import matplotlib.pyplot as plt
distances, indexes = knr.kneighbors([[50]])
# 훈련 데이터 산점도
plt.scatter(X_train, X_test)
# 50cm 데이터의 이웃 3개
plt.scatter(X_train[indexes], X_test[indexes], marker='D')
# 50cm 1.033kg 데이터 위치
plt.scatter(50, 1033, marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()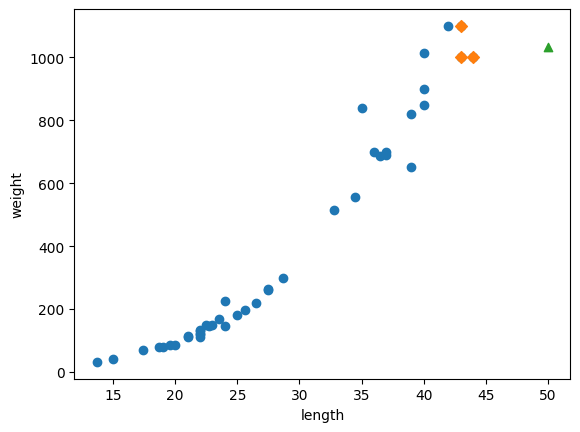
실제로 예측하려고 했던 값 50cm와 가까운 데이터 3개를 추출하고 평균을 내면
import numpy as np
np.mean(X_test[indexes])
# np.float64(1033.3333333333333)예측했던 값 1.033kg과 같다.
그리고 이것은 50보다 높은 어떤 수를 넣어도 같은 결과가 나온다.
선형 회귀
선형회귀는 대표적은 회귀 알고리즘이다.
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
# 모델 훈련
lr.fit(X_train, X_test)
# 예측
print(lr.predict([[50]]))
# [1241.83860323]K-최근접이웃에 비해 무게를 높게 예측했다.
그래프를 그림으로 나타내면 다음과 같다.
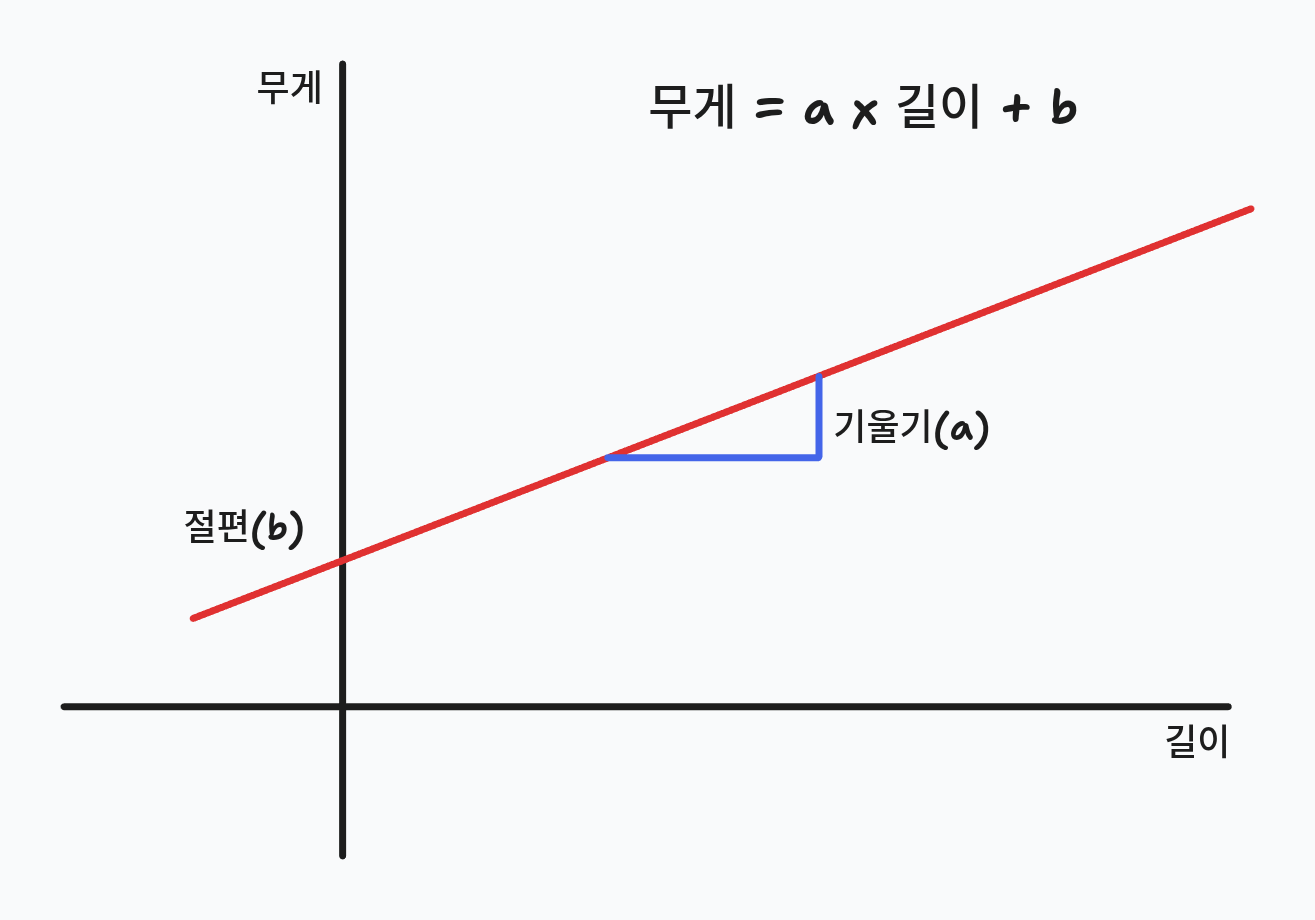
