
- 신장 트리
- 그래프에서 모든 노드를 포함하면서 사이클이 존재하지 않는 부분 그래프를 말한다.
- 모든 노드가 포함되어 서로 연결되면서 사이클이 존재하지 않는다는 조건은 트리의 조건이기도 하다.

- [가능한 신장 트리 예시]를 보면 그래프의 모든 노드를 포함하면서 사이클이 존재하지 않기 때문에 신장 트리가 성립한다고 말할 수 있다.
- [신장 트리가 아닌 부분 그래프 예시]를 보면 그래프의 1번 노드가 포함되지않아 신장 트리가 아니라고 설명할 수 있지만 또한 4, 6, 7번 노드를 보게 되면 사이클이 성립되어 신장 트리가 아니라고 설명할 수 있다.
-
최소 신장 트리 → 최소한의 비용으로 구성되는 신장 트리
-
크루스칼 알고리즘
- 대표적인 최소 신장 트리 알고리즘
- 다익스트라 알고리즘과 같이 그리디 알고리즘으로 분류가 된다.
구체적인 동작 과정
①. 간선 데이터를 비용에 따라 오름차순으로 정렬한다.
②. 간선을 하나씩 확인하며 현재의 간선이 사이클을 발생시키는지 확인한다.
③. 모든 간선에 대하여 ②번의 과정을 반복한다.
-
②번의 과정에서 간선을 하나씩 확인할 때 만약 현재의 간선이 사이클을 발생시키면 최소 신장 트리에 포함시키지 않고 현재의 간선이 사이클을 발생시키지 않는다면 최소 신장 트리에 포함시킨다.
-
[참고] : 최종적으로 만들어지는 최소 신장 트리에 존재하는 간선의 개수는 (전체 노드의 개수 - 1)이 성립한다.
-
[초기 단계]
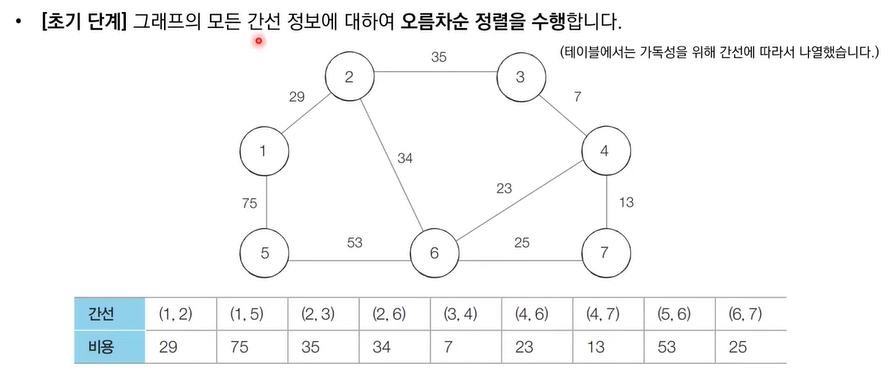
-
[step 1] : 아직 처리하지 않은 간선 중에서 비용이 가장 작은 간선인 (3, 4)를 선택하여 처리한다.

-
[step 2] : 아직 처리하지 않은 간선 중에서 비용이 가장 작은 간선인 (4, 7)를 선택하여 처리한다.
