
🏷️자바가 제공하는 Set1 - HashSet, LinkedHashSet
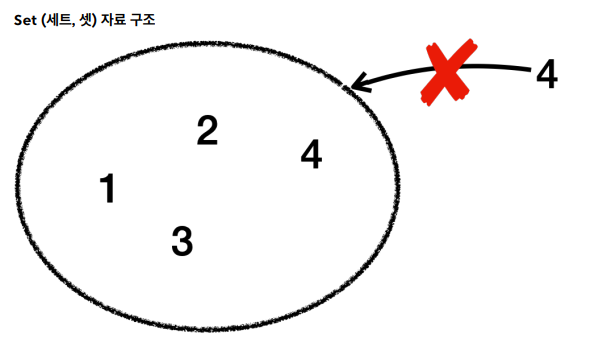
Set(세트, 셋) 자료 구조
컬렉션 프레임워크 - Set
Collection 인터페이스
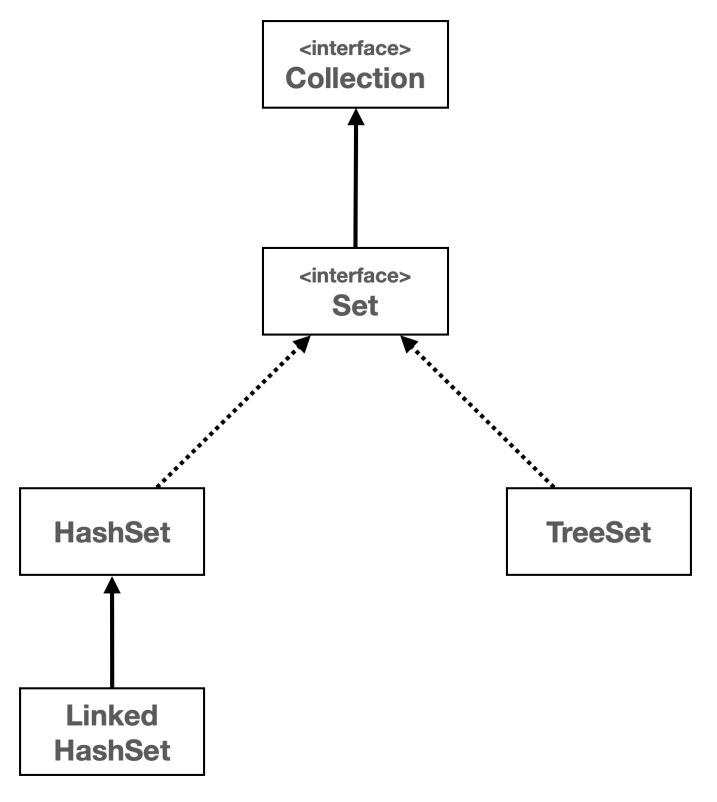
Collection 인터페이스는 자바에서 다양한 컬렉션, 즉 데이터 그룹을 다루기 위한 메서드를 정의한다. Collection 인터페이스는 List, Set, Queue와 같은 다양한 하위 인터페이스와 함께 사용되며, 이를 통해 데이터를 리스트, 세트, 큐 등의 형태로 관리할 수 있다.
Set 인터페이스
자바의 Set 인터페이스는 중복을 허용하지 않는 유일한 요소의 집합을 나타낸다. 즉, 어떤 요소도 같은 Set 내에 두 번 이상 나타날 수 없다. Set은 수학적 집합 개념을 구현한 것으로 순서를 보장하지 않으며, 특정 요소가 집합에 있는지 여부를 확인하는데 최적화되어있다.
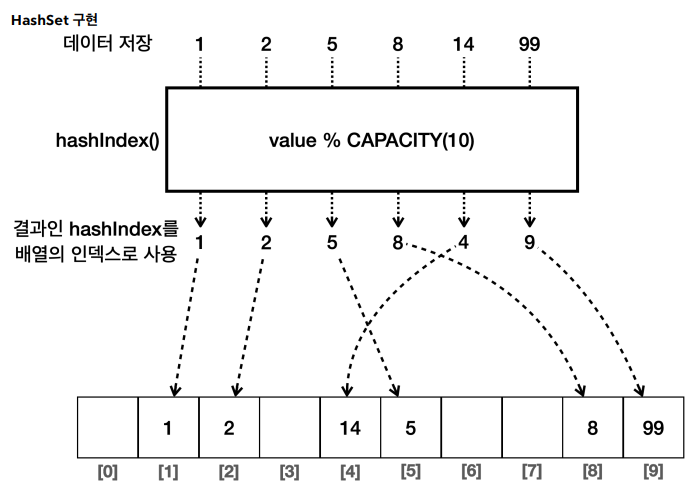
- ✔️HashSet
- 구현 : 해시 자료 구조를 사용해서 요소를 저장한다.
