
✉️ 모든 문제 및 내용의 출처는 수제비 정보처리기사 실기 교재에 있습니다.
Ch1. 데이터베이스 기본
🤍 트랜잭션 정의
- 데이터베이스 시스템에서 하나의 논리적 기능을 정상적으로 수행하기 위한 작업의 기본 단위
🤍 트랜잭션의 특성 4가지 = 원, 일, 격, 영 [20년 1회, 21년 2회]
- 원자성(Atomicity)
- 트랜잭션을 구성하는 연산 전체가 모두 정상적으로 실행되거나 모두 취소되어야 하는 성질
- 트랜잭션의 연산 전체가 성공 또는 실패(All or Nothing)되어야 하는 성질
- 주요 기법 : Commit / Rollback, ,회복성 보장
- 일관성(Consistency)
- 시스템이 가지고 있는 고정요소는 트랜잭션 수행 전과 트랜잭션 수행 완료 후의 상태가 같아야 하는 성질
- 주요 기법 : 무결성 제약조건, 동시성 제어
- 격리성=고립성(Isolation)
- 동시에 실행되는 트랜잭션들이 서로 영향을 미치지 않아야 한다는 성질
- 주요 기법: Isolation Level
- Read Uncommitted
- Read Committed
- Repeatable Read
- Serializable
- 영속성(Durability)
- 성공이 완료된 트랜잭션의 결과는 영속적으로 데이터베이스에 저장되어야 하는 성질
- 주요 기법 : 회복기법
🤍 트랜잭션 제어 3가지 = 커, 롤, 체 [20년 2회]
- 커밋(COMMIT) : 트랜잭션을 메모리에 영구적으로 저장하는 명령어 ➡️ 영구 저장
- 롤백(ROLLBACK) : 트랜잭션 내역을 저장 무효화시키는 명령어 ➡️ 오류 발생 시 오류 이전 특정 시점 상태로 되돌려주는 제어어
- 트랜잭션 처리 중 오류가 발생했을 때, 오류 이전의 특정 시점(SAVEPOINT, CHECKPOINT) 상태로 되돌려주는 제어어(명령어)
- 체크포인트(CHECKPOINT) : ROLLBACK을 위한 시점을 지정하는 명령어 ➡️ 롤백 시점 지정
🤍 DB 트랜잭션 연산 - 데이터 베이스 회복 기법 2가지 = Redo, Undo [22년 1회]
- Redo ➡️ 시작(Start) O, 완료(Commit) O → 작업 재실행
- 장애 발생 전 DB로 복구하는 기법으로 디스크에 저장된 로그를 분석하여 트랜잭션의 시작(Start)과 완료(Commit)에 대한 기록이 있는 트랜잭션들의 작업을 재실행
- Undo ➡️ 시작(Start) O, 완료(Commit) X → 이 트랜잭션이 작업한 변경 내용 모두 취소
- 장애 시 디스크에 저장된 로그를 분석해 트랜잭션의 시작(Start)은 있지만, 완료(Commit) 기록이 없는 트랜잭션들이 작업한 변경 내용을 모두 취소
🤍 로킹(Locking) [21년 2회]
- 같은 자원을 액세스하는 다중 트랜잭션 환경에서 DB의 일관성과 무결성을 유지하기 위해 트랜잭션의 순차적 진행을 보장하는 직렬화 기법
- 특징
- 데이터베이스, 파일, 레코드 등은 로킹 단위 될 수 있음
