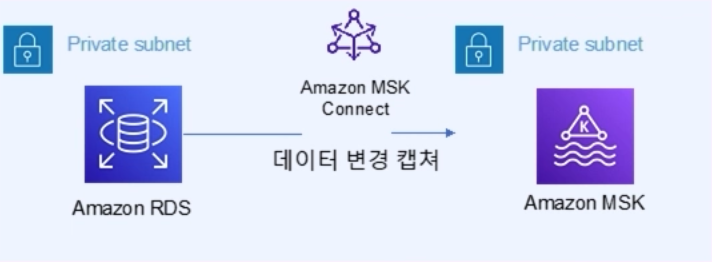
아키텍처
대시보드 애플리케이션은 로드밸런서와 ECS로 연결되어 있다.
주문페이지에서 주문이 되면 이 데이터는 RDS에 저장이 된다.
그러면 이 변경된 데이터는 MSK에서 보내주고 대시보드 애플리케이션에서 이 데이터를 받아서
대시보드에 업데이트 되도록 구현할 계획이다.
MSK를 활용한 데이터 스트림 처리
MSK 클러스터 생성

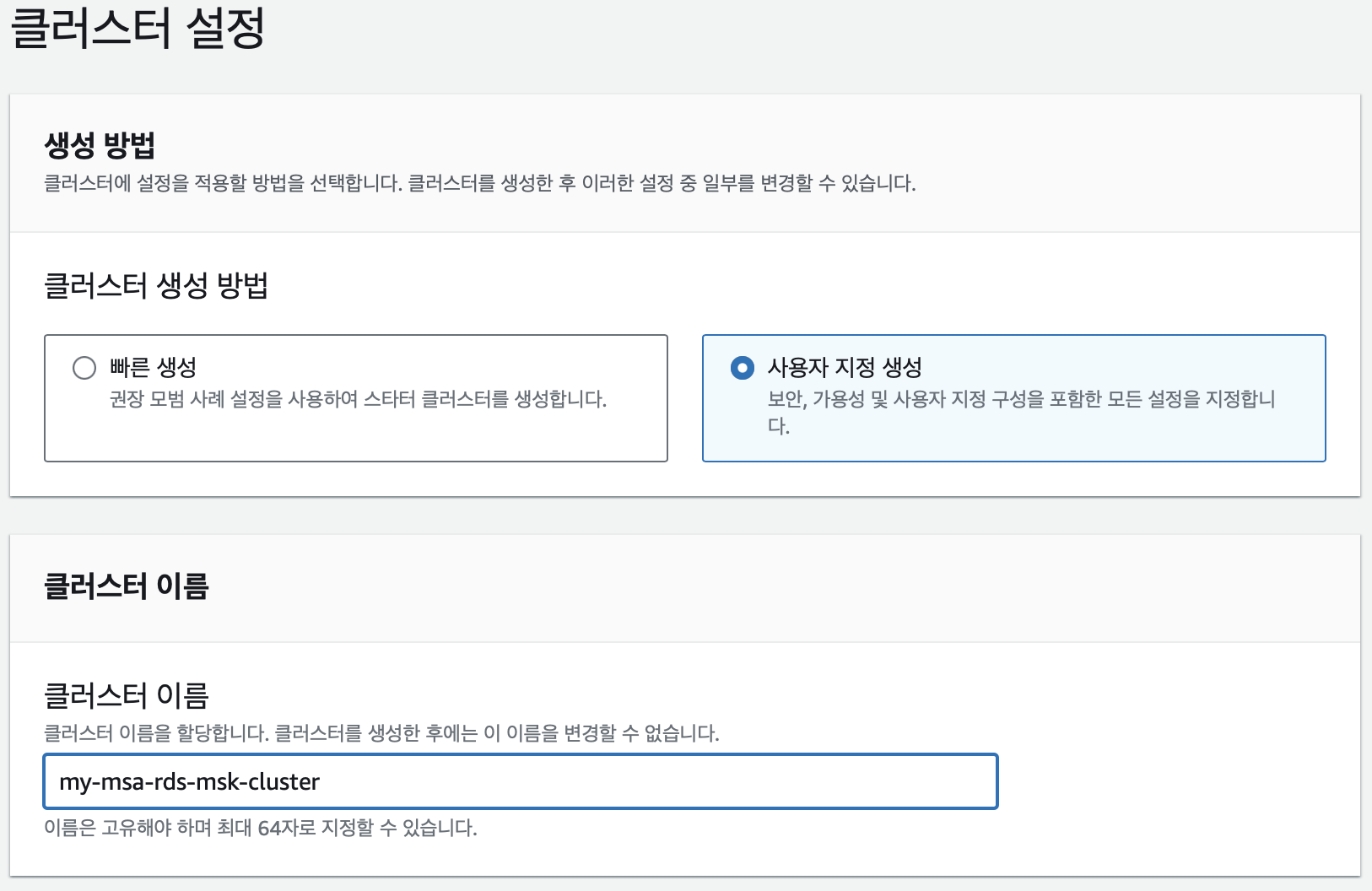
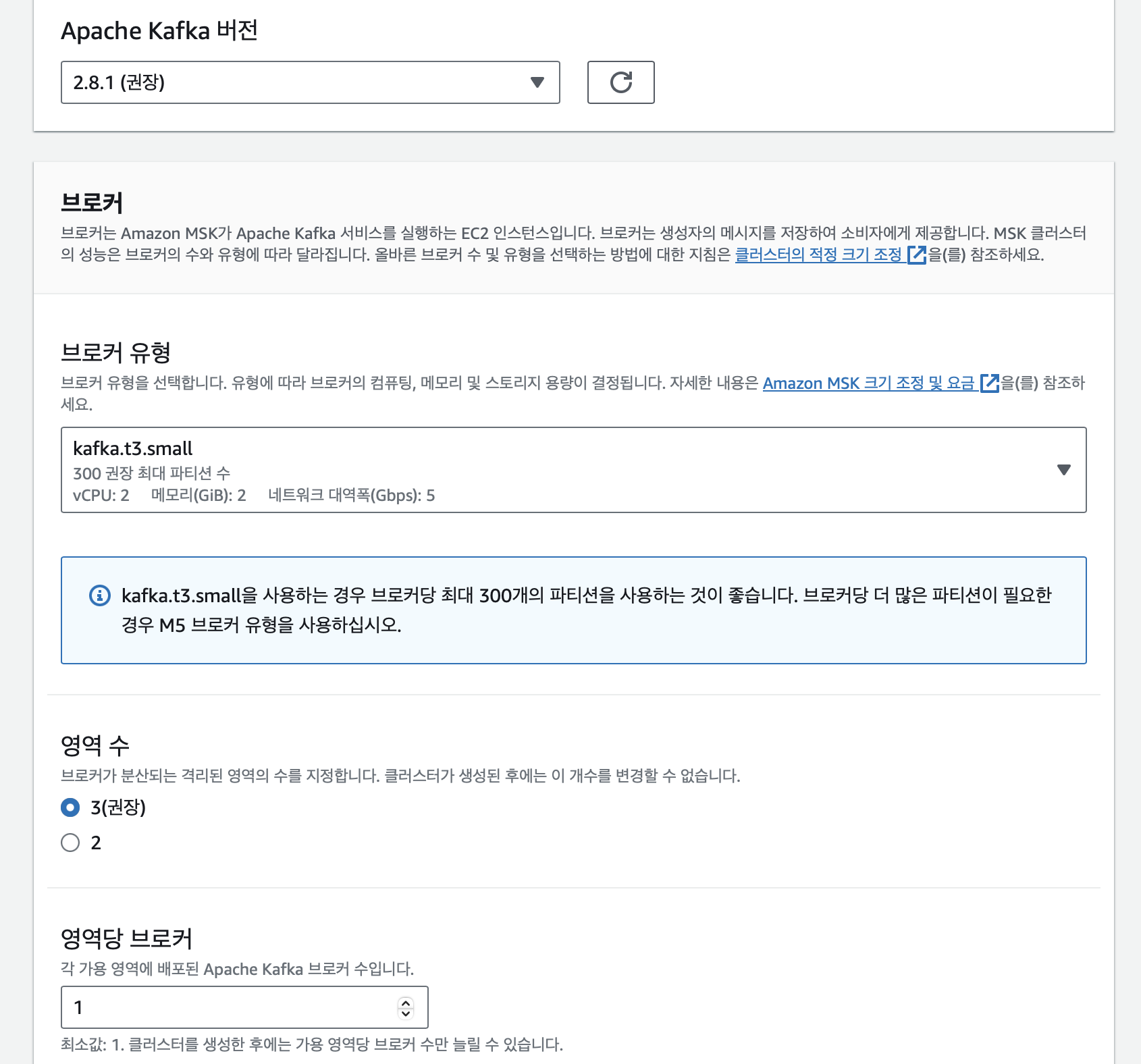
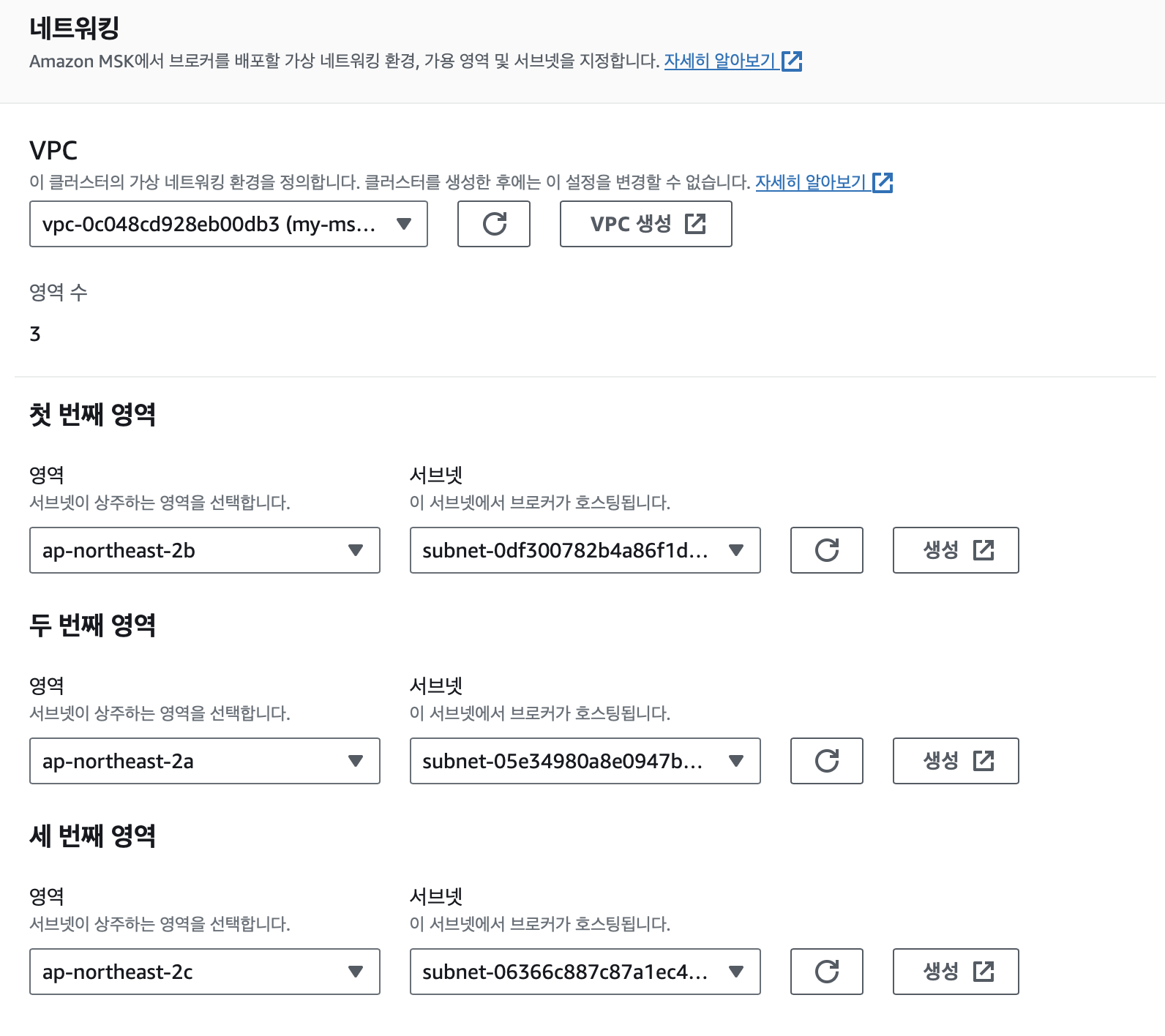
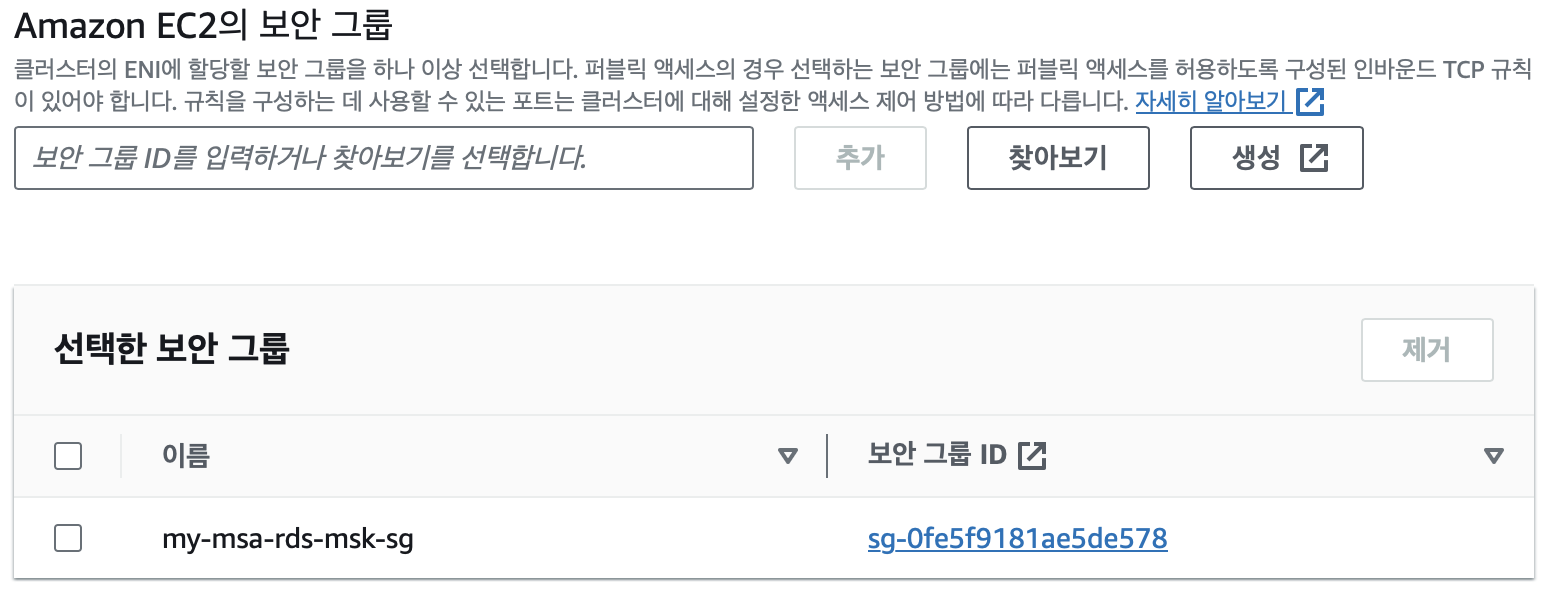