- 순서 : 요소들은 특정 순서 없이 저장된다. 즉, 요소를 추가한 순서를 보장하지 않는다.
- 시간 복잡도 :
HashSet의 주요 연산(추가, 삭제, 검색)은 평균적으로O(1)의 시간 복잡도를 가진다. - 용도 : 데이터의 유일성만 중요하고, 순서가 중요하지 않은 경우에 적합하다.
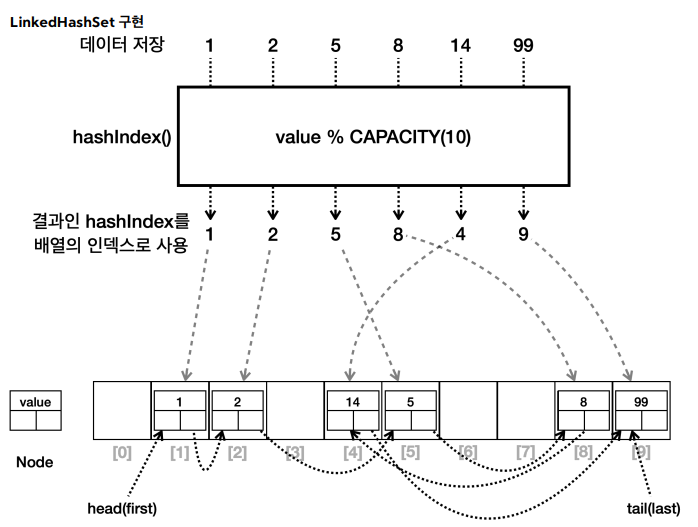
- ✔️LinkedHashSet
- 구현 :
LinkedHashSet은HashSet에 연결리스트를 추가해서 요소들의 순서를 유지한다. - 순서 : 요소들은 추가된 순서대로 유지한다. 즉, 순서대로 조회 시 요소들이 추가된 순서대로 반환된다.
- 시간 복잡도 :
LinkedHashSet도HashSet과 마찬가지로 평균O(1)시간 복잡도를 가진다. - 용도 : 데이터 유일성과 함께 삽입 순서를 유지해야 할 때 적합하다.
- 참고 : 연결 링크를 유지해야 하기 때문에 내부 구조가 복잡하며
HashSet보다는 조금 더 무겁다.
- 구현 :
🏷️자바가 제공하는 Set2 - TreeSet
- ✔️TreeSet
- 구현 :
TreeSet은 이진 탐색 트리를 개선한 레드-블랙 트리를 내부에서 사용한다. - 순서 : 요소들은 정렬된 순서대로 저장된다. 순서의 기준은 비교자로 변경할 수 있다.
- 시간 복잡도 : 주요 연산들은
O(log N)의 시간 복잡도를 가진다.HashSet보다는 느리다. - 용도 : 데이터들을 정렬된 순서대로 유지하면서 집합의 특성을 유지할 때 사용한다. 예를 들어, 범위 검색이나 정렬된 데이터가 필요한 경우에 유용하다. 참고로 입력된 순서가 아니라 데이터 값의 순서이다.
- 구현 :
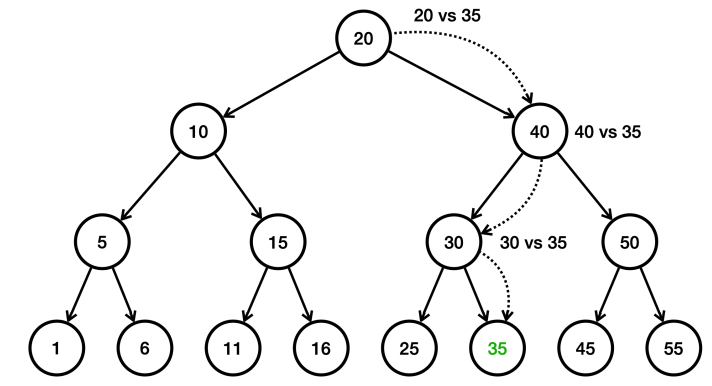
총 15개의 데이터가 들어 있다. 여기서 숫자 35를 검색한다고 가정하면 총 4번의 계산이 수행된다. 이것은 O(N)인 리스트 검색보다는 빠르고 O(1)인 해시 검색보다는 느리다.
이진 탐색 트리와 성능
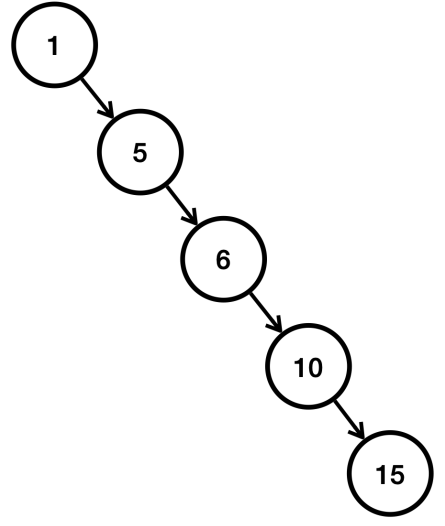
이렇게 오른쪽으로 치우친 편향 이진 트리의 경우 데이터의 수만큼 15를 찾는다고 하면 5번 검색을 해야 한다. 최악의 경우 O(N)이 나온다.