- 로킹 단위 작아지면 ➡️ 데이터베이스 공유도 증가, 로킹 오버헤드 증가
- 한꺼번에 로킹할 수 있는 객체 크기를 로킹 단위라 함
- 특징
🤍 IN 연산자 사용법 = 칼럼 IN(값1, 값2, …) [20년 2회]
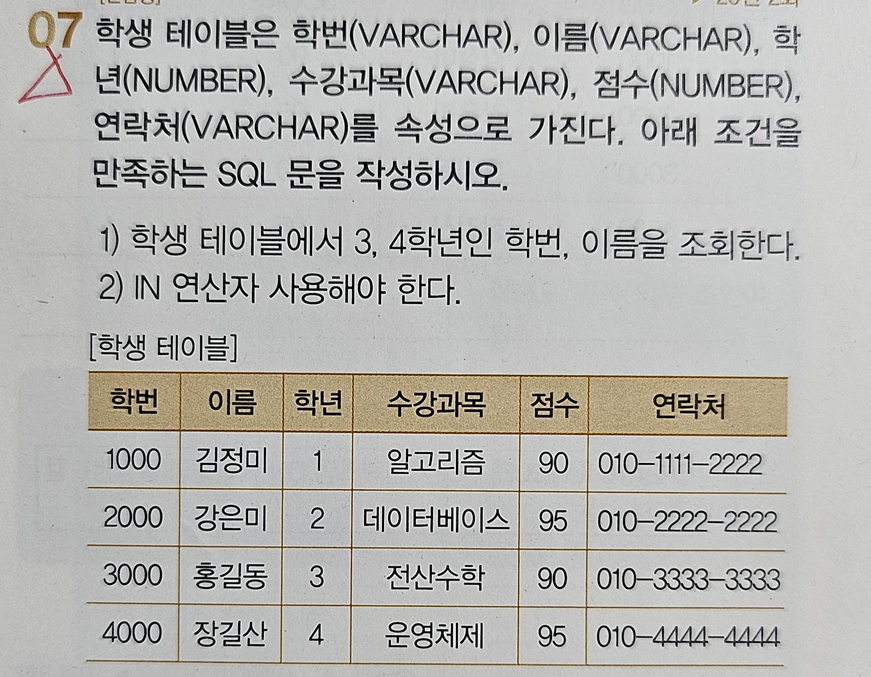
- 답 : SELECT 학번, 이름 FROM 학생 WHERE 학년 IN(3, 4);
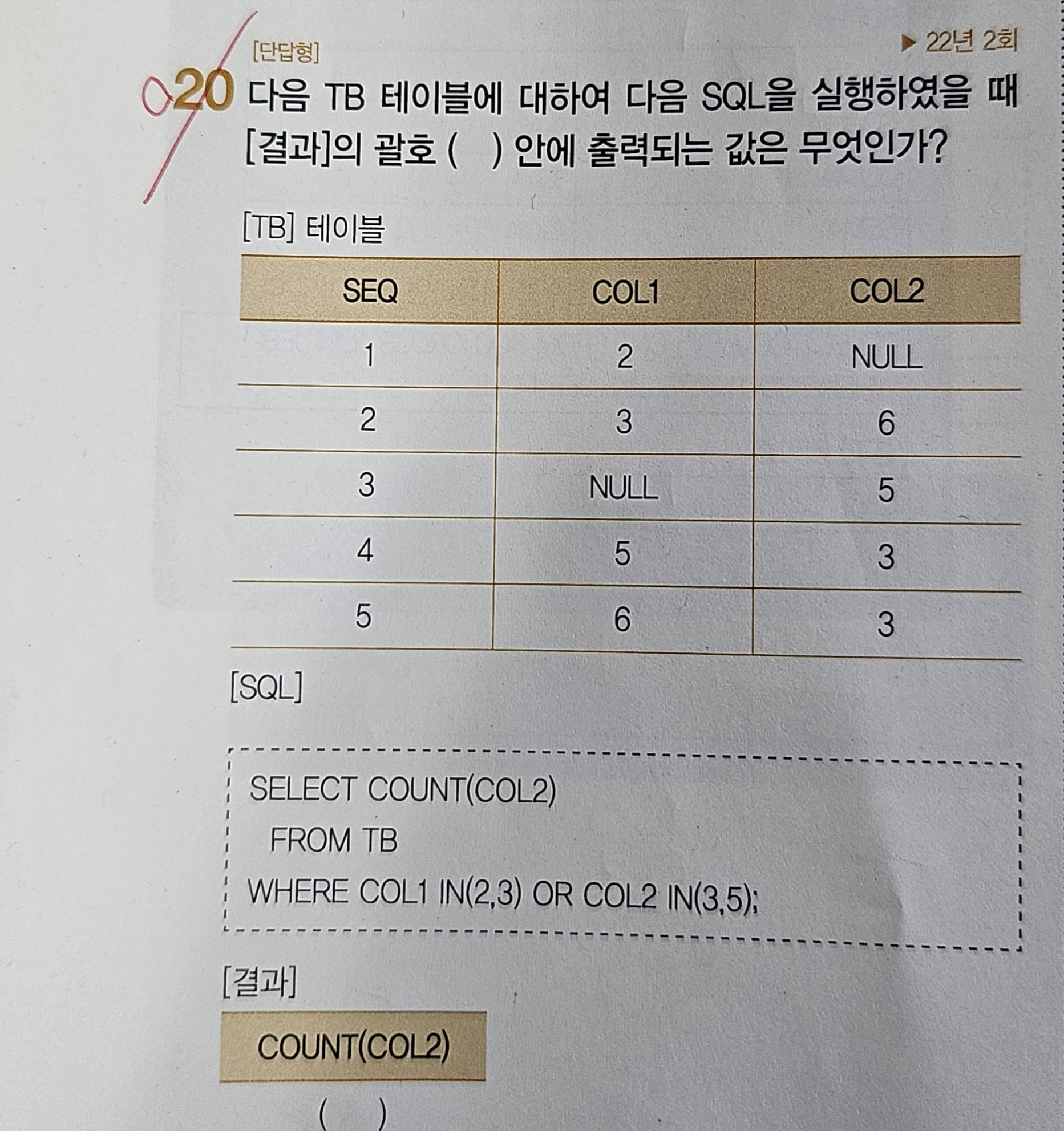
- 답 : 4
- 풀이 과정

- 풀이 과정
🤍 BETWEEN 사용법 = WHERE 칼럼 BETEEN 값1 AND 값2(값1, 값2, …) [20년 2회]
- 다음은 고객 테이블이다. 나이가 50살 이상이면서 59살 이하이고, 성별이 남자인 사람의 이름을 출력하는 쿼리를 작성하시오. (단, BETWEEN 구문을 사용해야 한다.) <고객> 테이블
이름 나이 성별 주소 홍길동 20 남 경기도 임꺽정 59 남 전라도 유관순 35 여 경상도 나혜석 41 여 충청도 이순신 33 남 강원도 SELECT 이름 FROM 고객 WHERE 나이 BETWEEN 50 AND 59 AND 성별 = '남';
🤍 DISTINCT(중복제거) [22년 3회]
- DISTINCT : 중복되는 칼럼을 제거함.
🤍 COUNT 연산자 = COUNT(칼럼명) | COUNT(*) [22년 2회]
- COUNT : 복수 행의 줄 수를 구하는 집계 함수
- COUNT(칼럼명) : NULL 제외 카운트
- COUNT(*) : NULL 포함 전부 카운트
- DISTINCT + COUNT 혼합 문제


- 답
1️⃣ 3
2️⃣ 4 - 풀이 과정


🤍 데이터베이스 회복 기법 3가지 = 로(지,즉), 체, 그 [20년 4회]
- 로그 기반 회복 기법
- 지연 갱신 회복 기법 : 트랜잭션이 완료되기 전까지 데이터베이스에 기록하지 않음
- 즉각 갱신 회복 기법 : 트랜잭션 수행 중 갱신 결과르 바로 DB에 반영
- 체크포인트 회복 기법
- 장애 발생 시 검사점 이후에 처리된 트랜잭션에 대해서만 장애 발생 이전의 상태로 복원
- 그림자 페이징 회복 기법
- 데이터베이스 트랜잭션 수행 시 복제본 생성해 데이터베이스 장애 시 이걸로 복구
DDL(데이터 정의어)
🤍 DDL(데이터 정의어) 5가지 = 도, 스, 테, 뷰, 인 [20년 3회]
- DDL 대상
- 도메인 : 하나의 속성이 가질 수 있는 원자값들의 조합
- 스키마 : 데이터베이스의 구조, 제약조건 등의 정보를 담고 있는 기본적 구조
- 테이블 : 데이터 저장 공간
- 뷰 : 하나 이상의 물리 테이블에서 유도되는 가상 테이블
- 인덱스 : 검색을 빠르게 하기 위한 데이터 구조
🤍 스키마 3가지 = 외, 개, 내
- 외부 스키마 → 사용자, 개발자 관점 DB 논리적 구조
- 사용자나 개발자의 관점에서 필요로 하는 데이터베이스의 논리적 구조
- 사용자 뷰를 나타내고, 서브 스키마로 불림.
