Data Engineering
1.Apache Impala

Hadoop 기반 데이터를 SQL를 이용해 실시간 질의할 수 있게 해주는 시스템기존 Hive를 이용하여 동일한 기능을 사용할 수 있지만, Hive 경우 MapReduce 프레임워크를 이용하기에 속도적으로 큰 차이를 보인다.Impala는 실시간 데이터 접근을 위해 임팔라
2.Apache Hive on Tez
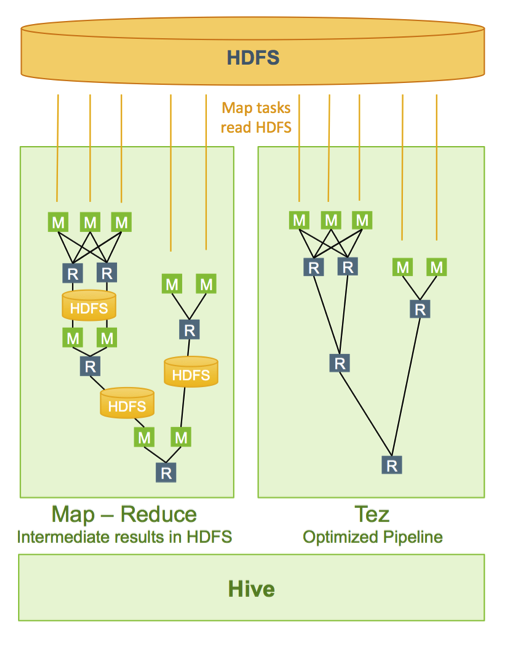
보통 자사 솔루션을 CDH 환경에서 많이 구동하였고, 임팔라를 사용하였기에 접해본적은 없었지만 HDP 환경 및 CDP 환경에서는 Hive 기본옵션으로 Tez가 들어왔으므로 Hive on Tez에 대해서 정리해보고자 한다.Hive에 경우 실행엔진을 MR,TEZ,SPARK
3.Hadoop 구성요소
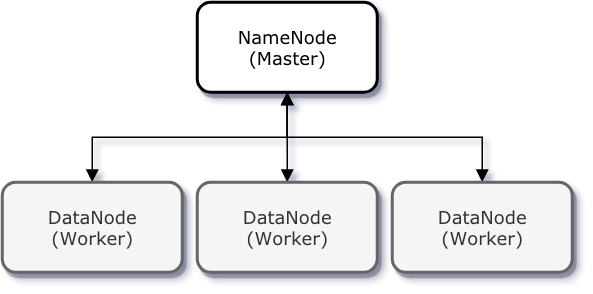
회사에 다니면서 많이 다뤄봤지만 기본적인 개념이 많이 부족한 것 같아 정리해본다.하둡 클러스터는 하나의 마스터 노드와 여러개의 데이터노드로 구성클라이언트로부터 파일접근 요청에 응답 및 관리 역할Hadoop 내 존재하는 파일 및 디렉토리에 대한 "메타데이터" 관리모든 변
