Self-Guided Contrastive Learning for BERT Sentence Representations (ACL / 2021) paper review
paper review
Contribution
-
BERT의 Sentence representation의 quality를 improve하기 위하여 self-guidance를 이용하는 contrastive learning method를 제안하였다.
-
BERT는 sentence embedding으로 어떤 값을 사용하냐에 따라 많은 성능 차이가 있어 sentence embedding task에 있어 unstable함을 보이고 있다고 한다. (CLS token embedding, last layer의 max/ mean pooling 값 등)
-
이를 해결하기 위해data augmentation에 의존하지 않으며 [CLS] token embedding을 sentence representation으로 사용하도록 하는 self-supervised 방식으로 BERT를 fine-tuning하는 method를 제안하였다.
-
또한 이에 맞게 contrastive learning의 loss function으로 사용되는 NT-xent loss를 redesign하였다고 한다.
-
그리고 이러한 방식이 domain shift에 있어 robust하며 efficient 측면에 있어 efficient함을 보였다.
Contrastive Learning with Self-Guidance
-
data augmentation 같은 external procedure 없이 contrastive learning을 develop하는 것을 목표로 하였다.
-
NLP에서는 positive instance를 만드는 것에 많은 제약이 따른다. 그래서 이 논문에서는 BERT의 intermediate layer의 hidden representation을 sentence vector가 가까워져야하는 혹은 멀어져야하는 pivot으로 사용하였다고 한다.
Architecture
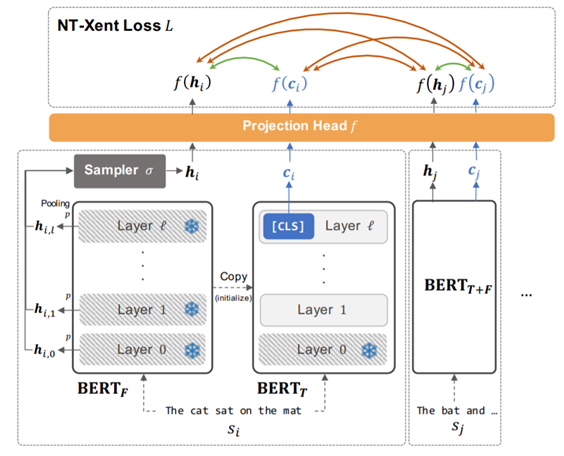
-
먼저 BERT를 clone하여 BERT-fixed와 BERT-tuned를 생성한다. BERT-fixed는 training하는 동안 training signal을 주기위해 fix되어 있는 부분이고, BERT-tuned는 더 나은 sentence embedding을 위하여 fine-tuning되는 부분이다. 그리고 BERT-tuned의 마지막 layer의 [CLS] vector를 sentence embedding으로 사용한다.
-
그리고 minibatch 내의 sample들을 BERT-fixed에 통과시켜 token level의 hidden representation을 계산한다. 그 후 hidden representation에 pooling을 씌운 후, sampler를 거쳐 최종적으로 하나의 hidden representation 값을 앞서 말한 pivot representation으로 사용한다. 여기서 pooling은 max pooling, sampler는 uniform sampler를 사용하였다고 한다.
-
그래서 앞에서 구한 sentence embedding ci 값과 hi 값을 이용해서 아래의 loss function을 계산한다.
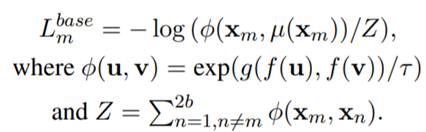
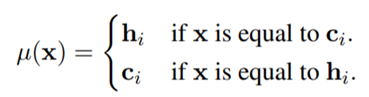
위 식에서 g function은 cos similarity를, f function은 mlp의 projection head를 의미한다. -
그리고 최종적으로 BERT-fixed와 BERT-tuned가 너무 멀어지는 것을 막기 위하여 regularizer loss를 추가하였다고 한다. 그래서 최종적으로 loss function은 아래와 같다.
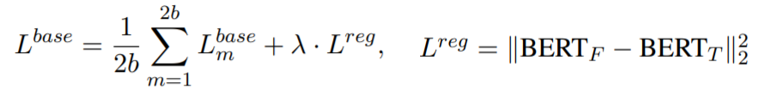
Learning Objective Optimization
- NT-xent loss function은 아래 4가지 요소로 구성되어 있다.