- 개념 스키마 → DB 전체 논리적 구조
- 데이터베이스의 전체적인 논리적 구조
- 전체적 뷰를 나타냄
- 개체 간 관계, 제약 조건, 접근 권한, 무결성, 보안에 대해 정의
- 내부 스키마 → 물리적 저장 장치 관점 DB 구조
- 물리적 저장 장치의 관점에서 보는 데이터베이스 구조
- 실제로 데이터베이스에 저장될 레코드의 형식을 정의하고 저장 데이터 항목의 표현 방법, 내부 레코드의 물리적 순서 등 표현
🤍 데이터베이스 파일 구조 3가지 = 순, 인, 해 [21년 3회]
- 순차 방법 물리적 순서 = 논리적 순서 되게 순차 저장
- 레코드들의 물리적 순서가 레코드들의 논리적 순서와 같게 순차적으로 저장하는 방법
- 인덱스 방법 주소 기반 레코드 접근 <키값, 주소>
- 인덱스가 가리키는 주소를 따라 원하는 레코드에 접근할 수 있도록 하는 방법
- <키값, 주소> 쌍으로 구성
- 해싱 방법 키값을 해시함수에 대입해 계산한 결과 주소로 사용
- 키값을 해시 함수(Hash Function)에 대입시켜 계산한 결과를 주소로 사용하여 레코드에 접근할 수 있게 하는 방법
🤍 DDL 명령어 4가지 = CREATE, ALTER, DROP, TRUNCATE
- 생성
- CREATE
- 수정
- ALTER
- 삭제
- DROP : 테이블 자체 삭제
- TRUNCATE : ‘내용’만 삭제
테이블
🤍 테이블 생성 CREATE TABLE + 제약조건(CHECK)
CREATE TABLE 테이블명
(
컬럼명 데이터타입 PRIMARY KEY, -- 기본키 설정
컬럼명 데이터타입 FOREIGN KEY REFERENCES 참조테이블(기본키), -- 외래키 설정
컬럼명 데이터타입 UNIQUE,
컬럼명 데이터타입 NOT NULL,
컬럼명 데이터타입 CHECK(조건식) -- 제약 조건 설정
컬럼명 데이터타입 DEFAULT 값
);
-- 실제 예시
CREATE TABLE Employees
(
EmployeeID INT PRIMARY KEY,
DepartmentID INT FOREIGN KEY REFERENCES Departments(DepartmentID),
FirstName VARCHAR(50) NOT NULL,
LastName VARCHAR(50) NOT NULL,
Email VARCHAR(100) UNIQUE,
Salary DECIMAL(10,2) CHECK(Salary >= 0),
HireDate DATE DEFAULT GETDATE()
);
- EmployeeID
- INT 데이터 유형으로 기본 키로 설정
- DepartmentID
- INT 데이터 유형으로 외래 키로 설정
- Departments 테이블의 DepartmentID를 참조함.
- FirstName, LastName
- 각각 최대 길이가 50인 VARCHAR 데이터 유형으로 설정되며 NOT NULL 제약 조건이 적용됨.
- Email
- 최대 길이가 100인 VARCHAR 데이터 유형으로 설정, 고유해야함(UNIQUE 제약 조건).
- Salary
- 최대 10자리의 숫자
- 소수점 둘째 자리까지 포함하는 DECIMAL 데이터 유형으로 설정
- Salary가 0보다 작을 수 없도록 CHECK 제약 조건이 적용됨
- HireDate
- DATE 데이터 유형으로 설정
- GETDATE() 함수를 사용하여 현재 날짜를 기본값으로 설정- 예시) 사람이라는 테이블 생성
- 사람이라는 테이블에는 이름, 성별이라는 컬럼이 있는데, 이름은 VARCHAR(10) 데이터 타입을 가지고, 성별은 CHAR(1) 데이터 타입을 가지고 있음.
- 성별은 추가로 ‘M’과 ‘F’ 값만 가질 수 있도록 제약 조건을 걸고자 함.
CREATE TABLE 사람
(
이름 VARCHAR(10)
성별 CHAR(1) CHECK(성별='M' OR 성별='F)
);🤍 테이블에 컬럼 추가 ALTER TABLE 테이블명 ADD
- ALTER TABLE 테이블명 ADD 칼럼명 데이터타입 [제약조건];
-- BirthDate 컬럼은 DATE 데이터 유형으로 설정되며 NOT NULL 제약 조건 적용
ALTER TABLE Employees ADD BirthDate DATE NOT NULL;
-- 사원 테이블에 VARCHAR(11) 타입으로 전화번호라는 컬럼을 추가한다면?
ALTER TABLE 사원 ADD 전화번호 VARCHAR(11);🤍 테이블 출력 SELECT
- 1️⃣ 다음 테이블은 학생 테이블의 일부이다. 해당 테이블에서 전공만 출력하는 쿼리를 쓰시오. 단, 전공명은 중복되지 않아야 한다. [학생]
이름 전공 생년월일 이완용 일본어학과 580607 박영효 일본어학과 610612 기철 몽골어학과 840101 안중근 국문학과 790902 SELECT DISTINCT 전공 FROM 학생;
- 2️⃣ 다음은 학생 테이블의 일부이다. ‘이’ 씨 성을 가진 사람의 학번을 출력하는 쿼리를 작성하시오. [학생]
이름 전공 학번 이완용 일본어학과 580607 박영효 일본어학과 610612 기철 몽골어학과 840101 안중근 국문학과 790902 SELECT 학번 FROM 학생 WHERE 이름 LIKE '이%'; - 3️⃣ 학생 테이블에서 주소 칼럼이 있다. 주소 컬럼이 NULL이 아닌 주소값을 출력하는 쿼리
SELECT 주소 FROM 학생 WHERE 주소 IS NOT NULL;
🤍 DELETE 문법 [20년 3회]
- 튜플을 삭제하는 경우 DELETE 명령어 사용
- DELETE FROM 테이블명 WHERE 조건;
- 예시) 학생 테이블에서 이름이 민수인 튜플을 삭제하는 SQL문
- DELETE FROM 학생 WHERE 이름 = ‘민수’;
- 주의점
- DELETE는 해당하는 행 자체를 삭제하기 때문에 FROM 앞에 *을 하지 않음!!!!
🤍 테이블 관련 용어 6가지 = 튜플(행), 애트리뷰트(열), 식별자, 카디널리티, 차수, 도메인
- 튜플, 행(ROW) 가로
- 테이블 내 행을 의미, 레코드라고도 함.
