앞서 살펴본 ECDSA에서 random curve를 generate하는 과정에 hash function이 사용됐습니다. 그리고 메시지를 서명하는 과정에서도 hash function이 사용됐습니다. Hash function은 임의의 길이의 입력 데이터를 고정된 길이의 데이터로 mapping하는 함수입니다. Hash function은 출력 데이터로부터 입력 데이터를 알아낼 수 없다는 특성 때문에 암호학에서 매우 중요하게 사용됩니다.
이번 포스트에서는 Cryptographic hash function이 왜 필요한지, 그리고 hash function의 대표적인 예시인 MD5, SHA 알고리즘이 어떻게 설계되었는지 알아보겠습니다.
Hash function의 필요성
Hash function은 주로 무결성을 검증하는 것에 사용됩니다. 입력 데이터의 극히 작은 부분만 바꾸어도 Avalanche Effect에 의하여 최종 결과값은 큰 차이를 보이게 됩니다. 따라서 위조, 변조가 불가능하게끔 하는 것에 그 의의를 두고 있습니다. 특정 데이터를 제공할 때 해당 데이터의 무결성을 보장하기 위해 hash 값을 같이 전달합니다. 특정 파일이나 메시지를 배포하거나 전송할 때, 중간에서 데이터가 위조, 변조가 되지 않았음을 보장하는 데 사용될 수 있습니다.
또한 Hash function은 출력 데이터로부터 입력 데이터를 알아낼 수 없기 때문에, 로그인 시 비밀번호를 통한 인증에도 사용될 수 있습니다. 서버에는 비밀번호의 hash 값만을 저장함으로써, 로그인 시 입력된 비밀번호의 hash 값과 저장된 hash 값을 비교함으로써 인증을 진행할 수 있고, 서버가 해킹당하더라도 비밀번호를 안전하게 지킬 수 있습니다.
Hash function의 특성
Cryptographic hash function이 갖춰야 하는 특성들은 다음과 같습니다.
- Hash function은 주어진 입력에 대해서 효율적으로 hash 값을 계산해야 합니다.
- (Pre-image resistance) 주어진 hash 값으로부터 원래의 입력 데이터를 알아내기 어려워야 합니다.
- (Second pre-image resistance) 특정 입력 데이터가 주어질 때, 해당 입력 데이터의 hash 값과 동일한 hash 값을 갖는 다른 입력 데이터를 찾아내기 어려워야 합니다.
- (Collision resistance) 동일한 hash 값을 가지는 입력 데이터 쌍을 찾아내기 어려워야 합니다. 만약 그러한 쌍이 존재한다면, 해당 쌍을 hash collision이라고 합니다.
MD5
위의 요구사항을 모두 만족하는 hash function은 어떻게 설계되는 것일까요? 초기에 발표된 hash function으로 MD(Message Digest) 함수가 있습니다. MD 함수는 블록 암호에서 영향을 받아 입력 데이터를 특정 길이의 블록으로 쪼개 hash화를 진행합니다. 현재는 MD 함수에 결함이 발견되어 사용하는 것을 권장하지 않고 있습니다.
MD5 hash function은 임의의 길이의 데이터를 입력받아 128비트 길이의 데이터를 출력합니다. 그 과정을 살펴보겠습니다.
먼저 MD5 알고리즘은 512비트 단위로 hash화를 진행하기 때문에 입력 데이터의 비트 길이가 512의 배수가 되게끔 padding을 해야 합니다. Padding 규칙은 다음과 같습니다.
- 입력 데이터 비트의 오른쪽에 1을 하나 붙입니다.
- 입력 데이터 비트의 길이가 가 될 때까지 오른쪽에 0을 붙입니다.
- 마지막 64비트에 padding되기 전 입력 데이터의 길이를 저장합니다. 이 때 저장 방식은 리틀 엔디언(little-endian) 방식을 따릅니다.
이제, padding된 입력 데이터를 512비트 블록들로 쪼개고, 각 블록에 대해서 연산을 진행합니다. 각 블록은 총 16개의 32비트 워드로 나누어지고, 총 4라운드에 걸쳐 연산이 진행됩니다. 각 라운드는 비선형 함수 F, 모듈라 덧셈, left rotation에 기반한 16개의 동일 연산(similar operations)으로 이루어집니다. 아래 그림은 MD5의 단일 연산을 그림으로 표현한 것이며, 한 메시지 블록 당 총 64번의 연산을 진행합니다.