4.Hadoop 1.0 vs 2.0 정리
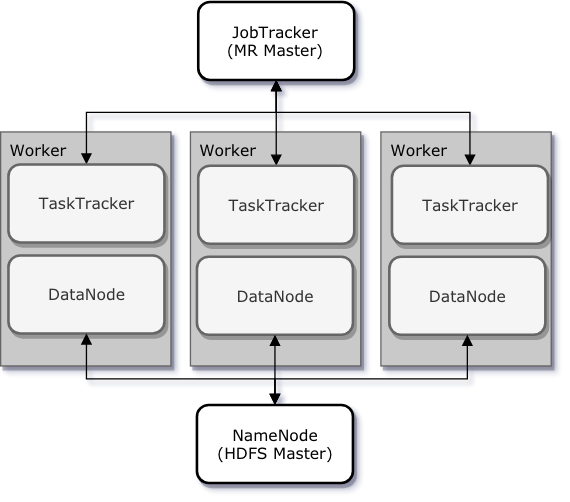
Hadoop1에 경우 써본적은 없지만 어떻게 발전이 되었는지 정리해두면 좋을 것 같다.NameNodeDataNodeHadoop 주요 구성요소 NameNode, DataNode가 있고, Hadoop 위에서 작업을 실행하기 위한 MapReduce Job에 구성요소는 Jo
5.Kafka To Hive
실시간 데이터를 하이브에 저장해야하는 요건이 생길수가 있으므로, 참고자료를 남겨본다참조 : https://github.com/apache/hive/blob/master/kafka-handler/README.md
6.Apache Hudi
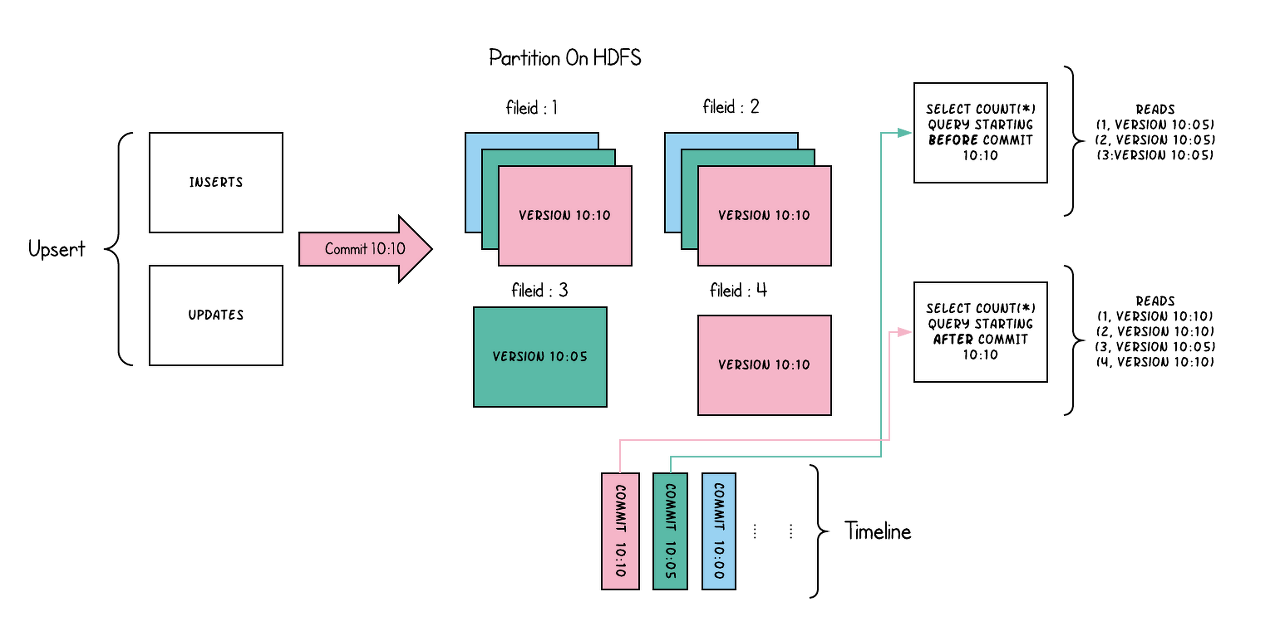
Apache Hudi는 HDFS 또는Cloud Storage 기반으로 대량의 분석데이터를 저장하고, 관리할수 있는 스토리지이다. Apache Hudi는 스트림을 통해서 실시간 데이터를 가져올수도 있고, 전통적인 batch 프로세싱으로 데이터를 저장할 수도 있다.기존 H
