Web이 아닌 코드로
사진이 잘 나온것을 확인했다.
하지만 서비스를 위해서는 이것을 코드로 구현해야 한다.
찾아보니 diffusers라는 패키지가 존재했고 다운로드 했다.
pip install diffusers이 diffusers는 Hugging Face에 있는 파일로 이미지를 생성할 수 있는 것 같다.
diffusers에 대한 사용 방법은 여기에 있다.
코드로 구현하기
시험해 보기
먼저 시험삼아 이미지를 뽑아보자.
from diffusers import StableDiffusionPipeline
# 모델 불러오기
pipe = StableDiffusionPipeline.from_pretrained("Model Name", torch_dtype=torch.float16).to('cuda')모델은 Hugging Face에서 원하는 모델을 검색하고 해당 모델의 이름을 복사해서 넣어준다.
ex) dreamlike-art/dreamlike-anime-1.0
그리고 우리가 WebUI에서 가져온 프롬프트를 넣어준다.
image = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
num_inference_steps=25,
width=600,
height=800
).images[0]
image.save('1111.png', 'png')뽑아보면,

이미지가 잘 출력되는 것을 확인 할 수 있다.
동영상 이미지로 바꾸기
나는 사진 한 장을 사용하는 것이 아닌, 동영상을 사용하는 것이기 때문에, 동영상 한 프레임 마다 적용시켜줘야 한다.
그래서 먼저 동영상을 프레임 단위로 분리시켜 줘야 한다.
# 동영상 불러오기
vidcap = cv2.VideoCapture('1234.mp4')그리고 해당 동영상의 총 프레임(추출되는 이미지 수)를 가져온다.
파일 이름을 지정할 때 사용한다.
# 총 프레임 수
length = int(vidcap.get(cv2.CAP_PROP_FRAME_COUNT))그리고 이미지를 저장한다.
# 각 프레임을 이미지로 저장하기
success,image = vidcap.read()
count = 0
pbar = tqdm(total=length)
while success:
cv2.imwrite("./imgs/%06d.jpg" % count, image)
success,image = vidcap.read()
count += 1
pbar.update(1)
pbar.close()사진에서 pose, depth 추출
사진에서 인물만 바뀌어야 하기 때문에, 해당 인물의 크기(?)와 포즈가 같아야 한다.
그것을 위해 ControlNet의 depth와 openpose를 이용한다.
Depth란?
해당 그림의 전체적은 모습과, 깊이감을 알아야 할 때 사용한다.
인물을 바꾸는데는 Canny를 사용해도 되지만, 생김새도 바뀌기 때문에 depth로 충분하다고 생각했다.


