
🏷️컬렉션 프레임워크 - Map 소개1
Map
Map은 키-값 쌍을 저장하는 자료 구조이다.
키는 맵 내에서 유일해야 한다. 그리고 키를 통해 빠른 검색이 가능하다.
키는 중복될 수 없지만 값은 중복될 수 있다.
Map은 순서를 유지하지 않는다.
컬렉션 프레임워크 - Map
public class MapMain {
public static void main(String[] args) {
Map<String, Integer> studentMap = new HashMap<>();
studentMap.put("studentA", 90);
studentMap.put("studentB", 80);
studentMap.put("studentC", 80);
studentMap.put("studentD", 100);
System.out.println(studentMap);
Integer result = studentMap.get("studentD");
System.out.println("result = " + result);
System.out.println("keySet 활용");
Set<String> strings = studentMap.keySet();
for (String key : strings) {
Integer value = studentMap.get(key);
System.out.println("key = " + key + ", value = " + value);
}
System.out.println("entrySet 활용");
Set<Map.Entry<String, Integer>> entrySet = studentMap.entrySet();
for (Map.Entry<String, Integer> entry : entrySet) {
String key = entry.getKey();
Integer value = entry.getValue();
System.out.println("key = " + key + ", value = " + value);
}
System.out.println("values 활용");
Collection<Integer> values = studentMap.values();
for (Integer value : values) {
System.out.println("values = " + value);
}
}
}키 목록 조회
Map의 키는 중복을 허용하지 않는다. Map의 모든 키 목록을 조회하려면 keySet()을 사용하면 된다.
키-값 목록 조회
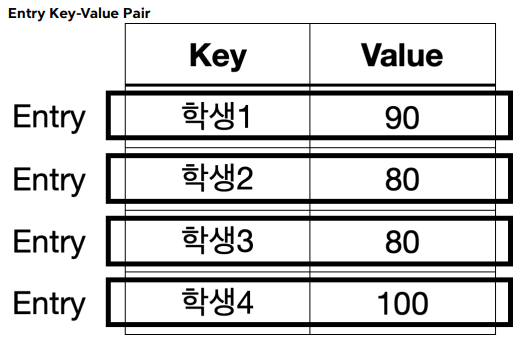
Map은 키와 값을 보관하는 자료 구조이다. 따라서 키와 값을 하나로 묶을 수 있는 방법이 필요하다. 이 때, Entry를 사용한다. Entry는 키-값의 쌍으로 이루어진 간단한 객체다. Entry는 Map 내부에서 키와 값을 함께 묶어 저장할 때 사용한다.
🏷️컬렉션 프레임워크 - Map 소개2
public class MapMain2 {
public static void main(String[] args) {
Map<String, Integer> studentMap = new HashMap<>();
studentMap.put("studentA", 90);
System.out.println(studentMap);
studentMap.put("studentA", 100);
System.out.println(studentMap);
boolean containsKey = studentMap.containsKey("studentA");
System.out.println("containsKey = " + containsKey);
studentMap.remove("studentA");
System.out.println(studentMap);
}
}public class MapMain3 {
public static void main(String[] args) {
Map<String, Integer> studentMap = new HashMap<>();
studentMap.put("studentA", 50);
System.out.println(studentMap);
// 해당 키값이 Map에 존재하지 않는 경우에만 추가할 수 있도록
if (!studentMap.containsKey("studentA")) {
studentMap.put("studentA", 100);
}
System.out.println(studentMap);
// 없는 경우에만 입력이 되도록
studentMap.putIfAbsent("studentA", 100);
studentMap.putIfAbsent("studentB", 100);
System.out.println(studentMap);
}
}🏷️컬렉션 프레임워크 - Map 구현체
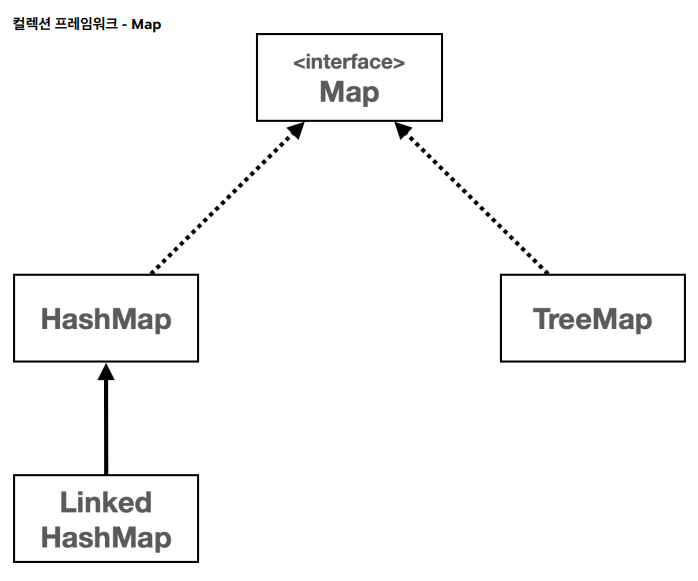
자바의 Map 인터페이스는 키-값 쌍을 저장하는 자료 구조이다. Map은 인터페이스이기 때문에, 직접 인스턴스를 생성할 수는 없고, 대신 Map 인터페이스를 구현한 여러 클래스를 통해 사용할 수 있다. 대표적으로 HashMap, TreeMap, LinkedHashMap이 있다.