7.Hive 추가 정리
Hive를 사용하며 상세한 Hive에 내용을 잘모르는 것 같아 정리를 해본다.메타스토어에 저장되는 테이블의 종류에는 2가지가 존재한다.생성 시 location(hive.metastore.warehouse.dir) 위치에 directory에 저장되는 테이블기본적으로
8.Hive 정렬(Order,Sort,Cluster, Distribute By)
Hive 정렬관련해서 정리해보고자 한다.크게 Order By, Sort By, Cluster By,Distribute By 4가지로 나뉜다.1개의 리듀서로 전체데이터 정렬데이터 용량이 클수록 오류 발생확률 높아짐리듀서별로 데이터 정렬리듀서 개수가 많을수록 속도는 빠름최
9.minIO
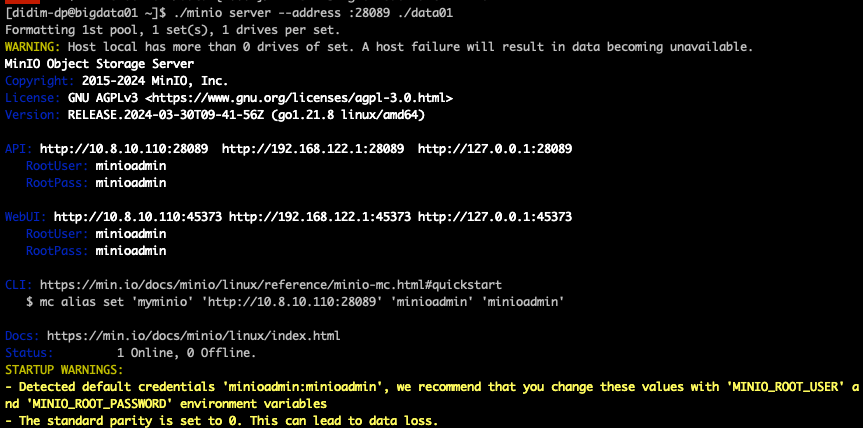
회사에서 오브젝트 스토리지 관련하여 S3를 사용하던 도중 AWS가 없을 때 대체할 오브젝트 스토리지를 찾아보던 중 minIO를 알게 됨.오픈소스로써 분산모드로 사용도 가능하여 데이터 레이크나 저장소로 활용 하기 좋을 거 같아서 설치 및 기록해본다. 기본적으로 제공해주는
10.Apache Paimon