- 튜플은 릴레이션에서 같은 값 가질 수 X
- 튜플의 개수 = 카디널리티
- 애트리뷰트, 열(Column) 세로
- 테이블 내 열을 의미
- 열의 개수 = Degree
- 식별자(Identifier)
- 여러 개의 집합체를 담고 있는 관계형 데이터베이스에서 각각의 구분할 수 있는 논리적 개념
- 카디널리티(Cardinality)
- 튜플, 행(가로)의 개수
- 차수(Degree)
- 애트리뷰트, 열(세로)의 개수
- 도메인(Domain)
- 하나의 애트리뷰트(열)가 취할 수 있는 같은 타입의 원자값들의 집합
뷰
🤍 뷰 생성 = CREATE VIEW 뷰이름 AS [조회쿼리];
- 사원 테이블에 사번, 업무, 이름, 생년월일, 성별, 입사일이라는 칼럼이 있을 때 사원 테이블에서 성별 값이 ‘M’을 가진 사번, 이름으로 생성된 ‘사원뷰’라는 이름의 뷰 생성
CREATE VIEW 사원뷰 AS -- CREATE VIEW 뷰이름 AS SELECT 사번,이름 FROM 사원 -- [조회쿼리]; WHERE 성별 = 'M';
🤍 CREATE INDEX 문법 [20년 2회]
- CREATE [UNIQUE] INDEX 인덱스명 ON 테이블명(컬럼명1, 컬럼명2,…);
- 예시) STUDENT 테이블의 NAME 속성에 IDX_NAME 이름으로 인덱스 생성하는 SQL문
- CREATE INDEX IDX_NAME ON STUDENT(NAME);
- 예시) STUDENT 테이블의 NAME 속성에 IDX_NAME 이름으로 인덱스 생성하는 SQL문
DML(데이터 조작어)
🤍 DML 명령어 4가지 = SELECT, INSERT, UPDATE, DELETE
- SELECT(조회) : 테이블 내 칼럼에 저장된 데이터 조회
- INSERT(삽입) : 테이블 내 칼럼에 데이터 추가
- UPDATE(갱신) : 테이블 내 칼럼에 저장된 데이터 수정
- DELETE(삭제) : 테이블 내 칼럼에 저장된 데이터 삭제
🤍 있는 칼럼에 데이터 추가 = INSERT INTO 테이블명(칼럼) VALUES(데이터);
- INSERT INTO 테이블명(칼럼1, 칼럼2, …) VALUES(데이터1, 데이터2,…)
다음은 테이블 및 컬럼명에 대한 명세이다. 사원명이 홍길동, 나이가 24, 급여가 300인 직원을 직원 테이블에 삽입하는 쿼리 - 테이블명 : EMPLOYEE(직원 테이블) - 칼럼명 : NAME(사원명), AGE(나이), SALARY(급여) INSERT INTO EMPLOYEE(NAME, AGE, SALARY) VALUES('홍길동', 24, 300);
- 칼럼 자체를 추가 한다면 → ALTER TABLE 테이블명 ADD 컬럼명 데이터타입 [제약조건];
- 있는 칼럼에 데이터를 추가 한다면 → INSERT INTO 테이블명(칼럼) VALUES(데이터);
🤍 JOIN 컬럼 ON 조건 [21년 2회]
-
조인 조건으로 ON을 사용
-
예시) [학생정보] 테이블과 [학과정보] 테이블을 조인하려고 한다. 밑줄 친 곳을 채워 알맞은 쿼리를 작성하시오.

- 1️⃣ ON
- 2️⃣ 학과
- 즉, 다음과 같음.
- SELECT 학생정보.학번, 학생정보.이름, 학과정보.학과, 학과정보.지도교수 FROM 학생정보 JOIN 학과정보 ON 학생정보.학과=학과정보.학과;
- SELECT 학생정보.학번, 학생정보.이름, 학과정보.학과, 학과정보.지도교수 FROM 학생정보 JOIN 학과정보 ON 학생정보.학과=학과정보.학과;
-
🤍 JOIN 종류 5가지 = 내, 왼외, 오외, 완외, 교, 셀 [21년 2회]
- 내부조인 → JOIN 테이블 ON
- 같은 이름의 칼럼이 여러 테이블에 있을 경우 ‘별칭.컬럼명’ 형태로 명시
- INNER 키워드 : 생략해도 내부 조인은 가능
- 검색 조건 추가 시 ➡️ 조인된 값에서 ➡️ 해당 조건에 맞는 결과만 출력되도록 설정
SELECT A.칼럼1, A.칼럼2, ..., B.칼럼1, B.칼럼2, ... FROM 테이블1 A [INNER] JOIN 테이블2 B ON 조인조건 [WHERE 검색조건];
- 왼쪽 외부조인 → LEFT JOIN 테이블 ON
- OUTER 키워드 : 생략해도 왼쪽 외부 조인 가능
- 검색 조건 추가 시 ➡️조인된 값에서 ➡️ 해당 조건에 맞는 결과만 출력되도록 설정
SELECT A.칼럼1, A.칼럼2, ..., B.컬럼1, B.칼럼2, ... FROM 테이블1 A LEFT [OUTER] JOIN 테이블2 B ON 조인조건 [WHERE 검색조건]; -- 예시 다음과 같이 도서와 도서가격이라는 테이블이 있다. 책 번호 컬럼을 기준으로 Left Outher Join을 하여 [결과] 테이블과 같이 나오는 쿼리 [도서] | 책번호 | 책명 | | 111 | 운영체제 | | 222 | 자료구조 | | 555 | 컴퓨터구조 | [도서가격] | 책번호 | 가격 | | 111 | 20,000 | | 222 | 25,000 | | 333 | 10,000 | | 444 | 15,000 | [결과] | 책번호 | 책명 | 책번호 | 가격 | | 111 | 운영체제 | 111 | 20,000 | | 222 | 자료구조 | 222 | 25,000 | | 555 | 컴퓨터구조 | NULL | NULL | -- 답 SELECT A.책번호, A.책명, B.책번호, B.가격 FROM 도서 A LEFT JOIN 도서가격 B ON A.책번호 = B.책번호;
- 오른쪽 외부조인 → RIGHT JOIN 테이블 ON
- OUTER 키워드 : 생략해도 오른쪽 외부 조인 가능
- 검색 조건 추가 시 ➡️조인된 값에서 ➡️ 해당 조건에 맞는 결과만 출력되도록 설정
SELECT A.칼럼1, A.칼럼2, ..., B.컬럼1, B.칼럼2, ... FROM 테이블1 A RIGHT [OUTER] JOIN 테이블2 B ON 조인조건 [WHERE 검색조건];
- 완전 외부조인 → FULL JOIN 테이블 ON
- OUTER 키워드 : 생략해도 완전 외부 조인 가능
- 검색 조건 추가 시 ➡️조인된 값에서 ➡️ 해당 조건에 맞는 결과만 출력되도록 설정
SELECT A.칼럼1, A.칼럼2, ..., B.컬럼1, B.칼럼2, ... FROM 테이블1 A FULL [OUTER] JOIN 테이블2 B ON 조인조건 [WHERE 검색조건];
- 교차조인 → CROSS JOIN 테이블 (ON 없음)
- 조인 조건이 없는 모든 데이터 조합을 추출하기 때문에 ON절 없음!
SELECT 컬럼1, 컬럼2, ... FROM 테이블1 CROSS JOIN 테이블2
- 조인 조건이 없는 모든 데이터 조합을 추출하기 때문에 ON절 없음!