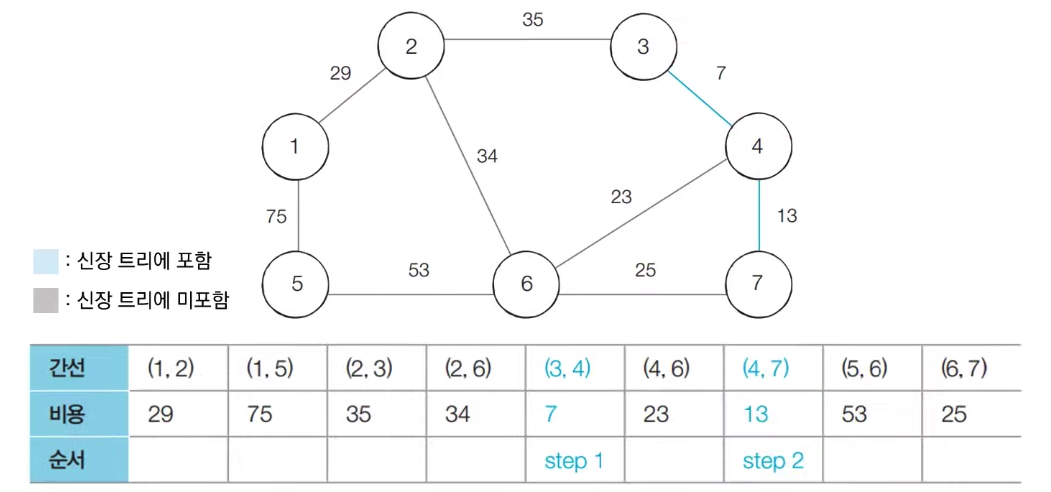
-
[step 3] : 아직 처리하지 않은 간선 중에서 비용이 가장 작은 간선인 (4, 6)를 선택하여 처리한다.
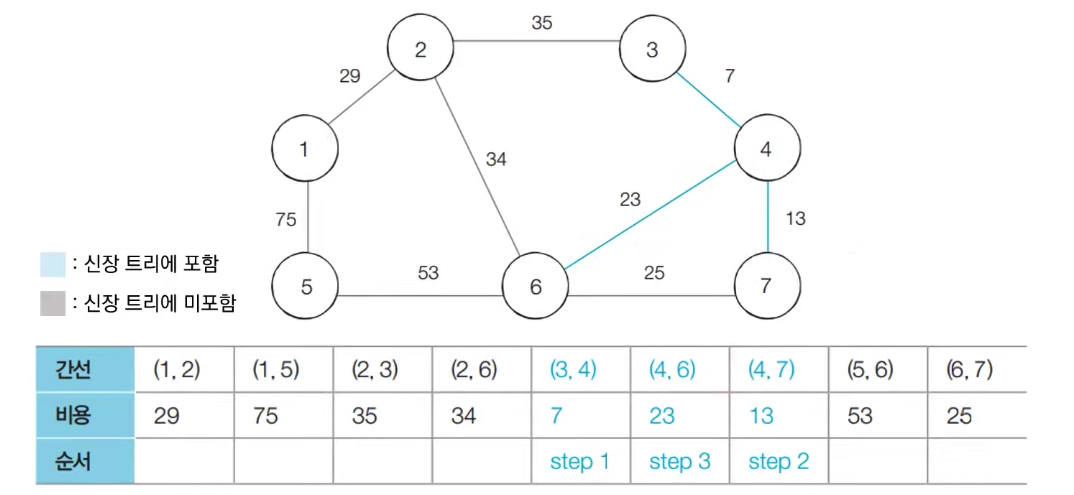
-
[step 4] : 아직 처리하지 않은 간선 중에서 비용이 가장 작은 간선인 (6, 7)를 선택하여 처리한다. 이 때, 6, 7번 노드는 같은 집합에 속해있기 때문에 해당 간선을 넣게 된다면 사이클이 발생하게 된다. 따라서 해당 간선은 그냥 무시하고 넘어간다.