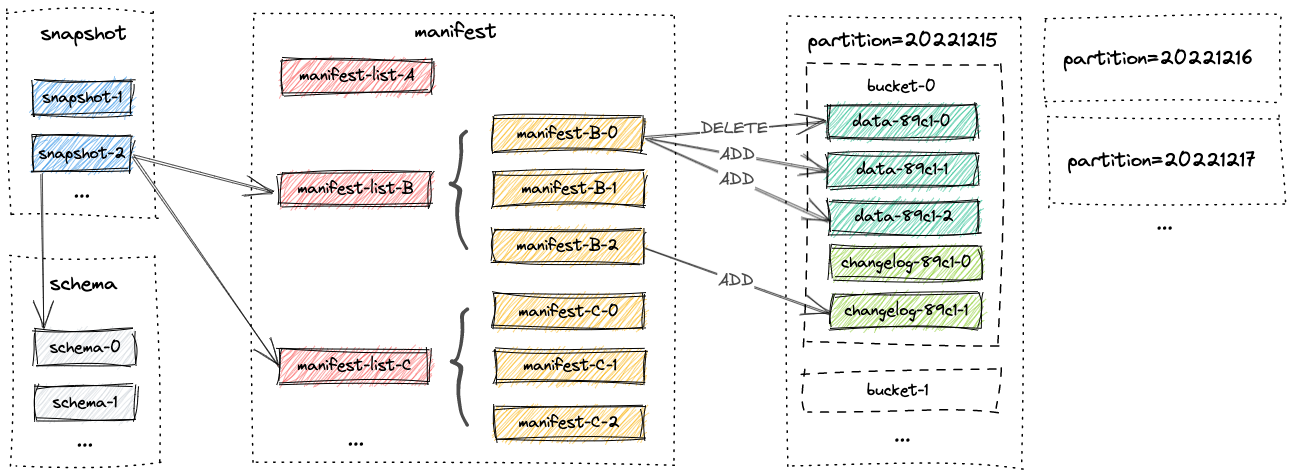
요즘 내부적으로 Apache Iceberg 및 Apache Spark 관련 기술스택을 만지다가, 우연히 실시간 오픈 테이블포맷이 나왔다고 해서 정리해본다.Apache Paimon은 대규모 데이터 레이크(Lake) 환경에서의 실시간 스트리밍 & 배치 처리를 모두 지원하는
11.Elastic Job
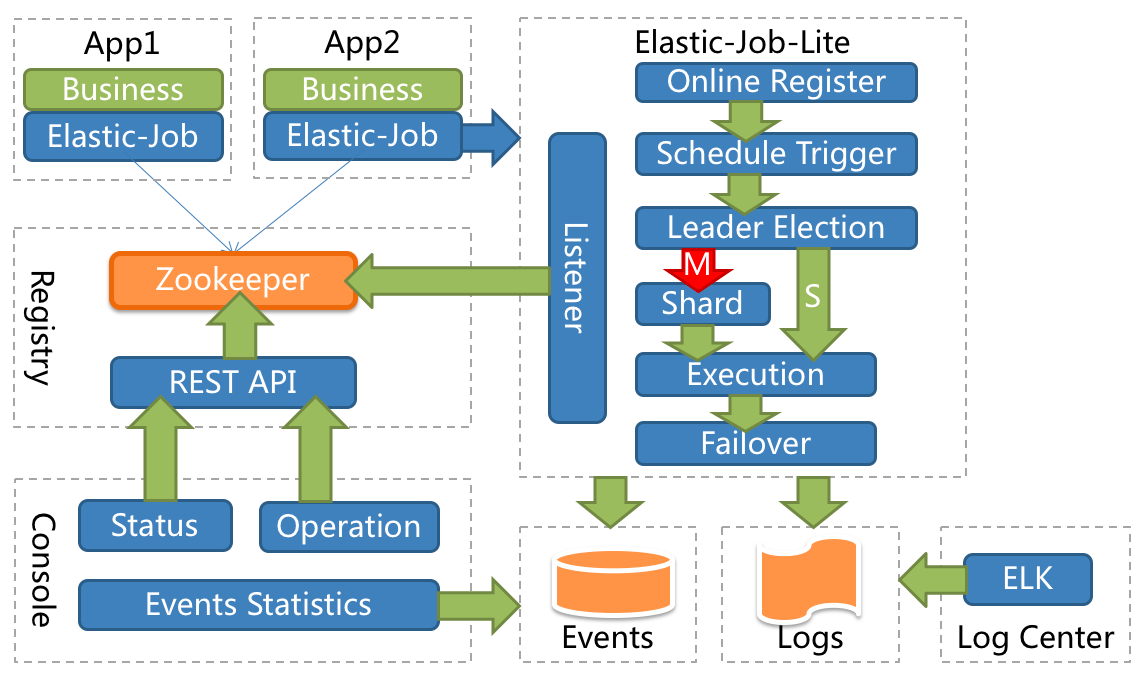
이번에 배치작업을 이중화하는 요건이 생겨 기존 Quartz 아닌 다른 오픈소스를 찾아보다가 적어본다.주기적인 작업이외에 단발성 작업이 많이 발생하는데 해당 작업이 여기에 잘 맞을지는 의문이지만 적용가능한지는 기술 검토중에 있다.Apache ShardingSphere의
12.DolphinScheduler
이것저것 요즘 데이터 엔지니어 관련 오픈소스들을 많이 찾아본다. 기존에 Quartz 혹은 Elastic Job은 봤는데 눈에 들어와서정리를 남겨본다.데이터/업무 파이프라인을 DAG 기반으로 스케줄링·실행·모니터링하는 오픈소스 플랫폼분산 구조Multi-Master / M
13.Apache Gravitino
