- 전전장: experience 를 통해 value function을 배움
- 전장: experience를 통해 policy를 배움
- 이번 장: experience를 통해 model을 배움
(Lecture 5 까지 ; experience로부터 value function을 학습
Leture 6 ; experience로부터 policy를 학습
Lecture 7; experience로부터 model을 학습
)
Model based RL
-
experience를 통해 model을 배우고 그 model을 통해 value function을 plan 한다.
-
plan 이란 : lookahead와 비슷하다고 할 수 있으며 model을 사용하여 어떤 일이 일어날지 예측하고 이로부터 value function을 construct 한다. // 이 방식에서 tree-search 방식이 적용됨
-
model build 과정에는 state transition과 reward에 대한 정보가 필요하다
-
장점
- supervised learning을 하기 용이 하다; 현재 state과 다음 state를 각각 input과 output으로 잡은 supervised learning
- Model uncertainty 에 대해 reason about 이 가능함
https://stackoverflow.com/questions/18666821/what-does-the-term-reason-about-mean-in-computer-science
(reason about이 무엇인지는 위 링크 참조)
- 단점
Model을 배우는 것, value function을 만드는 과정에서 모두 error가 발생할 수 있음
What is Model
-
로 parameterised 된 state transition과 reward 함수를 의미하며 보통 state transition과 reward는 독립적인 것으로 판단한다.

-
아래와 같은 input, output 쌍에 대해 Model을 배우는 과정은 supervised Learning으로 치환할 수 있으며 input (s,a)에 대해 output 중 reward를 예측하는 것은 regression, state를 예측하는 것은 density estimation 이라 볼 수 있다.

density estimation problem 이란: set of given data points에 대해 output probability density function을 배우는 문제를 의미한다.
또한 density estimation problem은 stochastic 한 성질을 배운다는 점을 알아놓도록 하자 -
model은 아래와 같이 다양한 종류가 있고 table look-up model은 한 예시가 될 수 있다.

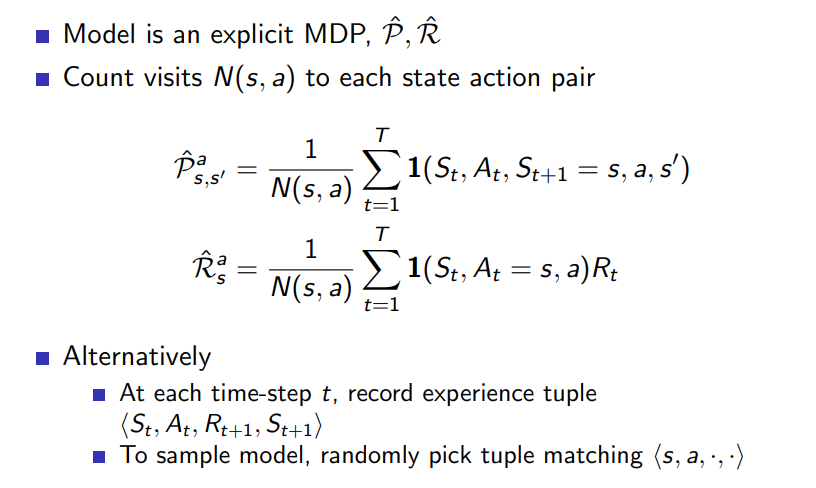
N은 전체 visit의 수를 의미하며 각각의 조건을 만족할 때마다 1을 더해 원하는 값을 얻는다
혹은 이미 실행된 episode에 대해 각 time step에서 랜덤하게 input 튜플을 만족하는 데이터를 선정하는 방법도 있다.
Planning a Model
-
sample based planning
model은 sample을 만드는데 주로 활용되고 여기서 얻은 sample로 Model-free RL을 진행한다.
이 방식의 장점은 작은 real experience로 우선 model을 만들고 난 이후에는 원하는 만큼의 experience를 뽑아낼 수 있다는 점이다.

-
inaccurate model을 사용할 경우 model-based RL이 갖는 최고 성능은 inaccurate model의 그것에 수렴한다
이를 해결하기 위해서는 model-free RL을 사용하거나 model uncertainty에 대해 reason about 해야 한다
Integrated Architectures
-
Integrated Architecture란 model-free 와 model-based RL의 장점을 모두 취하려는 방식을 의미한다.
-
Dyna는 generated 된 model로부터 value function을 planning 하기도 하고 model을 generate 하는데 사용된 real experience로 value function을 배우기도 한다.
아래 그림에 이에 대한 내용이 나타나 있으며 일반적인 model-based RL와 중간의 가로지르는 호의 존재 여부가 다르다
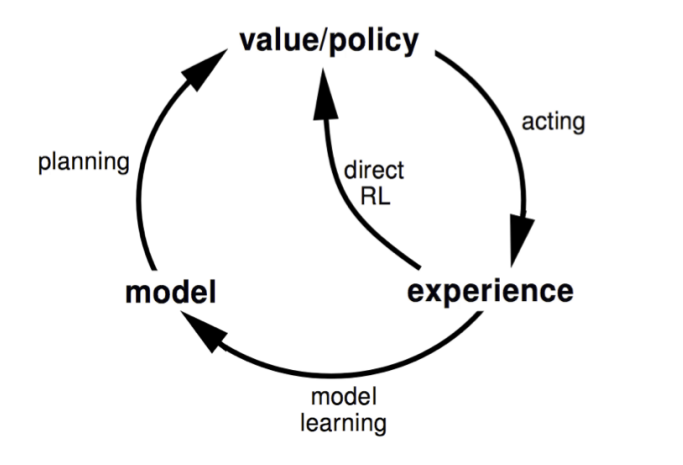
-
Dyna-Q 알고리즘의 pseudo code은 아래와 같다.