직선의 그래프는
고 여기서 x는 길이를, y는 무게를 나타낸다.
그리고 학습된 LinearRegression 클래스에는 계산된 a(기울기)와 b(절편)이 있다.
print(lr.coef_, lr.intercept_)
# [39.01714496] -709.0186449535477여기서 기울기(계수 또는 가중치)는 coefficient, 절편은 intercept라고 한다.
plt.scatter(X_train, X_test)
# 길이 15 ~ 50까지의 1차 방정식 그래프 그리기
plt.plot([15,50], [15*lr.coef_+lr.intercept_, 50*lr.coef_+lr.intercept_], color='green')
# 50cm, 1.2418.kg의 위치
plt.scatter(50, 1241.8, marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
그래프를 보면 방정식 선의 시작이 0kg 보다 밑에서부터 시작한다.
점수
print(lr.score(X_train, X_test)) # 훈련 데이터
# 0.939846333997604
print(lr.score(y_train, y_test)) # 테스트 데이터
# 0.8247503123313558정확도를 계산해 보면 과대적합, 과소적합이 일어난 것으로 보인다.
다항 회귀
실제로 훈련 데이터의 산점도를 보면
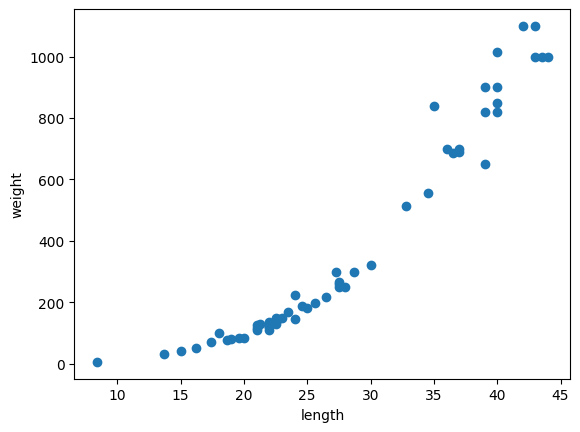
이렇게 직선보다는 약간 2차원 그래프처럼 구부러진 형태다.
