구분
DL < NN < ML < AI
- Artificial Intelligence (AI): science and engineering of making intelligence machines
- Machine Learning (ML): subset/subfield of AI that self-learns through data
- Neural Networks (NN)
- Deep Learning (DL) - "deep" describes # of hidden layers
Note on ML
- ML algorithms are better at seeing patterns in the data
- Ethics: algorithms itself are neutral, input data can be biased thus affecting the algorithms
Type of Learning
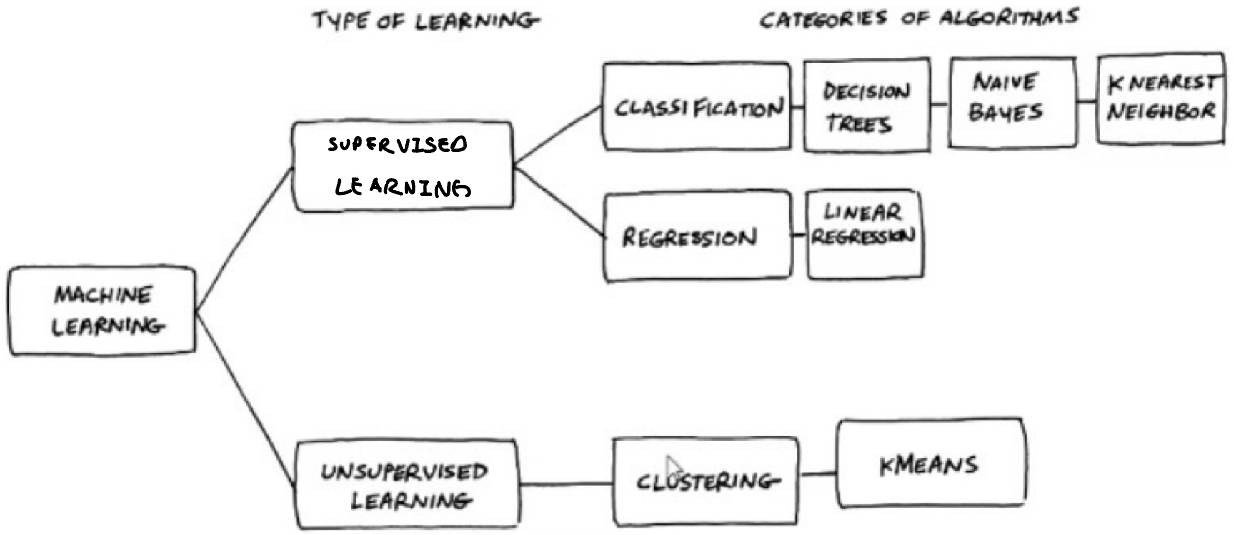
- Supervised Learning: data with labels
- Unsupervised Learning: data without labels
- Semi-supervised Learning: some data with labels, some without
- Reinforcement Learning: learning based on errors and rewards
Data & Pre-processing
Type of Data
- Structured Data: features have clearly defined meaning/data types (e.g. DB, table of data)
- Unstructured Data (e.g. audio, image, text, etc.)
Common/General Pre-processing Techniques
- Imputation: dealing with missing data/values (e.g. mean, interpolation, etc.)
