단변량 분석 기본
- 단변량 분석은 변수로서 사용해도 괜찮은지를 파악하기 위해서 진행해야 한다.
- 변수의 형태는 1) 숫자형 2) 범주형으로 구분된다.
- 숫자형/범주형의 경우 곱셈 또는 덧셈과 같은 연산이 가능한지를 확인함으로써 구분할 수 있다.
- 숫자형일 때 사용하는 방법과 범주형일 때 사용하는 방법이 다름으로 구분을 잘 지어야 한다.
단변량 분석-숫자형 변수
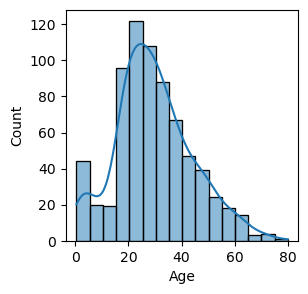
#1 정보 확인 : 기초통계량, 결측치, 정보 확인 df.describe() // df.info() // df['칼럼'].value_counts(dropna=False)와 그냥 ()으로 실행한거의 로우 길이를 보고 결측치가 있는지 확인. #2 시각화 : - 1 sns. 이용 : histplot, kdeplot, boxplot - 2 plt. 이용 : hist, plot - 특징 : - hist와 kde의 경우 y축의 값은 count // 밀도로 정해져 있음 - plot의 경우 y축의 지정(날짜, 지역...)이 필요 함. 1) histplot : - sns.histplot(x = '칼럼', data = data, bins = 16, kde = True) 이렇게 작성을 하고 bins와 kde는 생략 가능하다. - 히스토그램은 구간(bins)를 어떻게 잡는지에 따라 해석이 달라진다. - kde는 밀도를 보여준다. 밀도함수의 면적합은 1이며, 확률 추정이 가능하다. ex) sns.histplot(x = 'Age', data = titanic, bins = 16, kde = True)
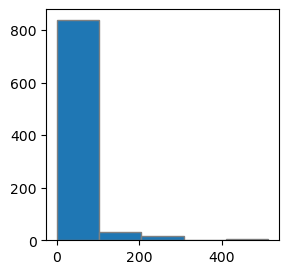
- sns가 아닌 plt.hist를 통해서 히스토그램의 결과를 저장하면 튜플로 저장되는데 빈도수와 구간값을 확인 할 수 있다. ex) hist1 = plt.hist('Age', data = titanic, bins = 16) print('빈도수 : ', hist1[0]) print('구간값 : ', hist1[1]) <출력> (array([838., 33., 17., 0., 3.]), array([ 0. , 102.46584, 204.93168, 307.39752, 409.86336, 512.3292 ]), <BarContainer object of 5 artists>) <class 'tuple'> -------------------------------------------------- 빈도수 : [838. 33. 17. 0. 3.] 구간값 : [ 0. 102.46584 204.93168 307.39752 409.86336 512.3292 ]
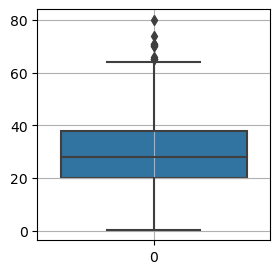
2) kdeplot : sns.kdeplot(x = '칼럼, data = data) 3) boxplot : - 결측치가 있으면 안됨. - 그래프에서 박스에 선은 중앙값을 나타냄 - 박스의 시작은 Q1분위 값 끝은 Q3분위 값임 즉 박스는 50%의 데이터를 포함 하고 있다. - IQR은 (Q3-Q1)*1.5의 길이로 왼쪽 오른쪽에 수염이 그려 진다. - 수염 밖에 있는 점인 데이터는 이상치이다. 제거가 아닌 분석이 필요한 데이터이다. ex) temp = titanic.loc[titanic['Age'].notnull()] sns.boxplot(x = 'Age', data = temp)
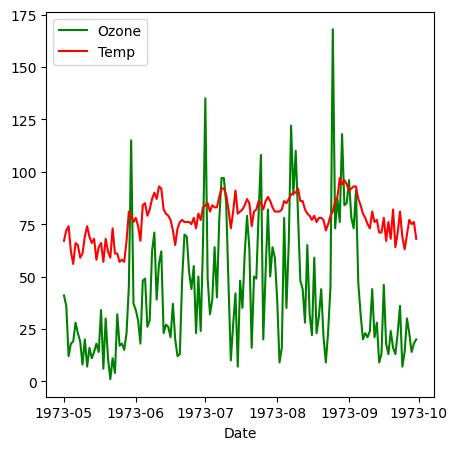
-2 plt. 이용 : plt.plot('칼럼1', '칼럼2', data = data) ex) air['Date'] = pd.to_datetime(air['Date']) # 날짜 형식으로 변환 plt.plot('Date', 'Ozone', 'g-', data = air, label = 'Ozone') plt.plot('Date', 'Temp', 'r-', data = air, label = 'Temp') plt.xlabel('Date') plt.legend() plt.show() ###### x축의 값이 같다면 한 그래프에 겹쳐져서 출력 됨. 구분해주기 위해서 label과 plt.legend() 해준거임.
단변량 분석-범주형 변수
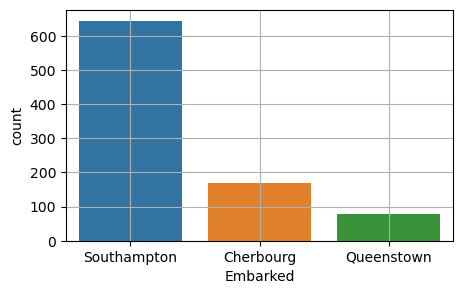
# 정보 확인 : 범주별 빈도수와 비율, 결측치 확인 빈도수 확인 : titanic['Embarked'].value_counts() 비율 확인 : titanic['Embarked'].value_counts(normalize=True) 결측치 확인 : titanic['Embarked'].value_counts(dropna=False) # 시각화 : sns.countplot, y축 값은 count 지정임. ex) sns.countplot(x = 'Embarked', data = titanic, order = ['Southampton', 'Cherbourg', 'Queenstown' ]) #### x축의 순서 지정 가능 함.

큐브가 필요하다...!!!