- 셀프 조인
-
같은 테이블을 조인하는 경우임!
-
같은 테이블명을 쓰고 별칭만 A, B와 같이 다르게 함.
-
검색 조건 추가 시 ➡️조인된 값에서 ➡️ 해당 조건에 맞는 결과만 출력되도록 설정
SELECT A.칼럼1, A.칼럼2, ..., B.칼럼1, B.칼럼2, ... FROM 테이블1 A [INNER] JOIN 테이블1 B ON 조인조건 [WHERE 검색조건];
-
🤍 집합 연산자 4가지 = UNION, UNION ALL, INTERSECT, MINUS
- UNION → 중복 레코드 제외
- 중복 행이 제거된 쿼리 결과를 반환하는 집합 연산자
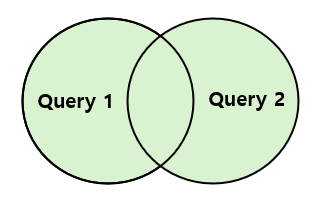
- 중복 행이 제거된 쿼리 결과를 반환하는 집합 연산자
- UNION ALL → 중복 레코드 허용
- 중복 행이 제거되지 않은 쿼리 결과를 반환하는 집합 연산자
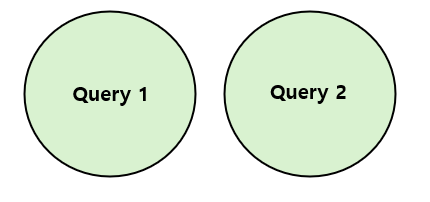
- 중복 행이 제거되지 않은 쿼리 결과를 반환하는 집합 연산자
- INTERSECT → 중복 레코드만 포함
- 두 쿼리 결과에 공통 존재하는 결과를 반환하는 집합 연산자
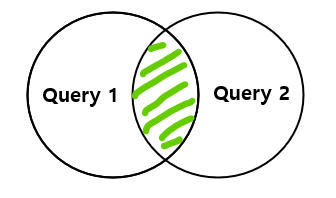
- 두 쿼리 결과에 공통 존재하는 결과를 반환하는 집합 연산자
- MINUS → 비교 레코드 제외
- 첫 쿼리에 있고 두번째 쿼리에는 없는 결과를 반환하는 집합 연산자
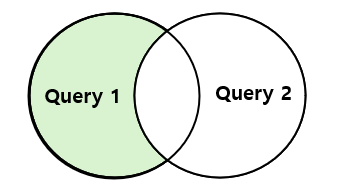
- 첫 쿼리에 있고 두번째 쿼리에는 없는 결과를 반환하는 집합 연산자
DCL(데이터 제어어)
🤍 DCL(데이터 제어어) = GRANT, REVOKE [21년 3회]
- GRANT 권한 ON 테이블 TO 사용자;
- 사용 권한 부여
-
관리자(DBA)가 사용자에게 데이터베이스에 대한 권한을 부여하는 명령어
GRANT 권한 ON 테이블 TO 사용자; ex) 관리자가 사용자 장길산에게 '학생' 테이블에 대해 UPDATE 할 수 있는 권한 부여 GRANT UPDATE ON 학생 TO 장길산;
-
- 사용 권한 부여
- REVOKE 권한 ON 테이블 FROM 사용자;
- 사용 권한 취소
-
관리자(DBA)가 사용자에게 부여했던 권한을 회수하기 위한 명령어
REVOKE 권한 ON 테이블 FROM 사용자; ex) 관리자가 사용자 장길산에게 '학생' 테이블에 대해 UPDATE 할 수 있는 권한을 회수 REVOKE UPDATE ON 학생 FROM 장길산;
-
- 사용 권한 취소
🤍 테이블에 속성 추가 [20년 3회]
- 예시) 학생 테이블에 주소 속성을 추가하는 SQL문
- ALTER TABLE 학생 ADD 주소 VARCHAR(20);
🤍 UPDATE 테이블명 SET … [21년 2회]
- 데이터 내용을 변경(수정)할 때 사용하는 명령어
- UPDATE 테이블명 SET 속성명 = 데이터, … WHERE 조건;
- 예시
- UPDATE 회원 SET 전화번호 = ‘010-14’ WHERE 회원번호 = ‘N4’;
- UPDATE 회원 SET 전화번호 = ‘010-14’ WHERE 회원번호 = ‘N4’;
- UPDATE 테이블명 SET 속성명 = 데이터, … WHERE 조건;
🤍 정렬 = ORDER BY 칼럼 ASC | ORDER BY 칼럼 DESC [21년 2회, 22년 1회]
- 정렬 : 속성값 정렬하고자 할 때 ORDER BY 절 사용(키워드 생략 시 오름차순)
-
오름차순 : ASC
