Notebook
-
transcription
Introduction to Manual Feature Engineering.ipynb
kde_target() AttributeError
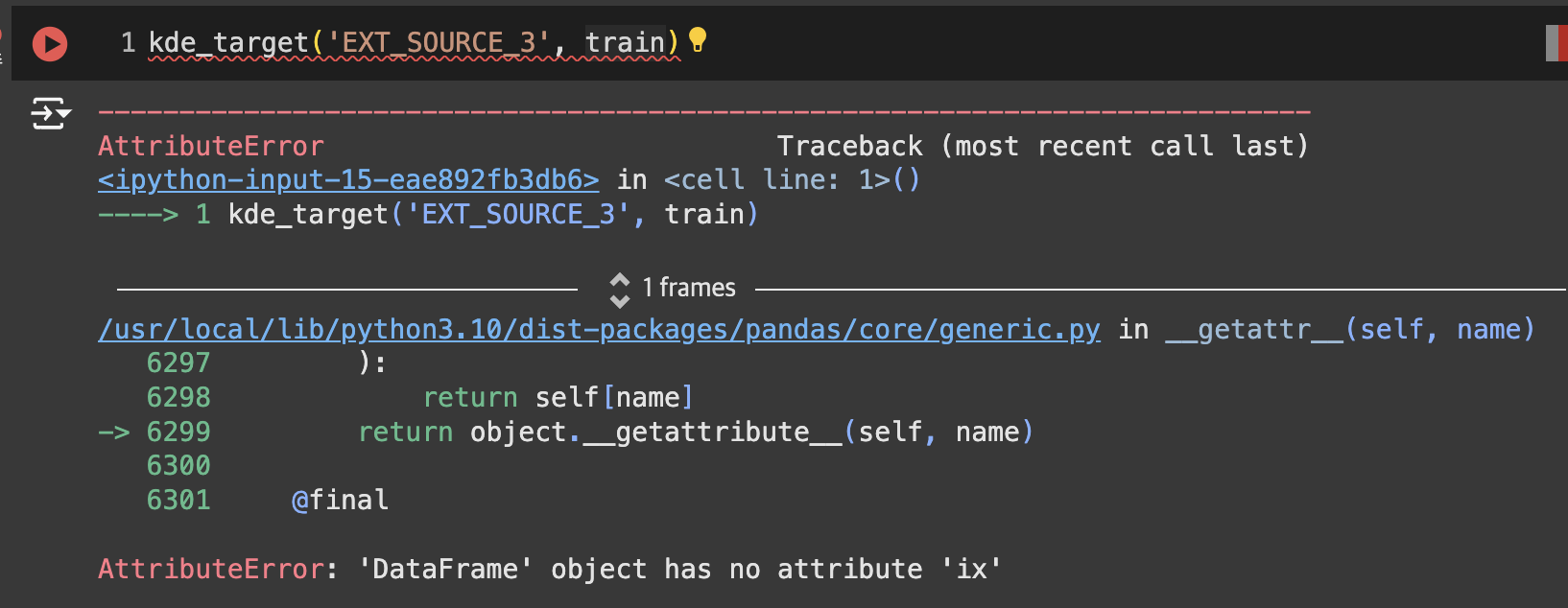
- 현재의 구글 코랩 Pandas 버전에서는 .ix를 사용할 수 없음.
.loc으로 대체 가능- 이전 코드
...
avg_repaid = df.ix[df['TARGET'] == 0, var_name].median()
avg_not_repaid = df.ix[df['TARGET'] == 1, var_name].median()
plt.figure(figsize = (12, 6))
sns.kdeplot(df.ix[df['TARGET'] == 0, var_name], label = 'TARGET == 0')
sns.kdeplot(df.ix[df['TARGET'] == 1, var_name], label = 'TARGET == 1')
...- 변경 코드
...
avg_repaid = df.loc[df['TARGET'] == 0, var_name].median()
avg_not_repaid = df.loc[df['TARGET'] == 1, var_name].median()
plt.figure(figsize = (12, 6))
sns.kdeplot(df.loc[df['TARGET'] == 0, var_name], label = 'TARGET == 0')
sns.kdeplot(df.loc[df['TARGET'] == 1, var_name], label = 'TARGET == 1')
...