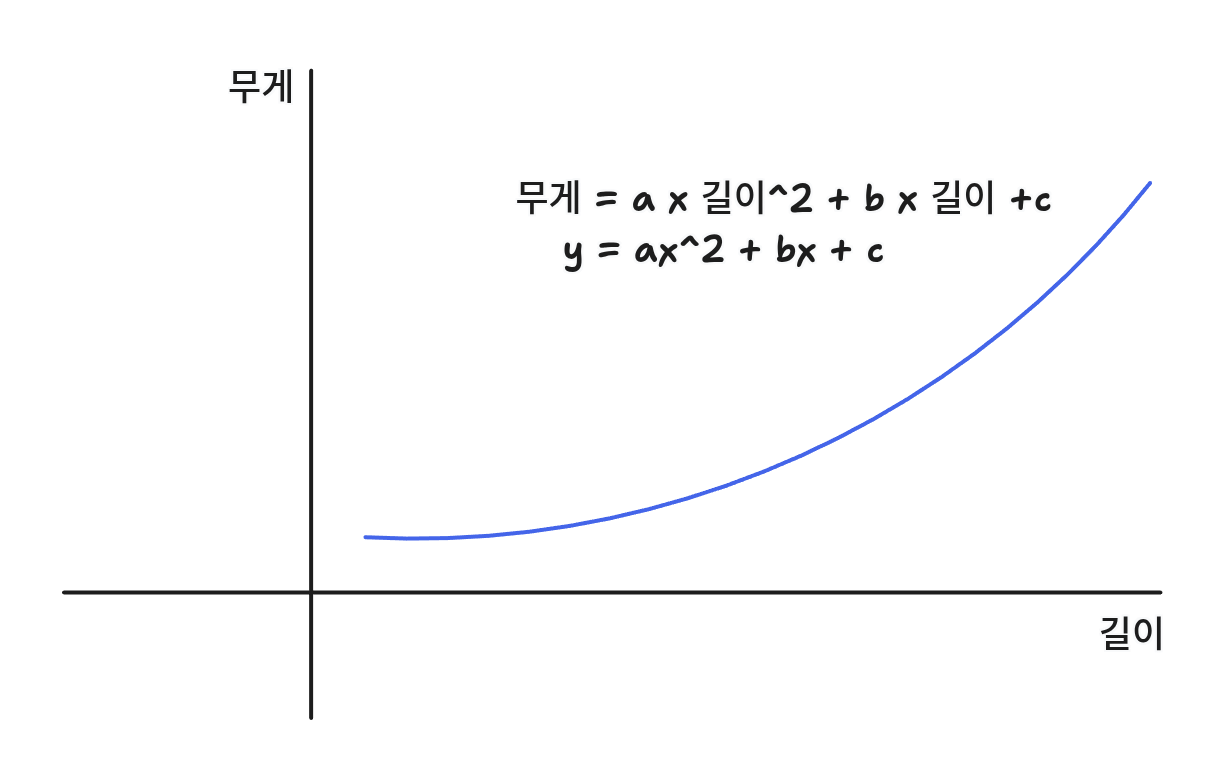
그래서 이번에는 최적의 직선이 아닌 최적의 곡선을 찾아보려고 한다.
그리고 이런 2차 방정식을 그리려면 길이를 제곱한 데이터가 추가되어야 한다.
X_train_poly = np.column_stack((X_train ** 2, X_train))
y_train_poly = np.column_stack((y_train ** 2, y_train))
print(X_train_poly.shape, y_train_poly.shape)
# (42, 2) (42, 2)기본 데이터에 제곱한 데이터를 추가했기 때문에 열이 2개가 되었다.
이제 이 데이터로 학습하고 예측해보면
lr = LinearRegression()
lr.fit(X_train_poly, X_test)
lr.predict([[50 ** 2, 50]])
# [1573.98423528]
print(lr.coef_, lr.intercept_)
# [ 1.01433211 -21.55792498] 116.0502107827827이렇게 이전보다 더 높은 값을 예측했다.
이런 방식을 다항식(polynomial)이라고 부르면 다항식을 사용한 선형 회귀를 다항 회귀라고 한다.
이제 이 값으로 그래프를 그려보았다.
point = np.arange(15, 50)
plt.scatter(X_train, X_test)
plt.plot(point, 1.01*point**2 - 21.6*point+116.05)
plt.scatter(50, 1574, marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()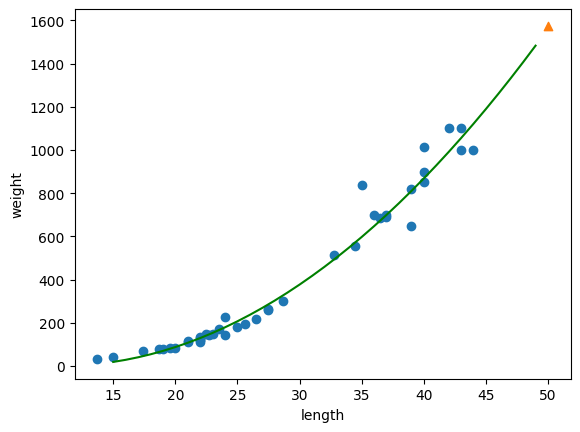
이전 그래프 보다 좀 더 정확한 그래프가 나왔다.
점수를 확인해 보면
print(lr.score(X_train_poly, X_test)) # 0.9706807451768623
print(lr.score(y_train_poly, y_test)) # 0.9775935108325122
코딩 공부하는 사람