-
내림차순 : DESC
# 21년 2회 # [학생] 테이블을 이용해 이름이 이로 시작하는 학생들에 대해 내림차순 정렬 SELECT * FROM 학생 WHERE 이름 LIKE DESC ORDER BY 이름 "이%";# 22년 1회 # 점수에 대해 내림차순 하는 SQL SELECT NAME, SCORE FROM 성적 ORDER BY SCORE DESC; # 성적 테이블의 이름, 과목, 성적을 성적순(내림차순)으로 출력하는 쿼리 #(성적 테이블의 칼럼은 이름, 과목, 성적 이 3개가 전부이니, *도 무방) SELECT * FROM 성적 ORDER BY 성적 DESC;
-
🤍 패턴에 포함된 데이터 조회 = LIKE % | LIKE [] | LIKE [^] | LIKE _ [21년 2회]
-
데이터 조회 : 컬럼이 패턴에 포함된 경우 데이터 조회할 때 LIKE 문 사용
-
% : 0개 이상의 문자열과 일치
-
[] : 1개 이상의 문자열과 일치
-
[^] : 1개의 문자와 불일치
-
_ : 특정 위치의 1개의 문자와 일치
-- 예시) -- '이'로 시작하는 사람 검색 WHERE 이름 LIKE '이%'; -- '이'로 끝나는 사람 검색 WHERE 이름 LIKE '%이'; -- '이'가 들어가는 사람 검색 WHERE 이름 LIKE '%이%'; -- '이'로 시작되고 '이' 뒤에 1글자만 있는 사람 검색 WHERE 이름 LIKE '이_'; -- '이'로 시작되고 '이' 뒤에 2글자만 있는 사람 검색 WHERE 이름 LIKE '이__'; -- '이*신'이라는 사람 검색 WHERE 이름 LIKE '이_신';SELECT * FROM 학생 WHERE 이름 LIKE DESC ORDER BY 이름 "이%"; ----------------------------------------------------------------------------------- # % 사용 # 특정 문자열이 포함된 경우 SELECT * FROM 테이블명 WHERE 컬럼명 LIKE '%특정문자열%'; # 특정 패턴으로 시작하는 경우 SELECT * FROM 테이블명 WHERE 컬럼명 LIKE '특정패턴%'; # 특정 패턴으로 끝나는 경우 SELECT * FROM 테이블명 WHERE 컬럼명 LIKE '%특정패턴'; # 특정 패턴으로 시작하고 끝나는 경우 SELECT * FROM 테이블명 WHERE 컬럼명 LIKE '특정패턴%특정패턴'; # 특정 문자로 시작하거나 끝나는 경우 SELECT * FROM 테이블명 WHERE 컬럼명 LIKE '특정문자%' OR 컬럼명 LIKE '%특정문자'; ----------------------------------------------------------------------------------- # [ ] 사용 # 컬럼명이 'a', 'b', 'c' 중 하나와 일치하는 모든 데이터를 조회 SELECT * FROM 테이블명 WHERE 컬럼명 LIKE '[abc]'; ----------------------------------------------------------------------------------- # [^] 사용 # 컬럼값이 'axyz', 'aexyz', 'afxyz'와 같이 'a'로 시작하고 # 그 뒤에 'b', 'c', 'd' 중 어느 것도 오지 않는 모든 데이터를 조회 SELECT * FROM 테이블명 WHERE 컬럼명 LIKE 'a[^bcd]xyz%'; ----------------------------------------------------------------------------------- # _ 사용 # 컬럼값이 'a12xyz', 'aABxyz', 'a_#xyz'와 같이 'a'로 시작하고 # 그 다음 두 자리에 어떤 문자가 오든 상관 없는 모든 데이터를 조회 SELECT * FROM 테이블명 WHERE 컬럼명 LIKE 'a__xyz%';