agg function failed [how->mean,dtype->object]
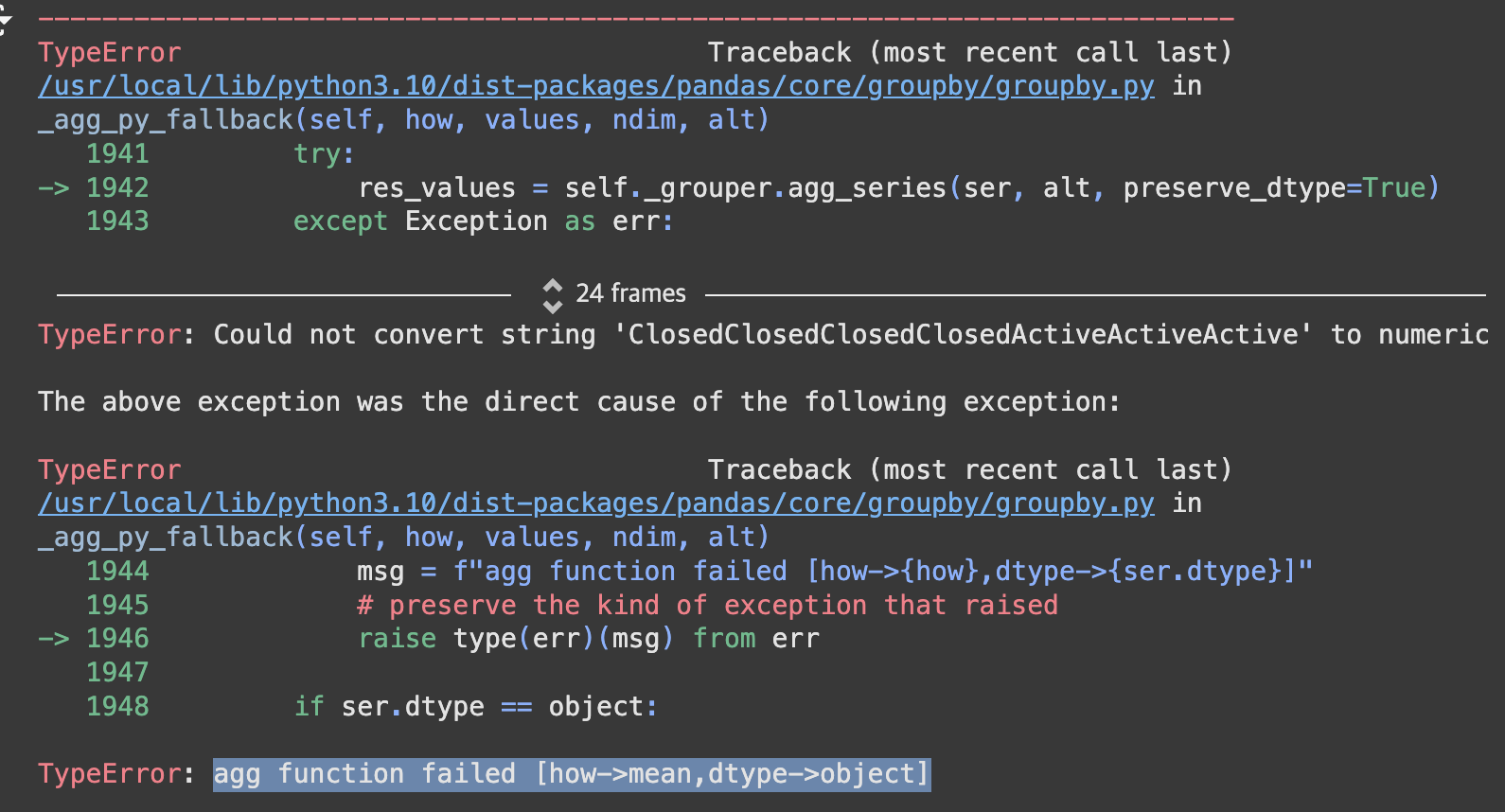
- 문자 데이터에 대한 평균 계산이 불가한데, 시도해서 생긴 문제
- 수치형 데이터만 선택한다는 추가 코드가 필요
# 추가: 수치형 데이터만 선택
numeric_cols = bureau.drop(columns=['SK_ID_BUREAU']).select_dtypes(include='number').columns
# 그룹화 후 집계
bureau_agg = bureau.drop(columns=['SK_ID_BUREAU']).groupby('SK_ID_CURR', as_index=False)[numeric_cols].agg(['count', 'mean', 'max', 'min', 'sum']).reset_index()
# 결과 확인
bureau_agg.head()
'bureau_agg.columns = columns' ValueError
bureau_agg.columns의 열 개수와columns변수의 값 개수가 일치하지 않아 발생- SK_ID_CURR 컬럼에 대한 index가 불필요하게 추가되어 발생 -> index 컬럼이 아예 바로 드랍되게끔 코드 수정 ->
.reset_index(drop=True) - SK_ID_CURR에 대한 불필요 계산 컬럼도 삭제
- SK_ID_CURR 컬럼에 대한 index가 불필요하게 추가되어 발생 -> index 컬럼이 아예 바로 드랍되게끔 코드 수정 ->
# 추가: 수치형 데이터만 선택
numeric_cols = bureau.drop(columns=['SK_ID_BUREAU']).select_dtypes(include='number').columns
# 그룹화 후 집계
bureau_agg = bureau.drop(columns=['SK_ID_BUREAU']).groupby('SK_ID_CURR', as_index=False)[numeric_cols].agg(['count', 'mean', 'max', 'min', 'sum']).reset_index(drop=True)
# 결과 확인
bureau_agg.head()# 추가: SK_ID_CURR에 대한 불필요 계산 컬럼 삭제
columns_to_remove = [(col, agg) for col, agg in bureau_agg.columns if col == 'SK_ID_CURR' and agg in ['count', 'mean', 'max', 'min', 'sum']]
bureau_agg.drop(columns=columns_to_remove, inplace=True)
[고려할 부분] The Multiple Comparisons Problem
- 변수가 많을 경우 우연에 의한 단순 상관관계가 있을 가능성이 높음
- 무작위로 발생한 노이즈때문에 상관관계로 그냥 엮이는 경우도 있음
- 이러한 경우, 모델이 이 사실을 오해해서 과적합될 가능성이 있음
- 반드시 고려해야 할 부분!
