
🗃️문제 설명
하드디스크는 한 번에 하나의 작업만 수행할 수 있습니다. 디스크 컨트롤러를 구현하는 방법은 여러 가지가 있습니다. 가장 일반적인 방법은 요청이 들어온 순서대로 처리하는 것입니다.
예를들어
- 0ms 시점에 3ms가 소요되는 A작업 요청
- 1ms 시점에 9ms가 소요되는 B작업 요청
- 2ms 시점에 6ms가 소요되는 C작업 요청와 같은 요청이 들어왔습니다. 이를 그림으로 표현하면 아래와 같습니다.
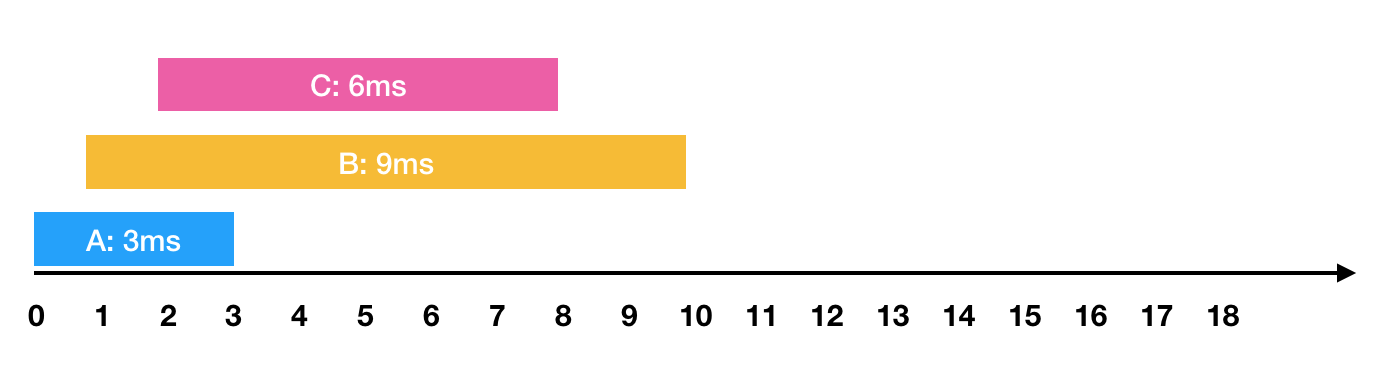
한 번에 하나의 요청만을 수행할 수 있기 때문에 각각의 작업을 요청받은 순서대로 처리하면 다음과 같이 처리 됩니다.
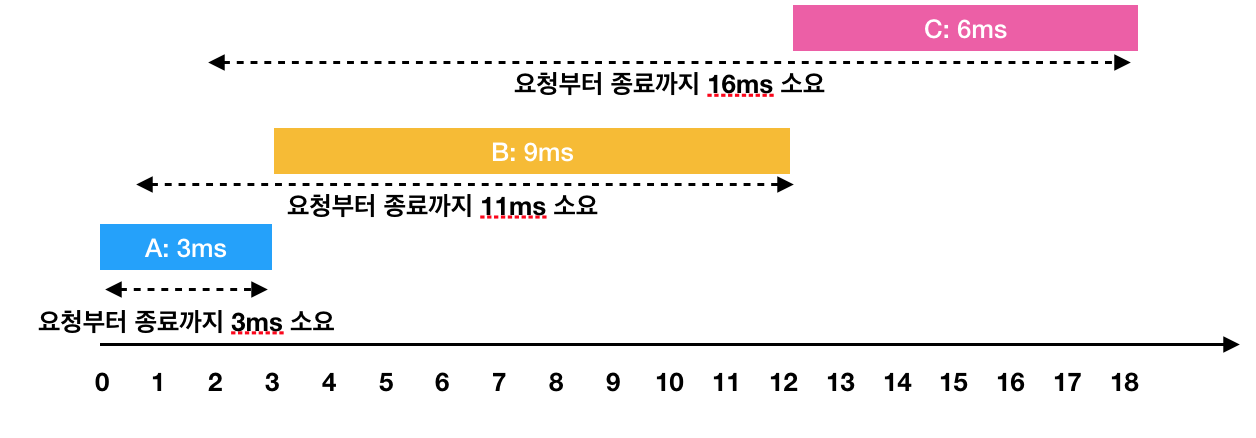
- A: 3ms 시점에 작업 완료 (요청에서 종료까지 : 3ms)
- B: 1ms부터 대기하다가, 3ms 시점에 작업을 시작해서 12ms 시점에 작업 완료(요청에서 종료까지 : 11ms)
- C: 2ms부터 대기하다가, 12ms 시점에 작업을 시작해서 18ms 시점에 작업 완료(요청에서 종료까지 : 16ms)이 때 각 작업의 요청부터 종료까지 걸린 시간의 평균은 10ms(= (3 + 11 + 16) / 3)가 됩니다.
