보통 자사 솔루션을 CDH 환경에서 많이 구동하였고, 임팔라를 사용하였기에 접해본적은 없었지만 HDP 환경 및 CDP 환경에서는 Hive 기본옵션으로 Tez가 들어왔으므로 Hive on Tez에 대해서 정리해보고자 한다.
Hive에 경우 실행엔진을 MR,TEZ,SPARK 선택할 수 있고, 2.0 버전부터는 기본적으로 테즈엔진을 사용한다.
TEZ vs MapReduce
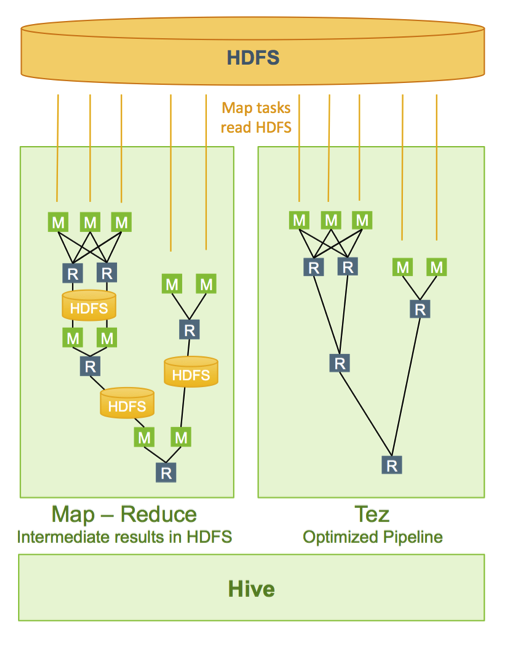
비교 사진만 보아도 효율성에서 크게 차이가 난다.
TEZ는 YARN기반의 데이터 처리를 위한 프레임워크이다.
방향성 비순환 그래프(DAG)를 사용해서 Dataflow Gragh 정의한다는 점이 특징이며,이러한 특징 덕분에 SQL실행 전에 작업량, 리소스에 대해 최적화된 실행 계획을 설계할 수 있다. 실행중에 동적으로 그래프를 변경하며 실행 계획을 최적화하는데 도움을 줄수 있다.
TEZ는 MapReduce동작 방식과 동일하게 Yarn을 통해 container를 할당받는데 이러한 container를 재사용한다. 재사용함으로써 container 리소스를 재할당 받는 메모리의 오버헤드를 줄이는 장점이 있다.
MapReduce는 Map단계에서 데이터를 읽고 중간 산출물을 생성하고, Reduce 단계에서 중간 산출물을 다시 읽어드려 처리하고 최종 결과를 출력한다. MR 엔진 위에서는 앞의 절차를 HDFS에 쓰고 읽으며 진행된다. 작업 중간에 발생되는 임시 데이터도 모두 디스크 상에 읽고 쓰는 방식으로 처리하기 때문에 IO 작업이 빈번히 일어나고 이에따른 오버헤드가 발생된다.
TEZ는 각 STAGE에서 나온 중간 산출물(Map단계의 결과물)을 메모리에 저장 후 Reduce단계로 넘겨 처리하기 때문에 IO가 줄고 속도가 빨라집니다.
HDFS에 읽고 쓰는 불필요한 단계를 감소시킴으로써 기존 MapReduce의 단점을 해결한것이 큰 포인트이다.