처음에 A, B, C, D 4개의 32비트 워드 버퍼를 소정의 상수값으로 초기화 합니다.
var int h0 := 0x67452301
var int h1 := 0xEFCDAB89
var int h2 := 0x98BADCFE
var int h3 := 0x10325476
각 라운드에서 사용되는 비선형 함수 F는 다음과 같습니다.
- (x∧y)∨(¬x∧z)
- (x∧z)∨(y∧¬z)
- x⊕y⊕z
- y⊕(x∧¬z)
위 그림에서 는 메시지 블록의 i번째 32비트 워드로, 한 라운드에서 이루어지는 16번의 연산 동안 각 워드를 처리하게 됩니다. 아래는 MD5 알고리즘의 의사코드입니다.
// 한 블록 당 64번의 단일 연산 처리, 각 라운드 당 다른 비선형 함수 f 사용
for i from 0 to 63
if 0 ≤ i ≤ 15 then
f := (b and c) or ((not b) and d)
g := i
else if 16 ≤ i ≤ 31
f := (d and b) or ((not d) and c)
g := (5×i + 1) mod 16
else if 32 ≤ i ≤ 47
f := b xor c xor d
g := (3×i + 5) mod 16
else if 48 ≤ i ≤ 63
f := c xor (b or (not d))
g := (7×i) mod 16
temp := d
d := c
c := b
b := b + leftrotate((a + f + k[i] + w[g]) , r[i])
a := temp메시지 블록이 모두 처리되고 나면, 워드 버퍼 A, B, C, D의 값을 이어 붙여 128비트 값을 출력합니다.
var int digest := h0 append h1 append h2 append h3 //(expressed as little-endian)SHA-1
SHA(Secure Hash Algorithm) 함수는 미국 국가안보국(NSA)이 1993년에 처음으로 설계했으며 미국 국가 표준으로 지정되었습니다. SHA 함수군에 속하는 최초의 함수는 공식적으로 SHA라고 불리지만, 나중에 설계된 함수들과 구별하기 위하여 SHA-0이라고도 불립니다. 2년 후 SHA-0의 변형인 SHA-1이 발표되었으며, 그 후에 4종류의 변형, 즉 SHA-224, SHA-256, SHA-384, SHA-512가 더 발표되었다.
SHA-1 알고리즘은 최대 길이 의 입력 데이터를 160비트의 출력 데이터로 변환합니다. SHA-1 알고리즘도 블록 당 암호화를 진행하며, 그 방법이 MD5와 유사합니다. 아래 그림은 SHA-1 알고리즘의 단일 연산을 나타냅니다.
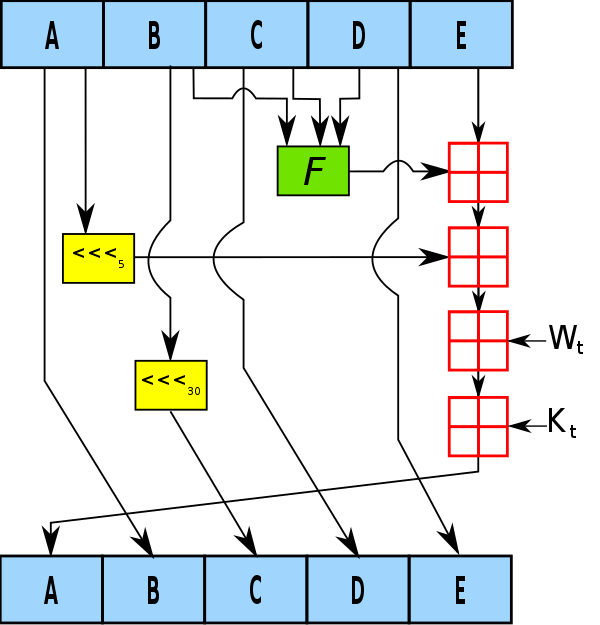
SHA-1 알고리즘은 SHA 함수들 중 가장 많이 쓰이며, 많은 보안 프로토콜과 프로그램에서 사용됩니다. SHA-1 알고리즘은 hash 충돌이 발견됐기 때문에, 민감한 기술에서는 SHA-2 알고리즘을 사용할 것을 권장하고 있습니다.