이진 탐색 트리 개선
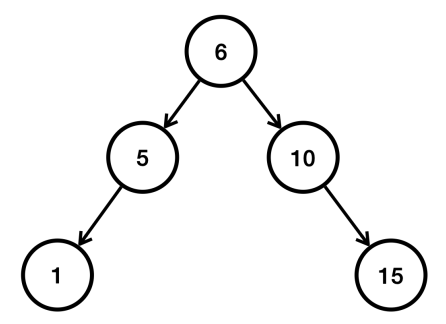
앞서 중간에 있는 6을 기준으로 다시 정렬한다. AVL 트리, 레드-블랙 트리 같은 균형을 맞추는 다양한 알고리즘이 존재한다. 자바의 TreeSet은 레드-블랙 트리를 사용해서 균형을 지속해서 유지한다. 따라서 최악의 경우에도 O(log N)의 성능을 제공한다.
이진 탐색 트리의 핵심은 입력 순서가 아니라 데이터의 값을 기준으로 정렬해서 보관한다는 점이다. 따라서 정렬된 순서로 데이터를 차례로 조회할 수 있다.
🏷️자바가 제공하는 Set3 - 예제
public class JavaSetMain {
public static void main(String[] args) {
run(new HashSet<String>());
run(new LinkedHashSet<String>());
run(new TreeSet<String>());
}
private static void run(Set<String> set) {
System.out.println("set = " + set.getClass());
set.add("C");
set.add("B");
set.add("A");
set.add("1");
set.add("2");
Iterator<String> iterator = set.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next() + " ");
}
System.out.println();
}
}🏷️자바가 제공하는 Set4 - 최적화
- ✔️자바 HashSet의 최적화
- 최적화
- 해시 기반 자료 구조를 사용하는 경우 통계적으로 입력한 데이터의 수가 배열 크기를 75% 정도 넘어가면 해시 인덱스가 자주 충돌한다. 따라서 75%가 넘어가면 성능이 떨어지기 시작한다.
- 해시 충돌로 같은 해시 인덱스에 들어간 데이터를 검색하려면 모두 탐색해야 한다. 따라서 성능이O(N)으로 좋지 않다.
- 하지만 데이터가 동적으로 추가되기 때문에 적절한 배열읰 크기를 정하는 것은 어렵다.
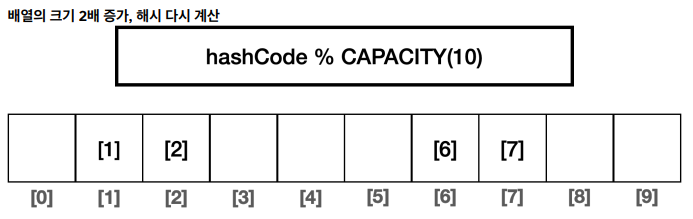
- 자바의HashSet은 데이터의 양이 배열 크기의 75%를 넘어가면 배열 크기를 2배로 늘리고 2배 늘어난 크기를 기준으로 모든 요소에 해시 인덱스를 다시 적용한다.
- 해시 인덱스를 다시 적용하는 시간이 걸리지만, 결과적으로 해시 충돌이 줄어든다.
- 자바HashSet의 기본 크기는 16이다.
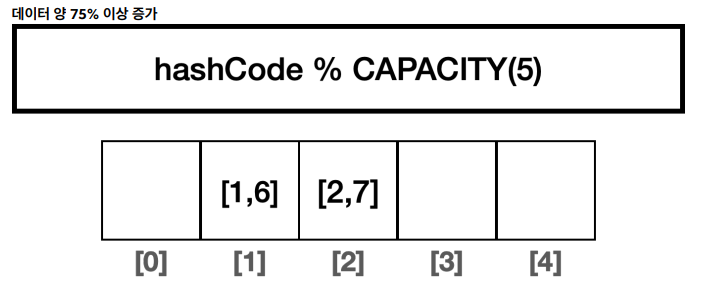
- 배열의 크기 2배 증가, 해시 다시 계산
- 데이터 양이 75% 이상이면 배열 크기를 2배로 증가하고 모든 데이터의 해시 인덱스를 커진 배열에 맞추어 다시 계산하는데 이를 재해싱이라고 한다.
- 인덱스 충돌 가능성이 줄어든다.
- 여기서 데이터가 다시 75% 이상 증가하면 다시 2배 증가와 재계산을 반복한다.
- 최적화