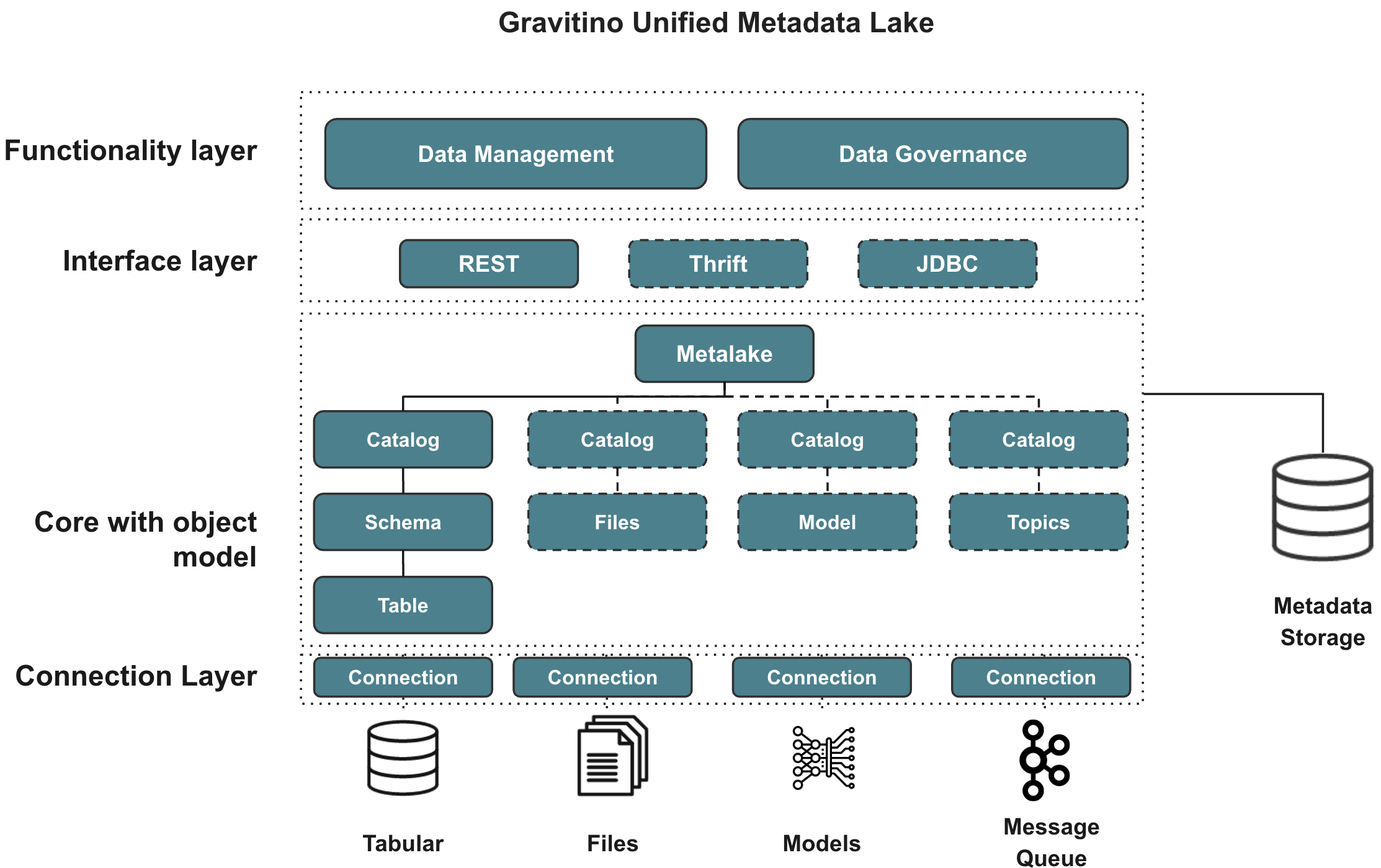
내부적으로 메타데이터 및 데이터 거버넌스 관점 측면에서 어떤 걸 활용하면 좋을 지 고민 중에 좋은 오픈소스를 발견해서 기본적인 정리를 해본다.Apache Gravitino는 이기종 데이터 소스들의 메타데이터를 통합 관리하고,SQL·REST·gRPC와 같은 표준 인터페이
14.RocksDB
Spark Structured Streaming에서 stateful 파이프라인을 다루다 보면 state 크기가 커질수록 OOM이나 GC pause 문제가 생긴다. 이게 HDFSBackedStateStore의 한계인데, 이걸 해결하는 게 RocksDB State Store다. 그래서 RocksDB가 뭔지, Spark에서 어떻게 동작하는지 정리해본다. > R...
15.Apache Polaris
Apache Iceberg 기반 lakehouse를 구성하다 보면 "catalog를 뭘 쓸 것인가"가 계속 따라온다.Hive Metastore나 AWS Glue로 시작하지만, 멀티 엔진 환경이 되면 결국 한계를 만난다.이걸 해결하는 게 Apache Polaris다.그래