Simulation Based Search
-
이 절에서는 planning을 effective하게 만드는 법에 대해 배운다.
-
forward search는 현재 state 에서부터 시작해 sub MDP를 만든다. ; 현재 state에서 도달할 수 없는 state, action에 대해 explore 하는 것은 아무 의미가 없기 때문에 현재 state를 root로 하는 MDP를 해결하는 것이 중요하다 (using sub-MDP)
-
forward search에서는 lookahead를 통해 best action을 선정하며 앞서 말한대로 current state에서부터 search tree를 build한다.
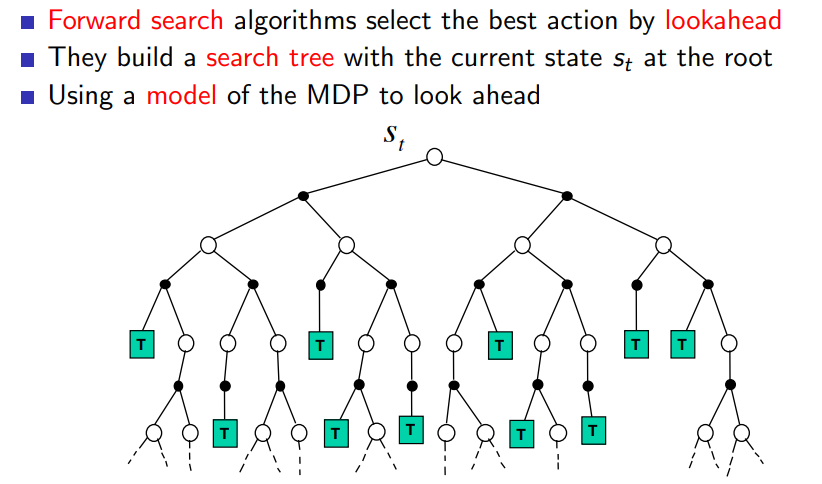
-
simulation based search는 현재 state에서부터 시작한다는 점에서 마찬가지로 forward search paradigm을 따른다고 할 수 있고 현재 시점부터 시작해 episode 들의 집합을 simulation을 통해 얻어낸다.
이렇게 얻은 episode들에 대해서는 Model-free RL을 적용하여 value function을 계산한다.
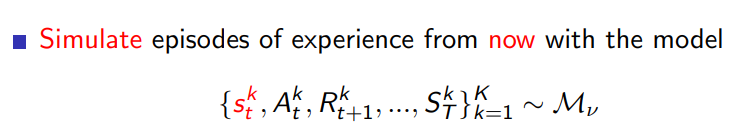
여기서 적용하는 알고리즘이 MC-control이면 MC search 가 되는 것이고 SARSA 이면 TD search가 되는 것이다.
MC Search
-
먼저 simple MC search에 대해 알아보면 model과 policy가 주어진 경우 K개의 episode에 대해 각 time과 state에서 얻는 return을 모두 더하여 평균 낸 Monte-carlo evaluation을 통해 Q 함수 값을 정할 수 있다.
Search tree 형성이 끝나면 그 중 최고의 Q 값을 선정하기 위해 action a에 대한 argmax를 적용한다.

-
그 다음은 Monte Carlo Tree search에 대해 알아보도록 하자
마찬가지로 K개의 episode와 model이 주어졌을 때 위와 같은 방식으로 Q value function을 기록하고 search tree 형성이 끝나면 action 선정도 위와 마찬가지로 a에 대한 argmax를 취한다.

여기까지가 evaluation 단계를 의미
-
policy improvement는 다음과 같은 과정을 통해 이뤄진다. (이 단계는 simulation 단계로 칭함)
각 simulation 은 in-tree와 out-of-tree 두가지 phase 중 하나로 존재하는데 전자는 Q(s,a)를 maximise 하는 action을 고르는 tree policy이며 후자는 action을 랜덤하게 정하는 default policy이다.
그리고 simulation이 선정되면 각각에 대해 Monte-Carlo evaluation 을 통해 evaluate 하고 로 policy를 improve 한다.
simulation 선정 과정 이후 Monte-Carlo control이 사용되었음을 알 수 있다.

-
장점

TD search
-
위의 MC search에서 sub MDP 에 대해 simulation 선정 후 MC control을 진행하는 대신 TD control (SARSA)을 하면 TD search 알고리즘 완성

-
Control에서도 그랬듯이 search에서도 TD의 low variance but high bias 성질이 도움이 된다. (MC 보다 좋은 성능 가능)
Dyna-2
- Integrated version 에서 제시된 것처럼 real experience가 model estimation과 value function 업데이트에 동시에 사용되는데 여기서는 이를 더 응용해
real experience ~ Long-term memory
simulated experience ~ Short-term memory
이 둘을 대응시키는 방식을 생각해냈다. 상세 내용은 아래와 같다.