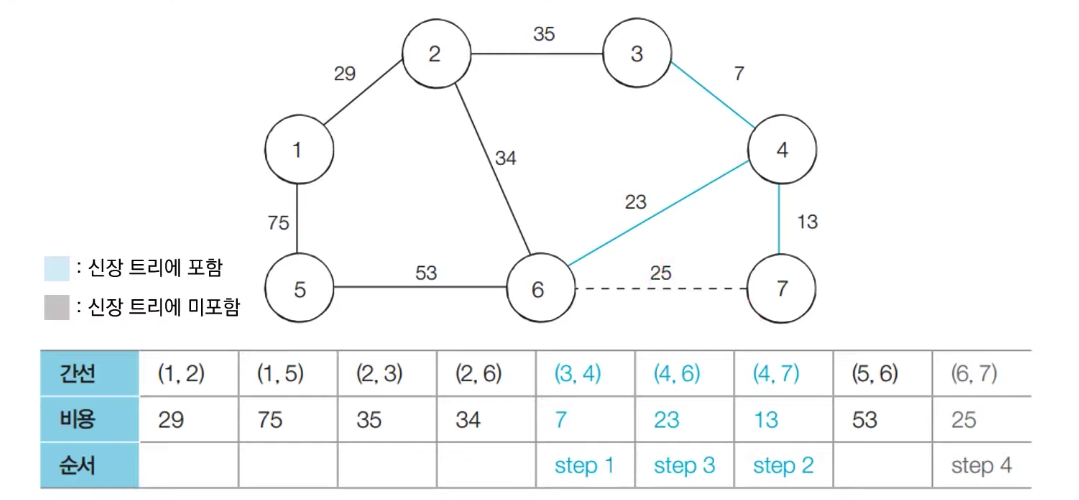
-
[step 5] : 아직 처리하지 않은 간선 중에서 비용이 가장 작은 간선인 (1, 2)를 선택하여 처리한다.
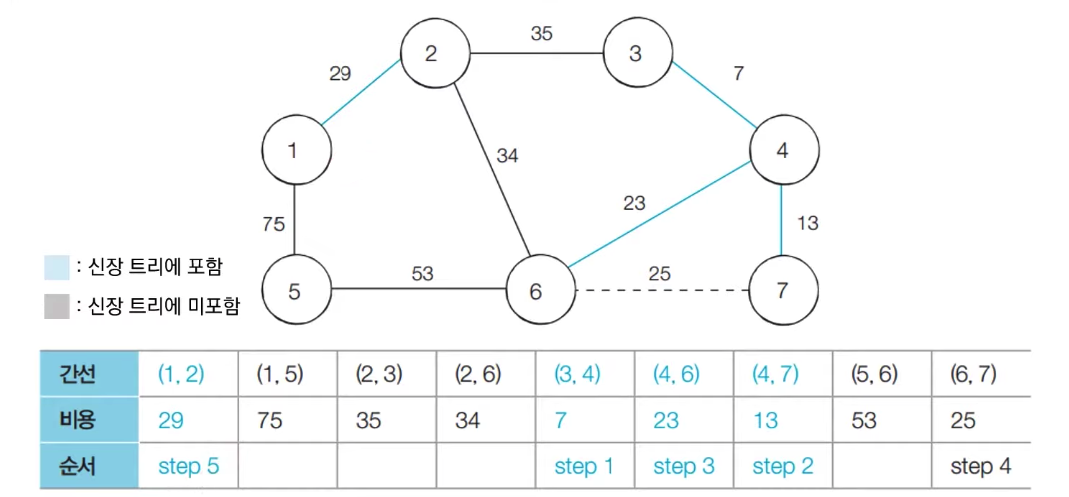
-
[step 6] : 아직 처리하지 않은 간선 중에서 비용이 가장 작은 간선인 (2, 6)를 선택하여 처리한다.