-
-
조인 + 패턴에 포함된 데이터 조회 문제

SELECT COUNT(*) CNT FROM SOO CROSS JOIN JEBI WHERE SOO.NAME LIKE JEBI.RULE;- 실행 결과 : 5

- 실행 결과 : 5
Ch2. 응용 SQL 작성하기
🤍 MIN, MAX, AS [20년 3회]
- MIN : 최솟값
- MAX : 최댓값
- AS : 별칭(결과에 나오는 칼럼명!)
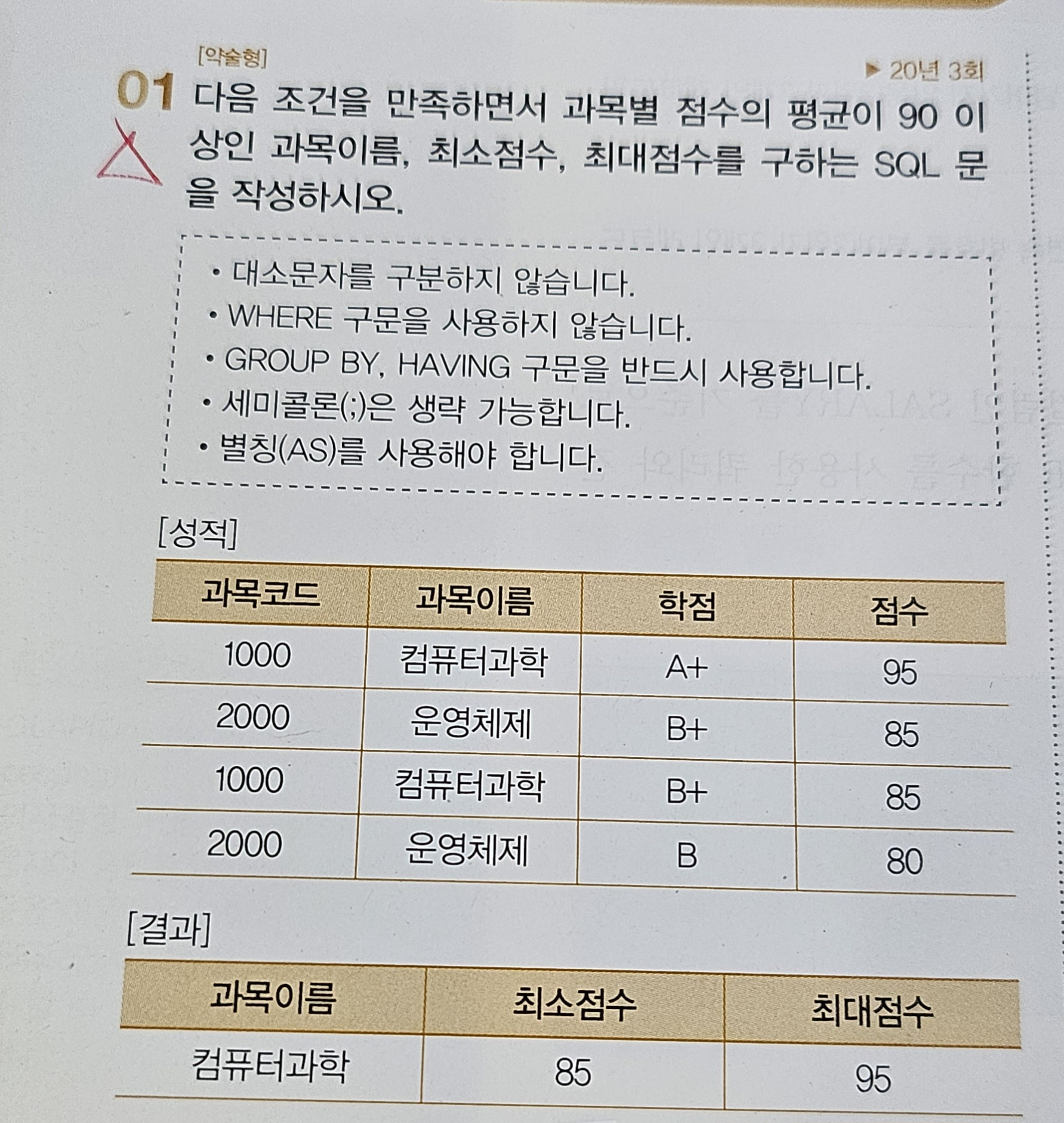
SELECT 과목이름, MIN(점수) AS 최소점수, MAX(점수) AS 최대점수
GROUP BY 과목이름
HAVING AVG(점수) >= 90;🤍 HAVING
- 다음은 학생 테이블의 일부이다. 평균 성적이 4.0을 초과하는 학생의 이름을 출력하는 쿼리 [학생]
이름 과목 성적 문무왕 프로그래밍 4.5 문무왕 알고리즘 4.5 장보고 알고리즘 3.5 장보고 자료구조 4.5 SELECT 이름 FROM 학생 GROUP BY 이름 HAVING AVG(성적) > 4.0;
🤍 튜플 수 구하기 [20년 4회]


SELECT 학과, COUNT(학과) AS 학과별튜플수 FROM 학생
GROUP BY 학과;🤍 COUNT 계산과 AND, OR 계산 [21년 1회]
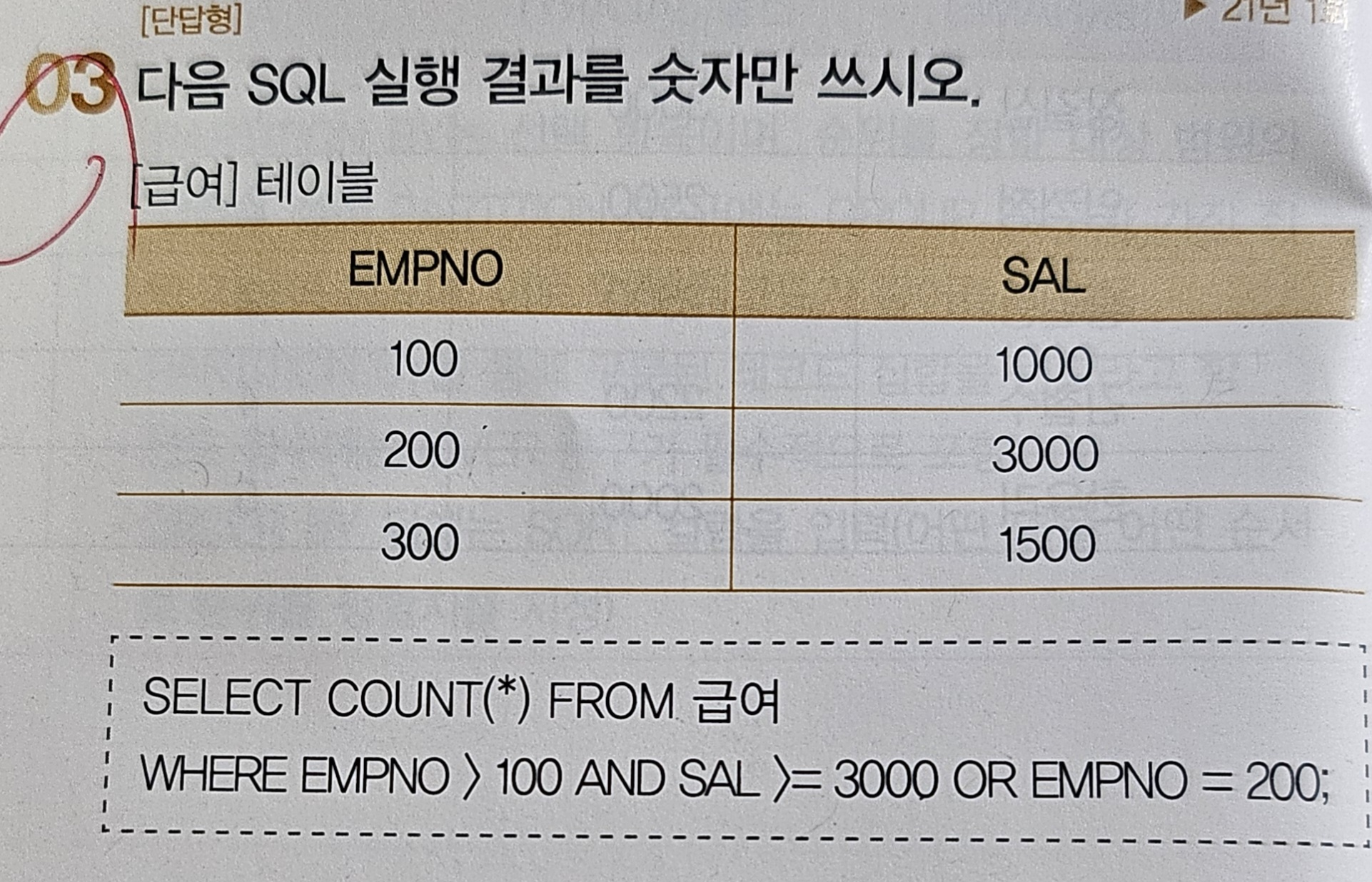
- 풀이 과정
- COUNT(*) : NULL 값 포함해서 카운트
- (EMPNO > 100 AND SAL >=3000) OR EMPNO = 200
-
EMPNO > 100
- EMPNO가 100 초과인 200, 300 해당
-
SAL ≥ 3000
- EMPNO 200과 300중 200만 해당
-
둘의 AND 연산
- EMPNO = 200 해당
-
EMPNO = 200
- 위의 2개의 AND 연산으로 나온 EMPNO 200과 OR연산으로 인해 들어가는 EMPNO 200은 같기 때문에 200만 해당
- (만약, OR EMPNO = 300 이었다면? → OR 연산에 의해 앞의 2개의 AND 연산에 의해 나온 EMPNO = 200과 함께 2로 카운트 될 것!)따라서 결과는 1
-
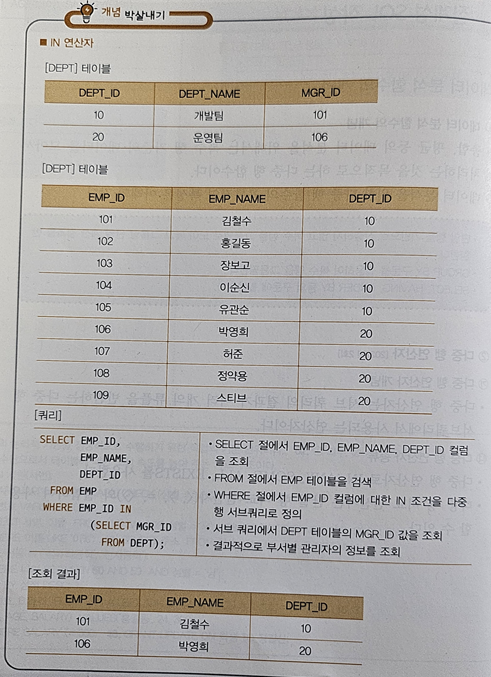
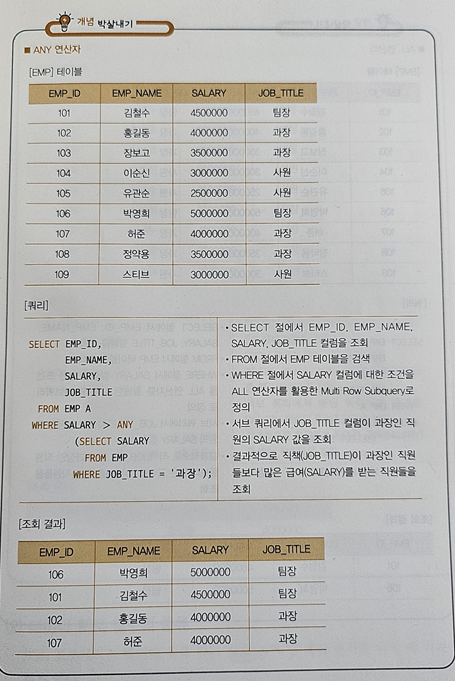
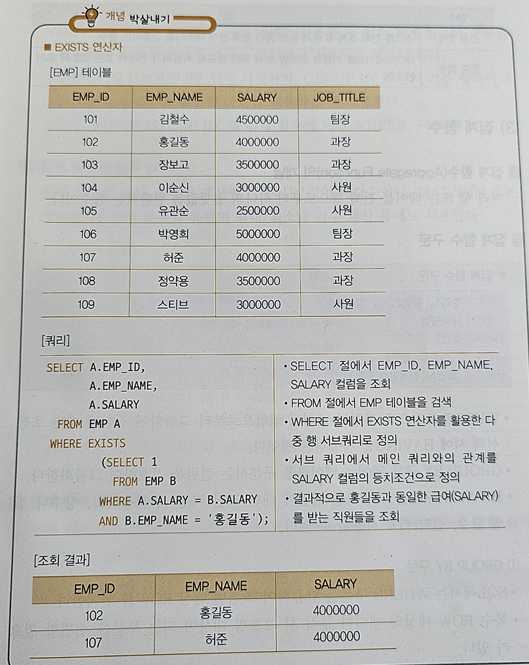
🤍 다중 행 비교 연산자 = IN, ANY(=SOME), ALL, EXISTE [22년 2회]
- 다중 행 비교 연산자는 단일 행 비교 연산자(<, >, =, <>)와 결합해 사용 가능
- IN : 리턴되는 값 중 조건에 해당하는 값이 있으면 참
- ANY(=SOME) : 서브쿼리에 의해 리턴되는 각각의 값과 조건을 비교해 하나 이상 만족하면 참
- ALL : 값을 서브쿼리에 의해 리턴되는 모든 값과 조건값을 비교하여 모든 값을 만족해야만 참
- EXISTS : 메인 쿼리의 비교 조건이 서브쿼리의 결과 중에서 만족하는 값이 하나라도 존재하면 참

-