더 자세한 내용은 여기에서 확인할 수 있다.
Openpose란?
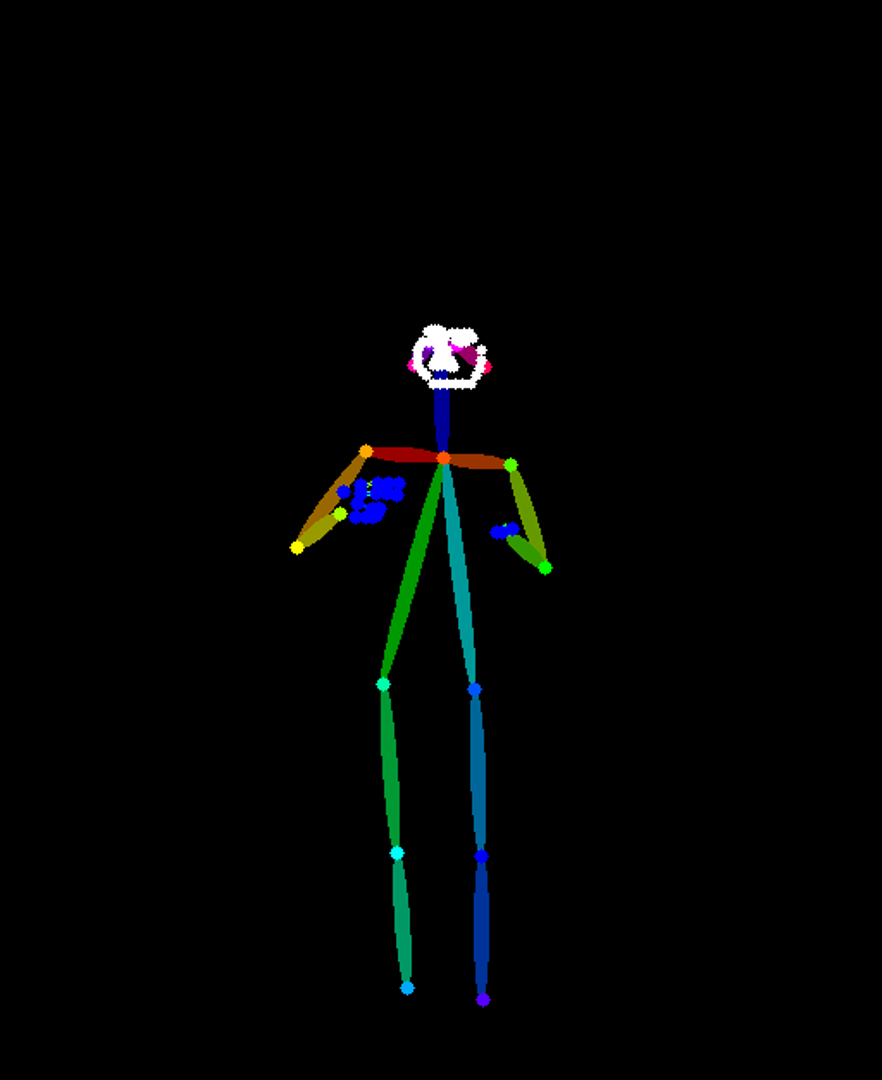
사진 속 인물에서 포즈를 추출하는 것을 말한다.
포즈를 추출하고 추출한 이미지를 넣으면, 같은 포즈의 다른 이미지를 만들 수 있다.


자세한 내용은 여기에서 확인 할 수 있다.
코드로 구현하기
Pose 가져오기
먼저 ControlNet 모델을 가져온다.
model = OpenposeDetector.from_pretrained("lllyasviel/ControlNet")미리 분리해둔 이미지를 변수에 불러온다.
from diffusers.utils import load_image
img_files = glob('./imgs/*')
img_files.sort()
imgs = [load_image(img) for img in img_files]참고로 glob()은 가지고 올 때 정렬되지 않으므로 정렬을 해 줘야 한다.
하지 않으면, 나중에 이미지를 합칠때 서로 다른 이미지 이기 때문에 이상한 그림이 나오거나 할 수 있다.
그리고 모델에 이미지를 넣어주면 된다.
img = model(INPUT)끝!
만약, 포즈에서 손가락, 얼굴까지 가져오고 싶다면, INPUT 뒤에 hand_and_face=True를 넣어주면 된다.
참고로
Depth 가져오기
depth 모델을 가져와 주고 이미지에 depth를 적용한다.
# Depth
# 필요한 라이브러리들을 import 합니다.
from transformers import pipeline
from diffusers import ControlNetModel
from PIL import Image
import numpy as np
import torch
from tqdm import tqdm
import glob
# depth-estimation task를 위해 depth_estimator pipeline을 로드합니다.
depth_estimator = pipeline('depth-estimation')
# ControlNetModel을 로드합니다.
controlnet = ControlNetModel.from_pretrained(
"lllyasviel/sd-controlnet-depth", torch_dtype=torch.float16
)
# 폴더 내의 모든 이미지를 불러옵니다.
images = glob('./imgs/*')
# 이미지들을 정렬합니다.
images.sort()
# 각 이미지에 대해 depth map을 계산합니다.
for id, image in tqdm(enumerate(images)):
# depth_estimator pipeline을 이용하여 depth map을 계산합니다.
image = depth_estimator(image)['depth']
# numpy array로 변환합니다.
image = np.array(image)
# 이미지의 채널을 3으로 바꾸기 위해 새로운 축을 추가합니다.
image = image[:, :, None]
# 새로운 축을 3개로 복사하여 이미지의 채널을 3으로 바꿉니다.
image = np.concatenate([image, image, image], axis=2)
# numpy array를 PIL Image로 변환합니다.
image = Image.fromarray(image)
# 이미지를 저장합니다.
image.save(f'./depth_imgs/depth_imgs{str(id).zfill(5)}.png')
결과