- Principal Component Analysis (PCA): dimensionality reduction
- Standardization/Normalization: important especially when different features have different units (e.g. height will have more contribution in distance calculation compared to weight)
Bias (편향) & Variance (분산)
Trade-off between bias and variance
- Bias: gap between predicted value and actual value (label)
- | human error - training error |
- Variance: how scattered predicted value is from actual value (label)
- | training error - validation error |
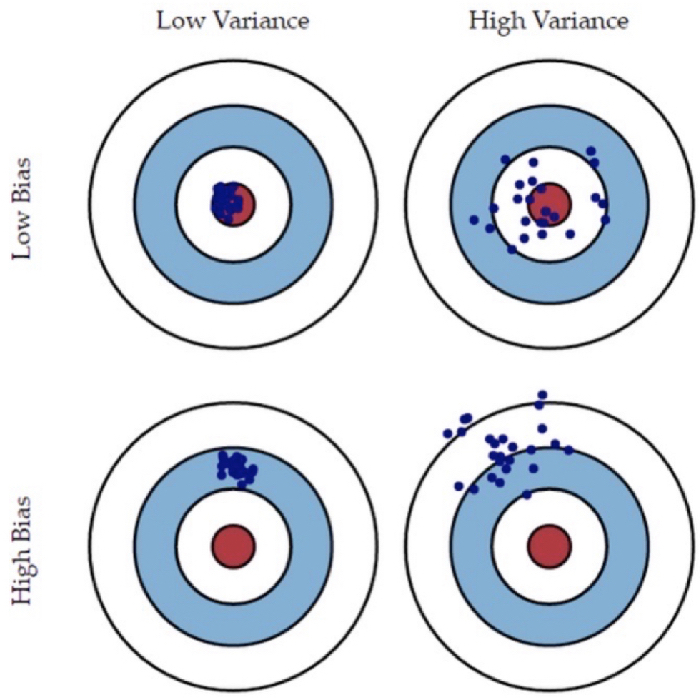
Underfitting: high bias, low variance ("systematically wrong, doesn't capture complexity")
- More complex network
- Train longer
Overfitting: low bias, high variance ("vulnerable to noise and fluctuation in data")
- More data
- Regularisation (e.g. dropout, regularizer)
Common Techniques
Train/Dev/Test set
- Validation or Development set: fine-tune hyperparameters (these are parameters that control learning, not learnt by the machine)
- Test: evaluating the model ("final say")
Dev and Test set should come from the same distribution that is close to "real"
K-fold Cross Validation - useful when data is limited (use the whole training data instead of splitting it into train and dev)
- Increase K: lower bias, higher variance
- Increasing the number of folds means we use more training data (but at the same time, risk poor generalisation)
- Leave-One-Out Cross Validation (LOOCV): K=n where n is the number of training samples
- At each iteration, we use n-1 samples as training data and 1 sample as validation (thus, LOO)
Prediction
- Ensemble (or bagging): average the results of various models (lower varaince)
- Stacking: predictions of one model becomes the inputs of another model
- Idea: each model learns some part of the problem instead of the whole problem, potentially improving performance
ML
Supervised Learning
Classification - predicts class/label
Naive Bayes
Assumes that each evidence/feature/predictor makes an independent and equal contribution to the belief/label/prediction.
K-Nearest Neighbor (KNN)
Lazy (online) learning - learning happens real time as data is streamed in
Standardization is necessary
PCA can speed up KNN
Select K neighbors and predict using majority vote (break ties when necessary)
Close to a neighbor -> More likely to share common characteristics
Good value of K
- Too small -> sensitive to outlier (high variance, low bias)
- Too large (extreme K=n - prediction is the same for ALL data points)
- In general, larger K yields lower variance, higher bias
- Use CV to determine a good value
Neural Networks (NN)
Artificial Neural Network (ANN)
Perceptron
single artificial neuron (simplest ANN)
draws a linear boundary (binary classification) - thus can only model lineary separable problems (e.g. logical AND)
Multi-Layer Perceptron (MLP)
We can form MLP by connecting output of one perceptron to the input of another perceptron
Draws a curve boundary - thus can handle non-linearly separable problems (e.g. logical XOR)
- 2 linear boundaries can be joined by another neuron, formign a curve
An ideal activation function is non-linear and differentiable. Without a non-linear activation, MLP is no better than a single perceptron
- Activation functions do NOT have to be continuous and differentiable at every point
- ReLU is a good activation since it is non-saturating and converges faster than sigmoid
Convolutional Neural Network (CNN)
Feature Extractor: Convolution+Pooling
Classifier: Flatten+FC layers
Main Idea: we extract high-level features as we go through convolutions
(e.g. edges -> combination fo edges -> object models)
Pooling reduces the number of parameters and summarizes the output
Pooling & Strides help prevent overfitting
It is better to apply smaller kernel many times than applying larger kernel fewer times (better quality & less parameters)
Conv > FC
- Preserves spatial context
- Less number of parameters required (shared parameters - kernels)
Recurrent Neural Network (RNN)
Good for sequential data (e.g. text, audio, video)
- Retains internal memory ("context")
tanh as activation
Long Short Term Memory (LSTM)
- short term memory learning
- overcomes the problem of exploding/vanishing gradients
Gated Recurrent Unit (GRU)
- less parameters, simple
Regression (회귀) - predicts a value
Linear Regression
etc.
Logistic Regression
Sigmoid - non-linear (but saturating), values between 0 and 1 (can have a cutoff/threshold for binary classification)
Unsupervised Learning
Clustering
K-Means
Standardization is necessary
It is believed that PCA improves clustering results in practice
Select K initial centroids (random)
Compute distances and assign each data point to a cluster
Re-compute the centroids according to new membership
Repeat until cluster memberships do not change (will ALWAYS converge)
Density-based, Model-based, etc.
etc.