하지만 A → C → B 순서대로 처리하면
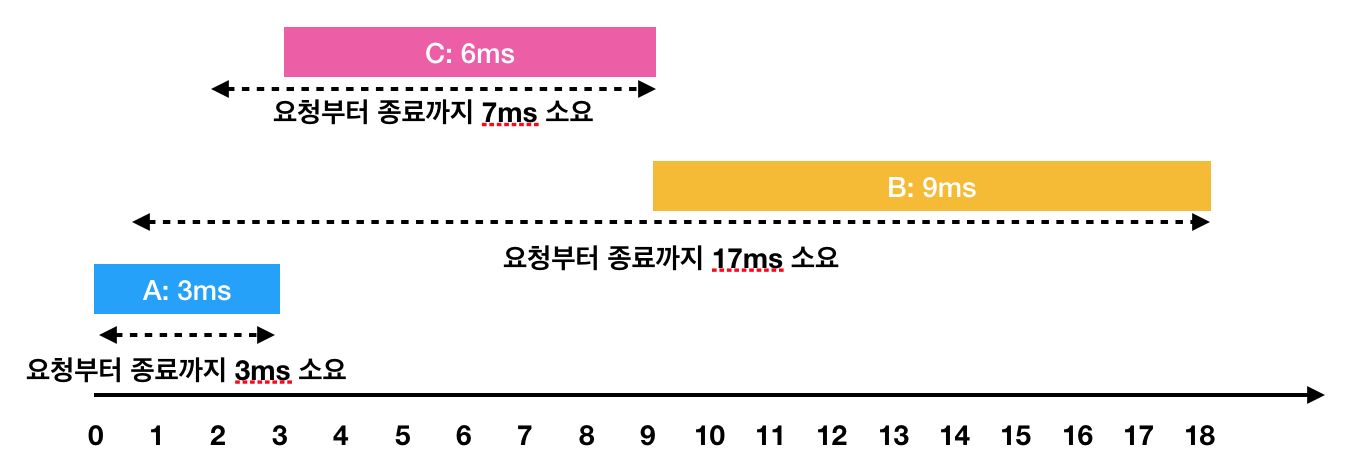
- A: 3ms 시점에 작업 완료(요청에서 종료까지 : 3ms)
- C: 2ms부터 대기하다가, 3ms 시점에 작업을 시작해서 9ms 시점에 작업 완료(요청에서 종료까지 : 7ms)
- B: 1ms부터 대기하다가, 9ms 시점에 작업을 시작해서 18ms 시점에 작업 완료(요청에서 종료까지 : 17ms)이렇게 A → C → B의 순서로 처리하면 각 작업의 요청부터 종료까지 걸린 시간의 평균은 9ms(= (3 + 7 + 17) / 3)가 됩니다.
각 작업에 대해 [작업이 요청되는 시점, 작업의 소요시간]을 담은 2차원 배열 jobs가 매개변수로 주어질 때, 작업의 요청부터 종료까지 걸린 시간의 평균을 가장 줄이는 방법으로 처리하면 평균이 얼마가 되는지 return 하도록 solution 함수를 작성해주세요. (단, 소수점 이하의 수는 버립니다)
🖥️코드
import heapq
def solution(jobs):
start = -1 # 시작 시간
time = 0 # 걸린 시간
now = 0 # 현재 시점
cnt = 0 # 작업 처리 개수
pq = [] # 우선순위 큐
# [작업 소요시간, 작업 요청 시점]
while cnt < len(jobs):
for job in jobs:
if start < job[0] <= now:
heapq.heappush(pq, job[::-1])
# 우선순위 큐에 작업이 들어오면?
if len(pq) > 0:
cur = heapq.heappop(pq)
start = now
now += cur[0]
time += (now - cur[1])
cnt += 1
else:
now += 1
return time // len(jobs)👉힙은 기본적으로 최소 힙을 지원한다. 그렇기 때문에 해당 시점에 들어온 작업이 있는 경우 최소 힙에 push를 하게 되는데 이 때, 뒤집어서 넣는 이유는 맨 첫 번째 원소(작업 소요시간)를 기준으로 들어가기 때문이다.
순서대로 처리하는 것보다 작업 소요시간이 짧은 것부터 처리하는 것이 효율적이기에 뒤집어서 넣으면 작업 소요시간이 짧은 것들이 루트 노드에 자리잡게 된다.
