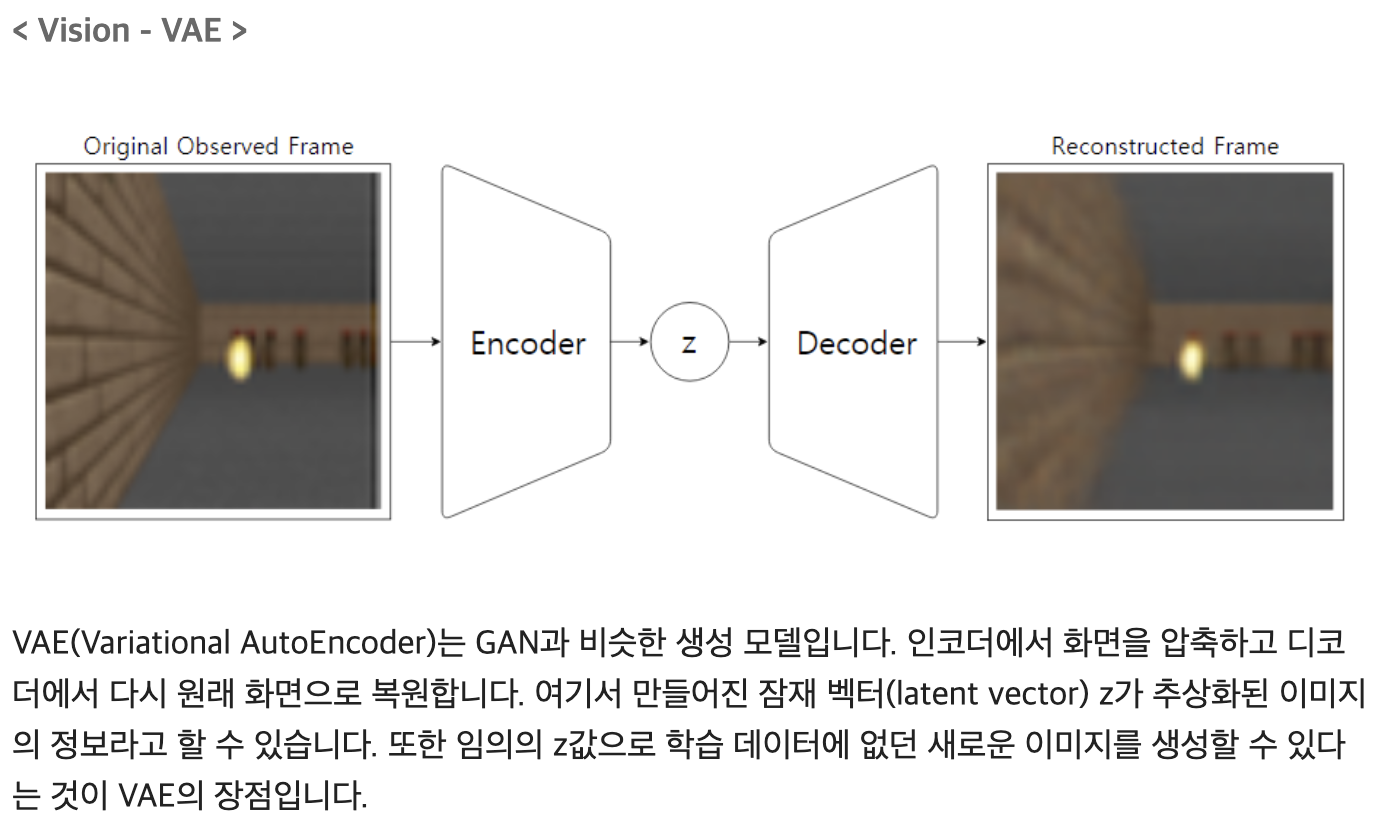
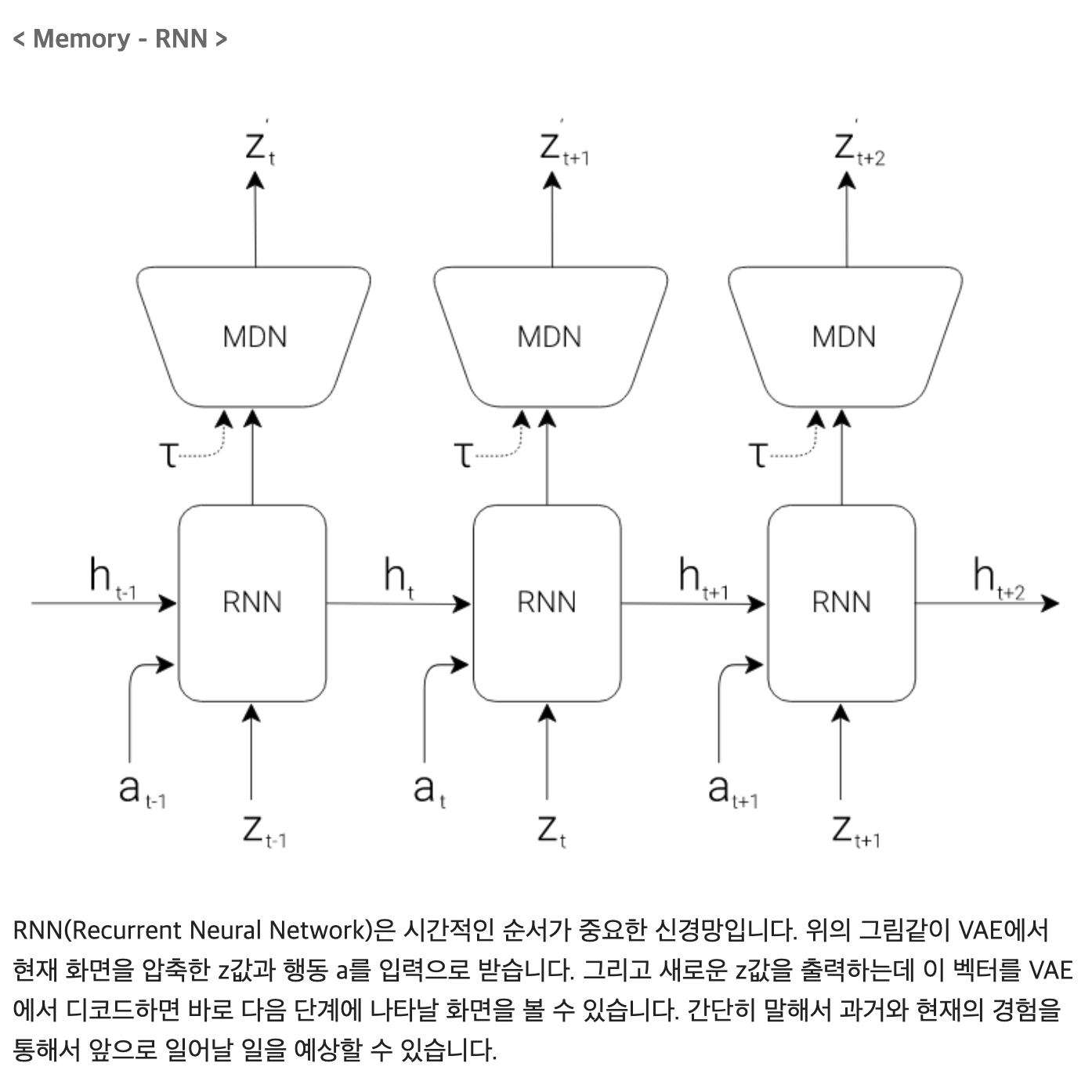

역전파 Backpropagation
계산 결과와 정답의 오차를 구해 이 오차에 관여하는 값들의 가증치를 수정하여 오차가 작아지는 방향으로 일정 횟수를 반복해 수정하는 방법이다. 오차역전파 또는 오류역전파라고도 불린다. 반대말은 순전파이다.
특징
- 학습 중인 작업을 수행할 수 있을 때까지 네트워크를 개선하기 위해 가중치 업데이트를 계산하는 반복적이고 재귀적이며 효율적인 방법이다.
- 역전파는 네트워크 설계 시 활성화 함수의 파생물을 알아야 한다. 자동 미분은 파생물을 훈련 알고리즘에 자동 및 분석적으로 제공할 수 있는 기술이다.