Map vs Set
Map의 키는 중복을 허용하지 않고 순서를 보장하지 않는다. Map의 키가 Set과 같은 구조이다. Map은 키를 중심으로 동작한다. 값은 키 옆에 따라 붙은 것 뿐이다. 키에 값만 추가해주면 Map이 된다. 이 둘의 차이점은 값을 가지는지의 여부에 있을 뿐이다.
- ✔️HashMap
- 구조 :
HashMap은 해시를 사용해서 요소를 저장한다. 키값은 해시 함수를 통해 해시 코드로 변환되고 이 해시 코드는 데이터를 저장하고 검색하는데 사용된다. - 특징 : 삽입, 삭제, 검색 작업은 해시 자료 구조를 사용하므로
O(1)의 시간 복잡도를 가진다. - 순서 : 순서를 보장하지 않는다.
- 구조 :
- ✔️LinkedHashMap
- 구조 : 연결 리스트를 사용하여 삽입 순서 또는 최근 접근 순서에 따라 요소를 유지한다.
- 특징 : 입력 순서에 따라 순회가 가능하다.
HashMap과 같지만 입력 순서를 링크로 유지해야 하므로 조금 더 무겁다. - 성능 :
HashMap과 유사하게 대부분의 작업은O(1)의 시간 복잡도를 가진다. - 순서 : 입력 순서를 유지한다.
- ✔️TreeMap
- 구조 :
TreeMap은 레드-블랙 트리를 기반으로 한 구현 - 특징 : 모든 키는 자연 순서 또는 생성자에 제공된
Comparator에 의해 정렬된다. - 성능 :
get,put,remove와 같은 주요 작업들은O(log N)의 시간 복잡도를 가진다. - 순서 : 키는 정렬된 순서로 저장된다.
- 구조 :
public class JavaMapMain {
public static void main(String[] args) {
run(new HashMap<String, Integer>());
run(new LinkedHashMap<String, Integer>());
run(new TreeMap<String, Integer>());
}
private static void run(Map<String, Integer> map) {
System.out.println("map = " + map.getClass());
map.put("C", 10);
map.put("B", 20);
map.put("A", 30);
map.put("1", 40);
map.put("2", 50);
Set<String> keySet = map.keySet();
Iterator<String> iterator = keySet.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
System.out.println();
}
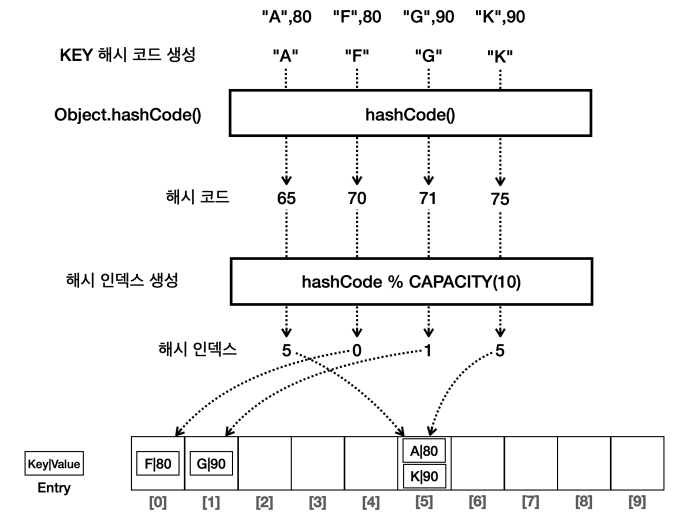
}자바 HashMap의 작동 원리
- 키를 사용해서 해시 코드를 생성한다.
- 키뿐만 아니라 값을 추가로 저장해야 하기 때문에
Entry를 사용한다. - 이 때,
Map의 키로 사용되는 객체는hashCode(),equals()를 반드시 구현해야 한다.
