요즘 내부적으로 Apache Iceberg 및 Apache Spark 관련 기술스택을 만지다가, 우연히 실시간 오픈 테이블포맷이 나왔다고 해서
정리해본다.
Apache Paimon은 대규모 데이터 레이크(Lake) 환경에서의 실시간 스트리밍 & 배치 처리를 모두 지원하는 테이블 포맷(Table Format) 및 데이터 스토리지 프로젝트이다.
Apache Flink, Apache Spark, Trino, Hive 등 다양한 쿼리 엔진과 연동 가능하며, 데이터 변경(업서트, 삭제) 과 증분 처리에 강점이 있다.
주요 특징
- Streaming + Batch 통합
- 동일한 테이블에 대해 실시간 스트리밍과 배치 처리를 모두 지원
- 업서트(Upsert) & Delete 지원
- CDC(Change Data Capture) 기반 변경 데이터 처리
- LSM-Tree 기반 스토리지
- 빠른 쓰기 성능과 효율적인 Merge 처리
- Schema Evolution
- 스키마 변경(컬럼 추가/삭제, 타입 변경) 지원
- Time Travel
- 특정 시점 데이터를 쿼리 가능
- High Throughput
- 대규모 데이터에 적합한 읽기/쓰기 성능 제공
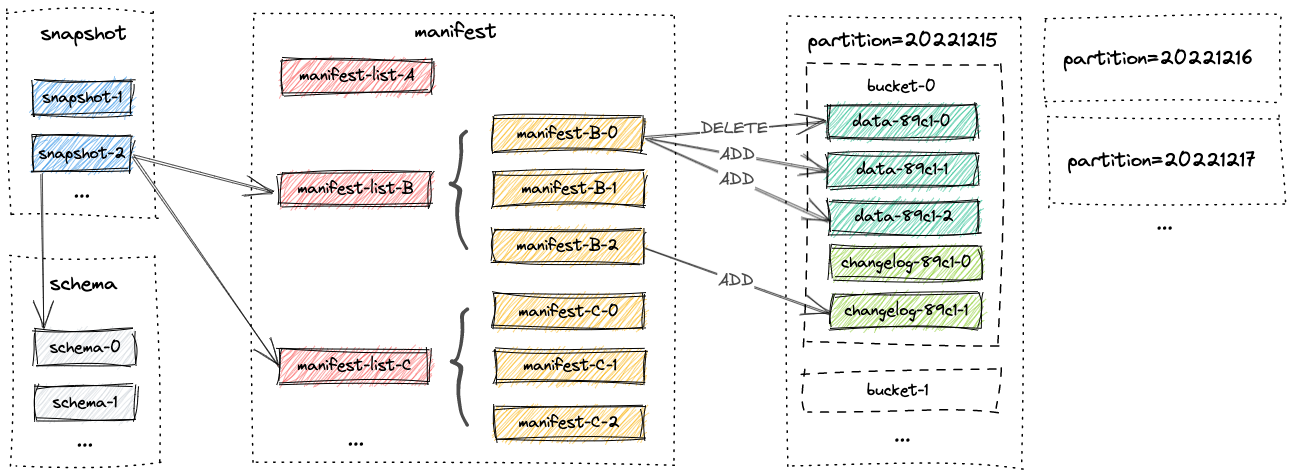
아키텍처 개요
- LSM-Tree 구조
- 새 데이터는 Segment 파일로 기록 후, 주기적으로 Merge
- 삭제/업데이트를 별도 로그로 기록 후 컴팩션 시 반영
- 메타데이터 관리
- 테이블 스냅샷(Snapshot) 기반
- 버전 관리 및 증분 읽기 가능
장점
- CDC 처리 및 실시간 업서트/삭제 지원
- 스트리밍과 배치를 동일 포맷에서 처리 가능
- LSM-Tree 기반으로 빠른 쓰기 성능
- 스키마 변경 및 Time Travel 지원
- 대규모 데이터 처리에 최적화
단점
- Iceberg, Delta Lake 대비 커뮤니티와 생태계가 작음
- 프로젝트 역사가 짧아 운영 경험 및 참고 자료가 부족
- 일부 엔진과의 호환성은 상대적으로 제한적

모든 걸 기록하자