내부적으로 메타데이터 및 데이터 거버넌스 관점 측면에서 어떤 걸 활용하면 좋을 지 고민 중에 좋은 오픈소스를 발견해서
기본적인 정리를 해본다.
Apache Gravitino는 이기종 데이터 소스들의 메타데이터를 통합 관리하고,
SQL·REST·gRPC와 같은 표준 인터페이스를 통해 다양한 엔진(Spark, Flink, Trino 등)에서
일관되게 접근할 수 있도록 하는 메타데이터 서비스 플랫폼
Gravitino Architecture
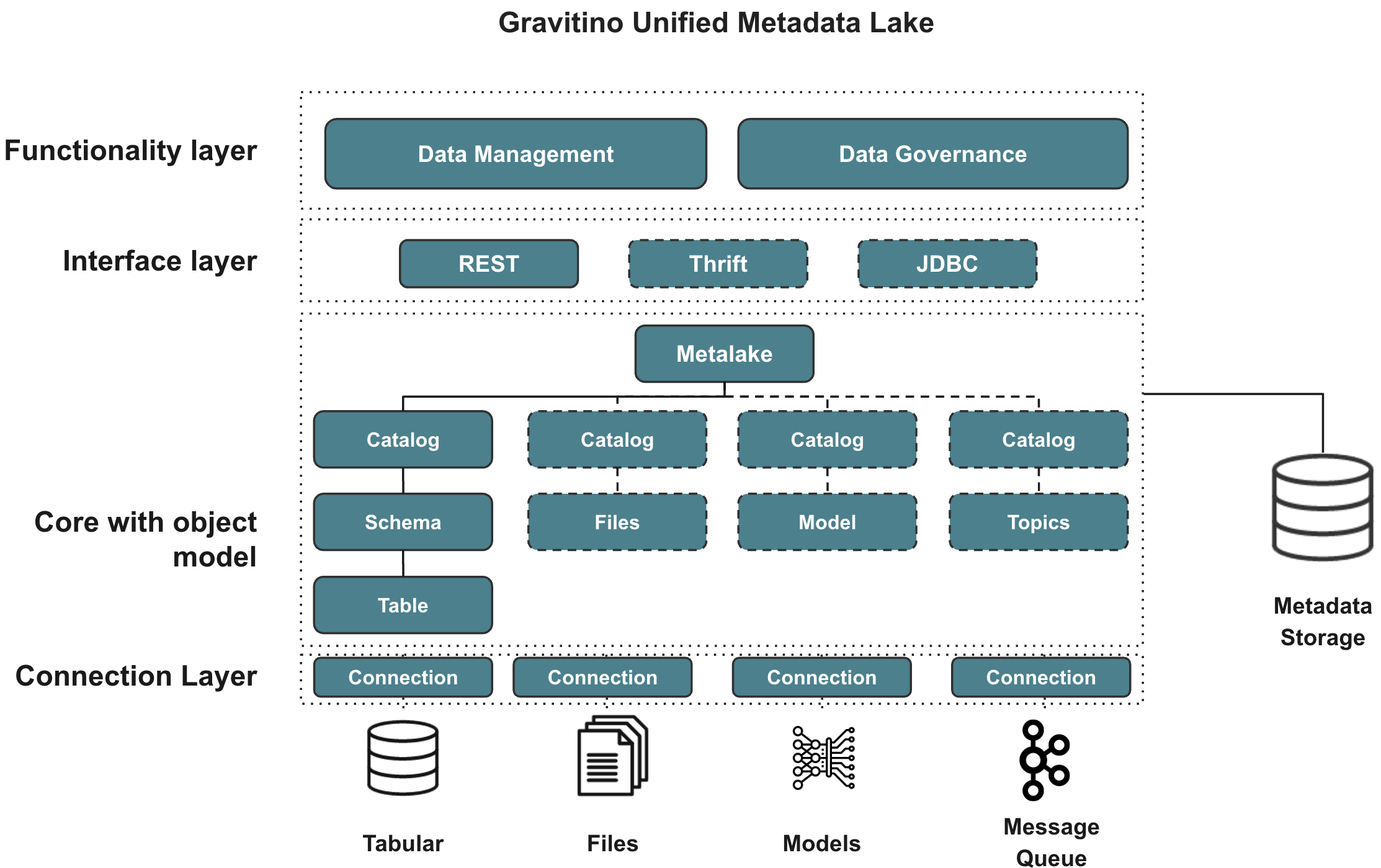
- Client Layer : Spark, Flink, Trino 같은 엔진, BI 툴이 Gravitino에 연결
- Service Layer : 메타데이터 관리, 통합 카탈로그 서비스, 권한 제어, API 제공
- Catalog Layer : 실제 데이터 소스(RDBMS, Data Lake, 메시지 큐, 파일 등)
장점
- 메타데이터 통합 관리 : 다양한 이기종 소스를 카탈로그 단위로 묶어 일관성 제공
- 표준화된 접근 : SQL/JDBC/REST/gRPC 인터페이스로 다양한 엔진에서 동일한 방식으로 접근 가능
- 확장성 : 카탈로그 플러그인 아키텍처로 새로운 데이터 소스를 쉽게 추가 가능
- 데이터 거버넌스 기반 : 권한 제어, 감사 로깅, 접근 정책 같은 기능을 통합 적용 가능
- 데이터 패브릭/메쉬 지향 : 분산된 데이터를 하나의 가상 계층에서 관리 가능
단점
- 초기 단계 프로젝트 : 아직 인큐베이팅 중이라 기능 성숙도가 낮고, 문서나 사례 부족
- 성능 오버헤드 : 모든 메타데이터 요청이 Gravitino를 경유 → 지연(latency) 가능성
- 운영 복잡성 : 자체 서버 구성 및 고가용성/이중화 구성 필요
- 에코시스템 미성숙 : 기존 Hive Metastore, Glue, Unity Catalog 대비 커뮤니티나 툴링 부족

모든 걸 기록하자