Function for Numeric Aggregations
- 수치형 데이터에 대한 작업을 함수화해서 재사용성을 올릴 수 있음!
def agg_numeric(df, group_var, df_name):
"""Aggregates the numeric values in a dataframe. This can
be used to create features for each instance of the grouping variable.
Parameters
--------
df (dataframe):
the dataframe to calculate the statistics on
group_var (string):
the variable by which to group df
df_name (string):
the variable used to rename the columns
Return
--------
agg (dataframe):
a dataframe with the statistics aggregated for
all numeric columns. Each instance of the grouping variable will have
the statistics (mean, min, max, sum; currently supported) calculated.
The columns are also renamed to keep track of features created.
"""
for col in df:
if col != group_var and 'SK_ID' in col:
df = df.drop(columns = col)
group_ids = df[group_var]
numeric_df = df.select_dtypes('number')
numeric_df[group_var] = group_ids
agg = numeric_df.groupby(group_var).agg(['count', 'mean', 'max', 'min', 'sum']).reset_index()
columns = [group_var]
for var in agg.columns.levels[0]:
if var != group_var:
for stat in agg.columns.levels[1][:-1]:
columns.append('%s_%s_%s' % (df_name, var, stat))
agg.columns = columns
return agg다중 인덱스(multi-index)
- 행이나 열이 여러 단계의 인덱스를 가지는 구조
- 그룹화된 데이터 또는 집계된 데이터를 다루는 경우 사용
셀 셧다운 문제
- 해당 셀을 실행하여 학습을 진행하는 시점부터 계속 셧다운 문제 발생
- GPU 연결을 해도 동일 -> 우선 이 셀 이후부터는 필사만 진행
Notebook 특징
- 다양한 데이터 전처리 및 피쳐 엔지니어링을 함수화하여, 코드 재사용성을 높인다!

언젠가 내 코드로 세상에 기여할 수 있도록, Data Science&BE 개발 기록 노트☘️