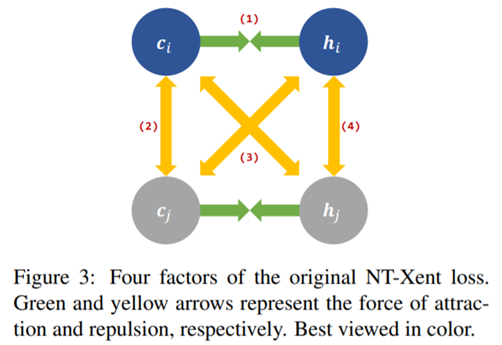

-
이 논문에서는 위의 4가지 요소가 BERT에서 sentence embedding을 학습하는 데에 다 필요한 것은 아니고 어떤 요소는 embedding 학습을 저해시키는 역할을 한다고도 말하였다. 따라서 이 논문에서는 이를 해결하기 위하여 NT-xent loss를 개선하였다.
-
첫번째로 hi를 optimizing해야하는 target대신 pivot으로서의 역할만 하고 ci에 더 집중할 수 있도록 loss function을 수정하였다.
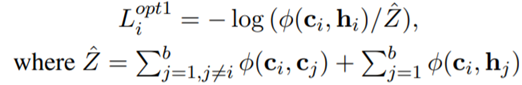
-
위와 같이 loss function을 수정하면서 (4)번 factor가 사라지게 되고, 추가로 (2)번 factor 역시 중요하지 않다고 언급하면서 (2)번 factor도 삭제하여 다음과 같이 한 번 더 function을 수정하였다.
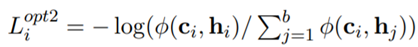
-
그리고 hidden representation에 multiple view를 주어 다양한 signal을 제공하기 위하여 다음과 같이 식을 수정하였다.
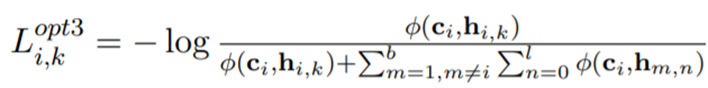
-
그래서 최종적으로 optimizing된 NT-xent loss는 다음과 같다.
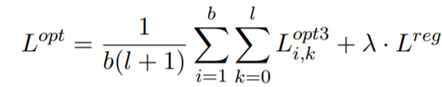
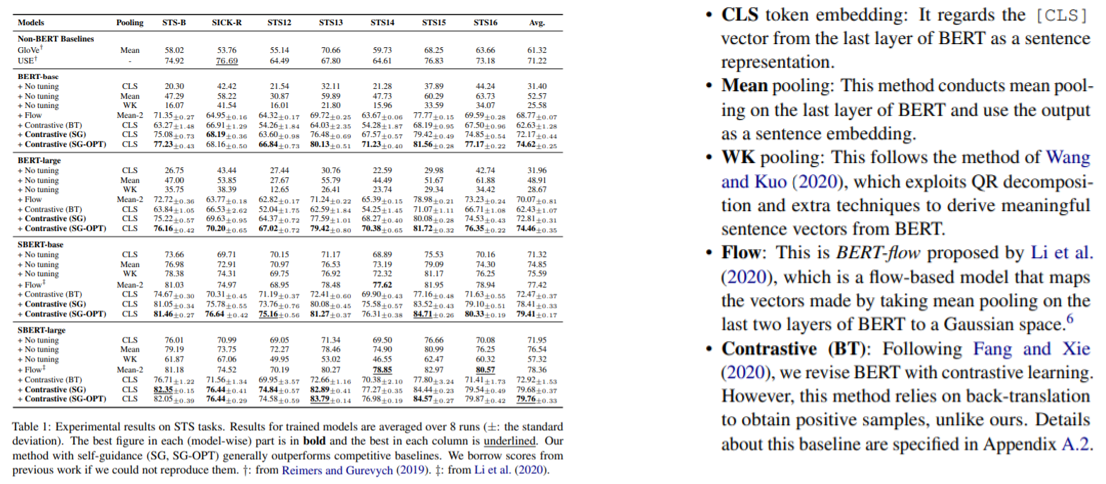
Experiments
- SG는 기존의 NT-xent loss를 사용한 version이고, SG-OPT는 optimizing한 NT-xent loss를 사용한 version이다.
