supervised learning 관점에서 RL 이 갖는 문제점
1. labelled data 가 아닌 scalar reward로부터 학습해야 함
그런데 이 데이터가 input과 output 사이에 긴 timestep이 있을수도 있음
- deep learning에서는 training data 간 iid를 가정하지만 RL의 state 들은 그렇지 않음
이를 해결하기 위해 논문은 CNN을 통한 control policy 학습 방식을 제안함
네트워크는 Q-learning 알고리즘과 SGD 방식으로 weight를 업데이트 했음
2번의 iid 문제를 해결하기 위해 experience replay mechanism (previous transition을 random하게 sample 하는 방식)을 사용함
목표 : 최대한 많은 게임을 스스로 배울 수 있는 하나의 single NN를 구성하는 것
background
agent는 internal state를 알 수 없고 d-dimension의 image 와 reward 를 받는다.
optimal action value function 는 state s에서 action a를 취했을 때 얻을 수 있는 최대 expected return을 의미한다.
위의 함수는 Bellman equation을 따르며 next state 가 s'인 경우 expected value를 최대로 만드는 a'를 구하는 것이 목적이라고 할 수 있을 것이다.
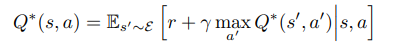
실제 알고리즘 상 구현에서는 좌변의 Q가 i+1 번째 value function이고 우변의 Q가 i번째 value function인 것처럼 iterate 한다 (이러한 방식으로 얻은 Q는 optimal 에 수렴함을 보장할 수 있다.)
하지만 현실에서는 위와 같은 방식은 모든 sequence에 대해 각각 Q를 estimate 하기 때문에 성능을 보이지 않으며 아래와 같이 function approximator 를 사용하는 편이 기능적으로 유리하다
Q(s,a;
식(2)에서 식(3)로 넘어가는 경우 에 대해 gradient를 계산하게 되는데 에 해당하는 항에 속해있는 는 i-1번째 iteration의 freezed 된 parameter 이므로 미분대상이 아니며 미분결과 나와야 할 거 같은 계수 -2는 learning rate 안으로 통합되는 것과 같이 이해하여 식(3)을 얻을 수 있다.
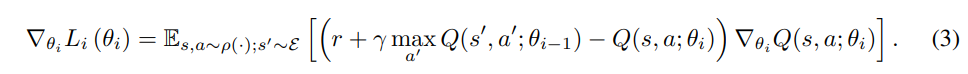
위의 식에서 전체 expectation을 구하는 것 보다는 single sample을 통해 update 하는 stochastic gradient descent 방식을 이용한다.
chapter 5의 value function and SGD 절을 참고하자
이 알고리즘은 model-free + off-policy 이다
1. model -free
에뮬레이터에서 얻은 sample을 통해 RL 을 학습
2. off-policy
use (behaviour policy) to evalute (target policy)
chapter 4에 나온 Q learning control 처럼 학습이 되는 target policy는 Q 함수에 대해 greedy 한 것이고 학습의 재료가 되는 behaviour policy는 이미 배운 것과 같은 방식을 따르는 다른 policy 들이기 때문이다
Pytorch 구현에서도 위에서 로 표현된 (target policy)와 로 표현된 behaviour policy를 구현하기 위해 target_net 과 policy_net 두가지 Neural Network를 생성하고 time - step이 for 문에서 모두 돌 때마다 target_net = policy_net 과 같은 형태로 업데이트를 진행한다.
3장 Related work (TD gammon)
4장 Deep RL
SGD 를 통해 vision과 speech 분야에서 feature 정보를 학습할 수 있었던 점을 motivation으로 삼아 RL에 deep learning을 적용하게 된다.
(RL+Deep Neural Network)
TD gammon의 경우 algorithm이 environment와 interaction을 통해 직접 얻은 정보를 통해 학습하는 on-policy 학습 방법을 이용한다.
하지만, DQN이 TD gammon과 차별되는 점은 experience-replay 라는 개념이다.
Experience Replay는 each time-step에서 agent의 experience를 모두 replay memory D에 저장하고 이러한 집합에서 임의로 뽑은 sample에 대해 Q learning을 진행한다.
이후 Agent는 방식에 의해 action을 고르게 된다
(random pool에서 고르는데 여기서 고른 action은 언제 쓰이는지?)
임의 길이의 history 목록은 Neural Network의 input으로 들어가기 까다로운 면이 있으므로 함수에 의해 만들어진 history에 대한 fixed length representation 을 input으로 사용한다.
알고리즘은 아래와 같다

1. M개의 episode에 대해 반복한다.
2. 각 time step에 대해 방식으로 random action을 고른 후, 이 action을 에뮬레이터에 넣어 얻은 값을 함수 를 이용해 fixed length representation 한다.
3. processed 된 정보들을 memory 집합 D에 넣고 D에서 random sample을 뽑아 식(3)에서 했던 과정처럼 gradient descent를 진행
정리) 위의 과정은 D에 들어갈 학습 소스를 만드는 과정으로 이해하고 아래는 off-policy Q-Learning으로 이해하도록 한다.
기존 방식(On-Line Q Learning)과 비교한 장점
1. greater data efficiency
각 step이 더 많은 weight update 과정에서 사용된다
2. random sample 추출은 학습 재료간 correlation을 줄여 variance를 낮춘다.
3. on-policy 방식에서는 current parameter들이 다음 training의 재료로 쓰일 data sample을 정하기 때문에 좋지 않은 local minimum이나 diverge 할 경향이 있다.
Pre-processing details
color input은 gray-scale로 변환되었으며 down-sampled 되었다.
2D convolution 에 넣기위해 직사각형의 down-sampled input은 84x84로 다시 cropped 되었다
위에서 제시된 function 는 마지막 4 frame에 대해 위의 down sample 과정을 거쳐 Q의 input이 되도록 한다.
Q 함수를 Neural Network에 대해 parameterise 하는 방법
기존의 방식은 Network에 input으로 state와 action 에 대한 정보를 주었지만 이는 각 action에 대해 따로 forward pass를 구해야 한다는 computation 단점이 존재한다.
대안으로 여기서는 input으로 state 만을 주지만 가능한 action 에 대해 각각의 output unit을 부여하고
output은 state에 대해 individual action 이 갖는 Q 값에 각각 대응하다고 설명되어있다.
(output으로 [, , , , , ,]) 같이 주어지면 각 원소가 action의 Q 값에 대응된다는 소리로 이해했음)
이 방식은 하나의 forward pass로 가능한 모든 action에 대해 Q 값을 모두 계산할 수 있다는 기존 방식의 보완이 된다