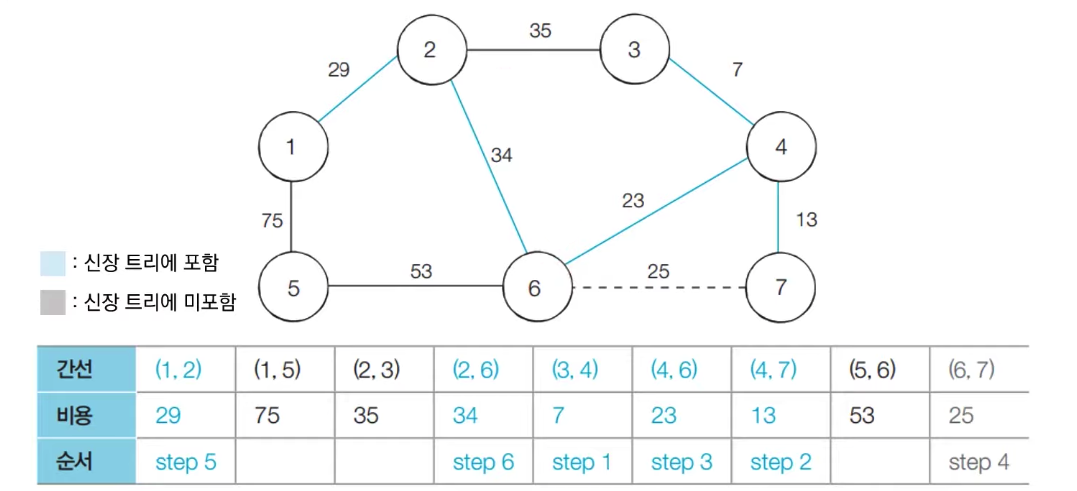
-
[step 7] : 아직 처리하지 않은 간선 중에서 비용이 가장 작은 간선인 (2, 3)를 선택하여 처리한다. 이 때, 2, 3번 노드는 같은 집합에 속해있기 때문에 해당 간선을 넣게 된다면 사이클이 발생하게 된다. 따라서 해당 간선은 그냥 무시하고 넘어간다.
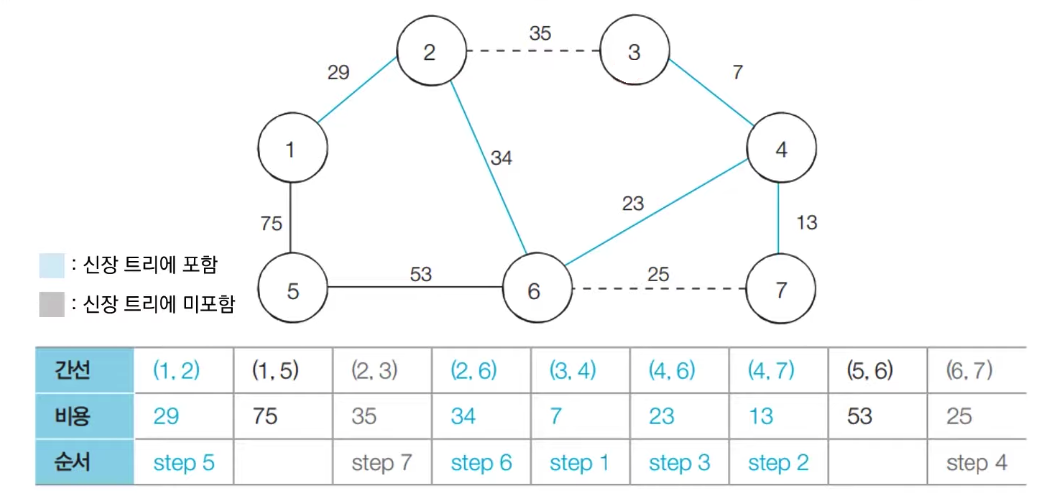
-
[step 8] : 아직 처리하지 않은 간선 중에서 비용이 가장 작은 간선인 (5, 6)를 선택하여 처리한다.

-
[step 9] : 아직 처리하지 않은 간선 중에서 비용이 가장 작은 간선인 (1, 5)를 선택하여 처리한다. 이 때, 1, 5번 노드는 같은 집합에 속해있기 때문에 해당 간선을 넣게 된다면 사이클이 발생하게 된다. 따라서 해당 간선은 그냥 무시하고 넘어간다.