답 : ALL
- 서브쿼리로 도출된 모든 값이 조건을 만족해야 하므로 ALL연산자를 사용
- “모든 제품의 단가보다”
-
예시

🤍 ROLLUP
- ROLLUP에 의해 지정된 컬럼은 소계(소그룹의 합계) 등 중간 집계 값을 산출하기 위해 사용
- 예시) 다음은 학교와 학년별 인원수이 학교 테이블이다. 그룹 함수를 사용하여 학교별 인원수와 전체 인원수를 알려주는 쿼리를 작성하시오. [학교]
[결과]학교명 학년 인원 A 1 51 A 2 29 A 3 15 B 1 33 B 2 44 B 3 72 학교명 학년 인원 A 1 51 A 2 29 A 3 15 A 95 B 1 33 B 2 44 B 3 72 B 149 244 SELECT 학교명, 학년, SUM(인원) AS 인원 FROM 학교 GROUP BY RULLUP(학교명, 학년);
🤍 윈도 함수(=OLAP 함수)와 순위 함수
- 윈도 함수
-
데이터베이스를 사용한 온라인 분석 처리 용도로 사용하기 위해서 표준 SQL에 추가된 함수
SELECT 함수명(파ㅇ라미터) OVER ([PARTITION BY 컬럼1, ...]) [ORDER BY 컬럼A, ...] FROM 테이블명
-
- 순위 함수 3가지 : RANK, DENSE_RANK, ROW_NUMBER
- RANK → 2위, 2위, 2위, 5위
- 특정 항목(컬럼)에 대한 순위를 구하는 함수
- 동일 순위의 레코드 존재 시 후순위는 넘어감(2위가 3개인 레코드의 경우: 2위, 2위, 2위, 5위,…)
- DENSE_RANK → 2위, 2위, 2위, 3위
- 레코드의 순위를 계산
- 동일 순위의 레코드 존재 시에도 후순위를 넘어가지 않음(2위가 3개인 레코드인 경우: 2위, 2위, 2위, 3위, ..)
- ROW_NUMBER → 2위, 3위, 4위
- 레코드의 순위를 계산
- 동일 순위의 값이 존재해도 이와 무관하게 연속 번호를 부여(2위가 3개인 레코드의 경우: 2위, 3위, 4위, 5위, 6위)
- 예시 문제
-
다음은 학생 테이블이다. 윈도 함수를 이용하여 결과 테이블과 동일하게 나오도록 쿼리 작성
[학생] | 이름 | 점수 | | --- | --- | | 장길산 | 100 | | 임꺽정 | 100 | | 홍길동 | 90 | | 김철수 | 80 | | 한유리 | 70 | [결과] | 이름 | 점수 | 등수 | | --- | --- | --- | | 장길산 | 100 | 1 | | 임꺽정 | 100 | 1 | | 홍길동 | 90 | 2 | | 김철수 | 80 | 3 | | 한유리 | 70 | 4 |SELECT 이름, 점수, DENSE_RANK() OVER(ORDER BY 점수 DESC) AS 등수 FROM 학생;
-
- RANK → 2위, 2위, 2위, 5위
Ch3. SQL 활용 및 최적화
🤍 절차형 SQL 종류 3가지 = 프, 사, 트
- 프로시저
- 일련의 쿼리들을 마치 하나의 함수처럼 실행하기 위한 쿼리의 집합
- 사용자 정의 함수
- 일련의 SQL 처리를 수행하고, 수행 결과를 단일 값으로 반환할 수 있는 절차형 SQL
- 트리거
- 데이터베이스 시스템에서 삽입, 갱신, 삭제 등의 이벤트가 발생할 때마다 관련 작업이 자동으로 수행되는 절차형 SQL
🤍 옵티마이저 = 최적의 처리경로를 생성하는 DBMS 내부의 핵심엔진
- SQL을 가장 빠르고 효율적으로 수행할 최적의 처리경로를 생성해주는 DBMS 내부의 핵심엔진
- 옵티마이저가 생성한 SQL 처리 경로를 실행계획(Execution Plan)이라 부름.