Optimization Algorithms
Gradient Descent (기울기 하강)
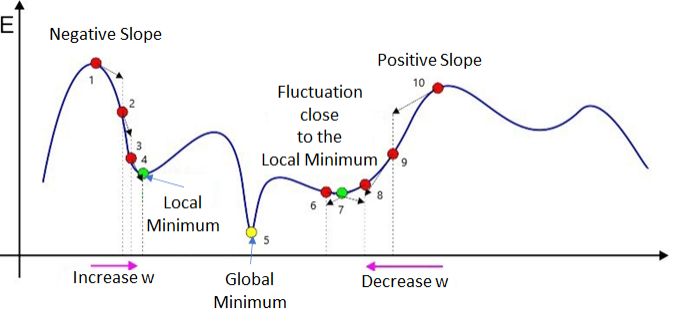
x := x - alpha * dJ/dx, where x is a parameter, J is the cost function
- Reason for -?
- For negative gradient, x should increase
- For positive gradient, x should decrease
- Why gradient descent instead of a closed-form solution?
- Often, there is no closed-form solution
- Even if there is, gradient descent is computationally cheaper
Exploding/Vanishing gradients (기울기 소실/폭주)
For a deep network, we have potential risk of exploding/vanishing gradients (during backward propagation)
- Exploding gradients: parameters of layers closer to output vary dramatically, whereas parameters of layers closer to input do not change significantly
- Vanishing gradients: parameters grow exponentially
Solution
- Weight Initialization
- Use non-saturating activation (e.g. ReLU)
- Gradient Clipping
Batch
Batch size in training basically controls how many times the parameters are updated (since each epoch is a run through the whole training set)
Let N be # of training samples in the training set
- Stochastic Gradient Descent: batch size = 1
- Mini-batch Gradient Descent: 1 < batch size < N
- Batch: batch size = N
For batch size > 1, it requires estimation in order to update the parameters (potential computational overhead)
Batch - slower but gives an optimal solution (given enough time)
Stochastic - faster but not optimal (keeps oscillating)
Mini-batch strikes a balance between the two
Optimization Algorithms
Gradient-based
Momentum - compute exponentially weighted average of gradients and use it to update weights
RMSprop - compute expoentially weighted average of gradients and use decay (to damp out oscillations)
Adam - combines momentum and RMSprop
Evaluation Metrics
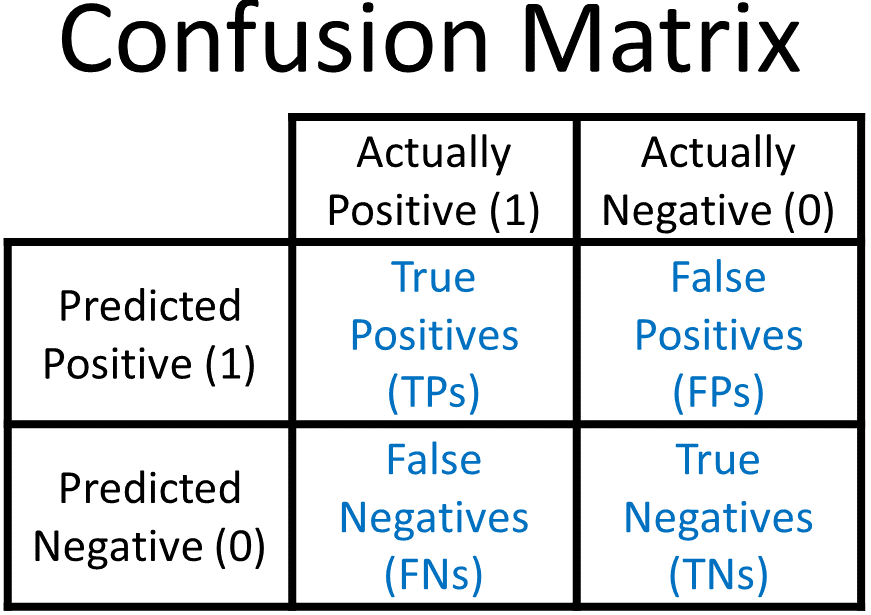
- P or N: determined by prediction value
- T or F: determined by whether prediction is correct
Metrics
- Accuracy: focus on TP, TN (i.e. correctly identified cases)
- F1: focus on FP, FN (better option for imbalanced data)
- harmonic mean of precision & recall
- precision: focus on predicting 1 correctly
- recall: focus on detecting 1 correctly