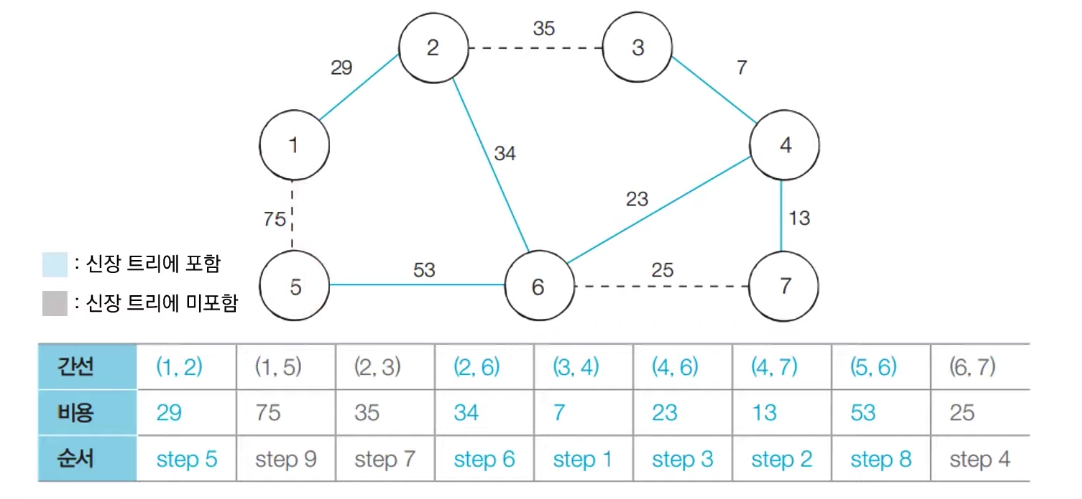
-
[알고리즘 수행 결과]
크루스칼 알고리즘 소스코드
# 특정 원소가 속한 집합을 찾기
def find_parent(parent, x):
# 루트 노드를 찾을 때까지 재귀함수를 호출
if parent[x] != x:
parent[x] = find_parent(parent, parent[x])
return parent[x]
# 두 원소가 속한 집합을 합치기
def union_parent(parent, a, b):
a = find_parent(parent, a)
b = find_parent(parent, b)
# 노드의 번호가 작은 번호가 부모 테이블에 저장되도록
if a < b:
parent[b] = a
else:
parent[a] = b
# 노드의 개수와 간선의 개수 입력 받기
V, E = map(int, input().strip().split())
# 각 원소의 부모를 저장하는 부모 테이블 초기화하기
parent = [0] * (V+1)
# 모든 간선을 담을 리스트와 최종 비용을 담을 변수
edges = []
result = 0
# 부모 테이블 상에서 부모를 자기 자신으로 초기화
for i in range(1, V+1):
parent[i] = i
# 모든 간선에 대한 정보를 입력 받기
for _ in range(E):
a, b, cost = map(int, input().strip().split())
edges.append([cost, a, b])
# 비용 순으로 오름차순 정렬하기
# 튜플이나 리스트의 형태로 append를 하는 경우 첫 번째 원소를 기준으로 정렬이 수행됨
edges.sort()
# 간선을 하나씩 확인
for edge in edges:
cost, a, b = edge
# 사이클을 발생시키지 않는다면?
if find_parent(parent, a) != find_parent(parent, b):
union_parent(parent, a, b)
result += cost
print(result)
- 크루스칼 알고리즘은 간선의 개수가 E개일 때,
O(E log E)의 시간 복잡도를 가진다.- 크루스칼 알고리즘에서 가장 많은 시간이 요구되는 부분은 간선을 비용을 기준으로 오름차순 정렬을 수행하는 부분이다.
- 표준 라이브러리(
sort)를 이용해서 E개의 간선 데이터를 정렬하기 위한 시간 복잡도는O(E log E)이다.