🏷️스택(Stack) 자료 구조
스택의 작동 원리 - 후입선출(LIFO)
나중에 넣은 것을 가장 먼저 빼는 것을 후입선출이라 하며 이런 자료 구조를 스택이라고 한다.
public class StackMain {
public static void main(String[] args) {
Stack<Integer> stack = new Stack<>();
stack.push(1);
stack.push(2);
stack.push(3);
System.out.println(stack);
System.out.println("stack.peek() = " + stack.peek());
System.out.println("stack.pop() = " + stack.pop());
System.out.println("stack.pop() = " + stack.pop());
System.out.println("stack.pop() = " + stack.pop());
System.out.println(stack);
}
}❗Stack 클래스를 사용하지 말 것
자바의
Stack클래스는 내부에서Vector라는 자료 구조를 사용한다. 이 자료구조는 자바 1.0에 개발된 것으로 지금은 사용되지 않고 하위 호환을 위해 존재한다. 지금은 더 빠르고 좋은 자료구조가 많다. 따라서Vector를 사용하는Stack도 사용하지 않는 것을 권장한다. 대신에 이후 설명할Deque를 사용하는 것이 좋다.
🏷️큐(Queue) 자료구조
큐의 작동 원리 - 선입선출(FIFO)
후입선출과 반대로 가장 먼저 넣은 것이 가장 먼저 나오는 것을 말하며 이런 자료 구조를 큐라고 한다.
public class QueueMain {
public static void main(String[] args) {
Queue<Integer> queue = new ArrayDeque<>();
queue.offer(1);
queue.offer(2);
queue.offer(3);
System.out.println(queue);
System.out.println("queue.peek() : " + queue.peek());
System.out.println("queue.poll() : " + queue.poll());
System.out.println("queue.poll() : " + queue.poll());
System.out.println("queue.poll() : " + queue.poll());
System.out.println();
}
}
🏷️데크(Deque) 자료구조
데크의 작동 원리
Deque는 Double Ended Queue의 약자로 양쪽 끝에서 요소를 추가하거나 제거할 수 있다. 데크는 큐와 스택의 기능을 모두 포함하고 있어 매우 유연한 자료구조이다.
public class DequeMain {
public static void main(String[] args) {
Deque<Integer> deque = new ArrayDeque<>();
deque.offerFirst(1);
System.out.println(deque);
deque.offerFirst(2);
System.out.println(deque);
deque.offerLast(3);
System.out.println(deque);
deque.offerLast(4);
System.out.println(deque);
System.out.println("deque.peekFirst() : " + deque.peekFirst());
System.out.println("deque.peekLast() : " + deque.peekLast());
System.out.println("pollFirst : " + deque.pollFirst());
System.out.println("pollFirst : " + deque.pollFirst());
System.out.println("pollLast : " + deque.pollLast());
System.out.println("pollLast : " + deque.pollLast());
System.out.println(deque);
}
}데크의 구현체 - ArrayDeque, LinkedList
이 둘 중에 ArrayDeque가 모든 면에서 우수하다. ArrayDeque는 원형 큐 자료구조를 사용하는데 덕분에 앞, 뒤, 입력 모두 O(1)의 성능을 제공한다. 물론 앞서 배운 LinkedList 역시 앞, 뒤, 입력 모두 O(1)의 성능을 제공한다. 이론적으로 LinkedList가 삽입, 삭제가 자주 발생하는 환경에서 더 효율적일 수 있지만, 현대 컴퓨터 시스템의 메모리 접근 패턴, CPU 캐시 최적화 등을 고려할 때 배열을 사용하는 ArrayDeque가 실제 사용 환경에서 더 나은 성능을 보여주는 경우가 많다.
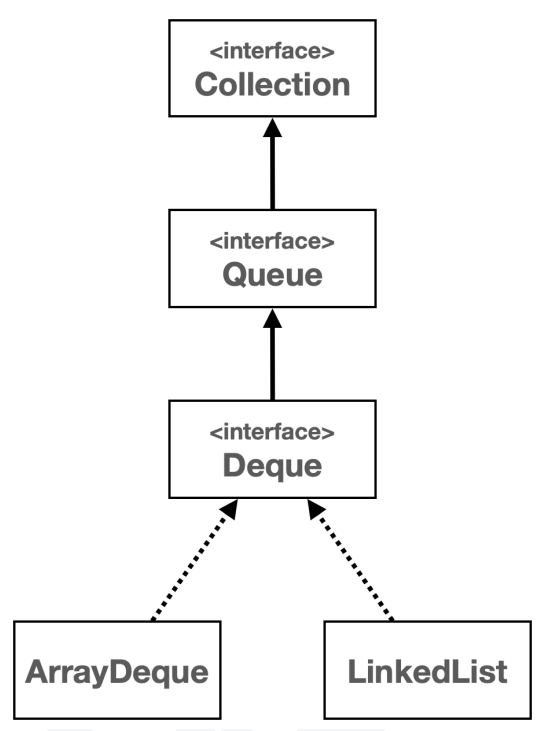
🏷️Deque와 Stack, Queue
Stack 자료구조가 필요하다면 Deque에 ArrayDeque 구현체를 사용하자.
Deque 인터페이스는 Queue 인터페이스를 상속받기 때문에 Queue의 기능이 필요하다면 Queue 인터페이스를 사용하고 더 많은 기능을 사용하고자 한다면 Deque 인터페이스를 사용하면 된다.