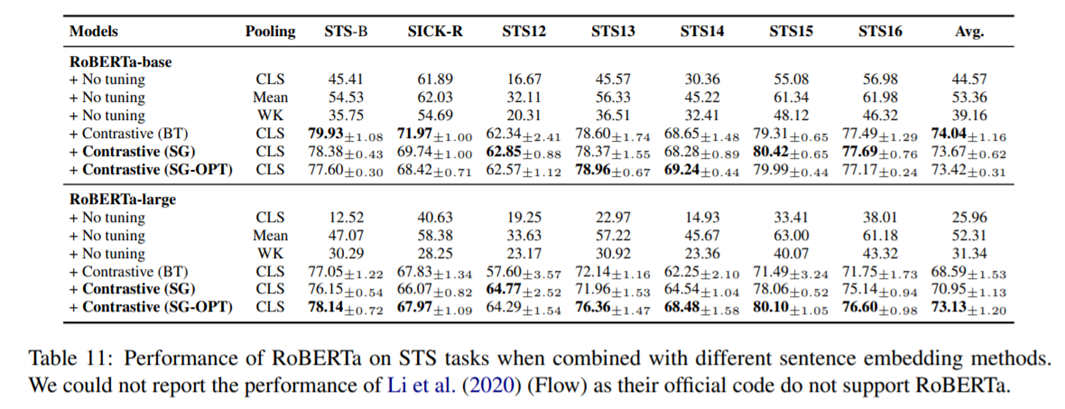
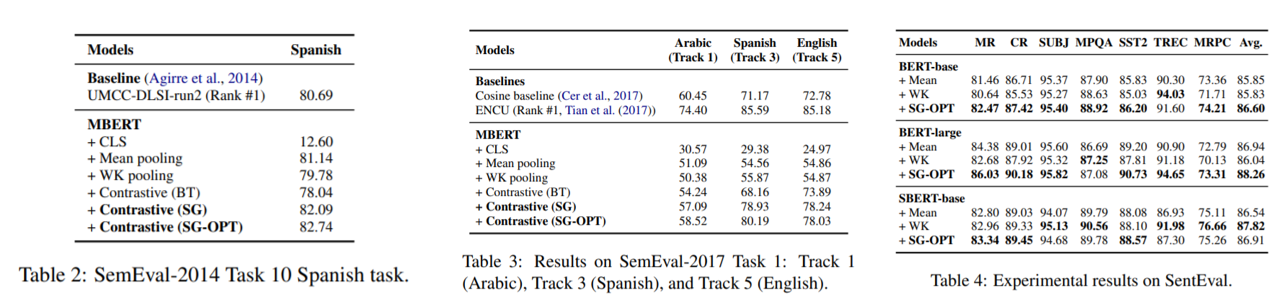
Analysis: Robustness to Domain shifts

- in-domain test와 out-of-domain test를 비교해보았을 때, flow method 대신에 SG-OPT를 사용하였을 때 더 적은 gap을 가지는 것을 확인할 수 있고 이를 통해 SG-OPT가 domain shift에 있어 robust함을 증명하고 있다.
Analysis: computational efficiency
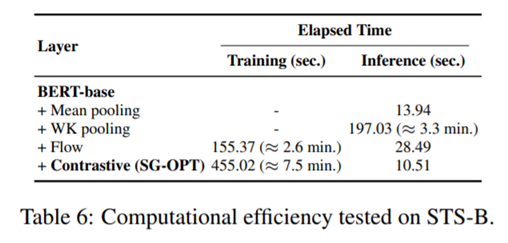
- 다른 method를 사용하였을 때보다 SG-OPT를 사용하였을 때 inference할 때 더 efficient한 것을 확인할 수 있다. 이 논문에서는 그러한 이유로 SG-OPT의 경우 다른 method와 달리 일단 training이 끝나면 pooling 등의 post-processing을 거치지 않기 때문이라고 설명하고 있다.
Analysis: Representation visualization
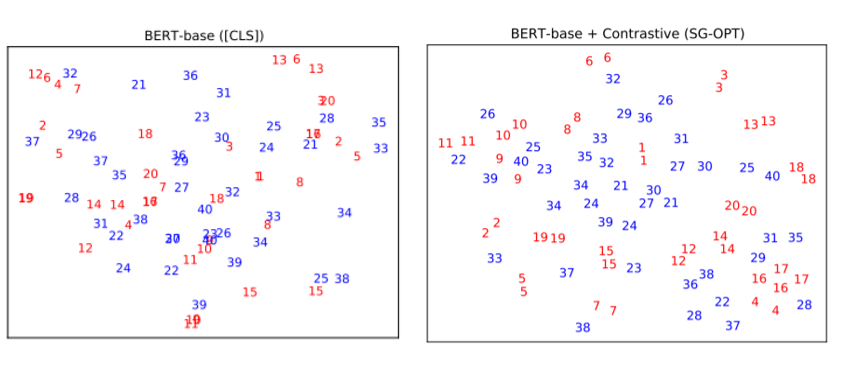
- 빨간 숫자들이 positive pair이고 파란 숫자들이 negative pair이다. BERT-base보다 BERT-base + SG-OPT가 숫자들이 vector space 내에 더 잘 align되어 있는 것을 확인할 수 있다.
Conclusion
-
이 논문에서는 BERT의 sentence embedding을 improve하기 위하여 contrastive learning method를 제안하고 있다.
-
SG method가 data augmentation 같은 external procedure 없이도 contrastive learning의 이점을 누릴 수 있고, 다른 baseline model들보다 higher-quality의 sentence representation을 생성하는 것에 성공하였음을 보여주고 있다.
-
또한 SG method는 inference 측면에 있어 efficient하고, domain shift에 있어 robust함을 보였다.