먼저 위와같이 MSK 클러스터를 생성하였다.
브로커 유형은 가장 작은 t3.small을 사용하였고 나머지 값들은 거의 디폴트 값으로 설정하였다.
BootStrap 서버 설정
클러스터가 프로비저닝 되면 클러스터가 구성된 VPC에 EC2 인스턴스를 하나 생성한다.
MSK 클러스터에서 퍼블릭 액세스를 허용하지 않기 때문에 퍼블릭 서브넷에서 인스턴스를 통해서
접근한다.
물론 퍼블릭 액세스를 허용하게 하는 방법도 존재한다.
공식문서: MSK 클러스터 퍼블릭 액세스
- Bootstrap 서버에 접속
sudo -u ec2-user -i
export MSK_BOOTSTRAP_ADDRESS=<- 아래 커맨드 실행하여 Bootstrap 서버 설정
echo "export MSK_BOOTSTRAP_ADDRESS=${MSK_BOOTSTRAP_ADDRESS}" | tee -a ~/.bash_profile
export AWS_REGION=$(curl -s 169.254.169.254/latest/dynamic/instance-identity/document | jq -r '.region')
export ACCOUNT_ID=$(aws sts get-caller-identity --output text --query Account)
test -n "$AWS_REGION" && echo AWS_REGION is "$AWS_REGION" || echo AWS_REGION is not set export RDS_AURORA_ENDPOINT=$(aws rds describe-db-instances --region ${AWS_REGION} | jq -r '.DBInstances[] | select(.DBInstanceIdentifier | startswith("ch2-sample-db"))
| .Endpoint.Address')
echo "export RDS_AURORA_ENDPOINT=${RDS_AURORA_ENDPOINT}" | tee -a ~/.bash_profile
echo "export ACCOUNT_ID=${ACCOUNT_ID}" | tee -a ~/.bash_profile
echo "export AWS_REGION=${AWS_REGION}" | tee -a ~/.bash_profile커넥터 설정
-
해당 링크에서 Stable Version을 다운로드
debezium -
아래 명령어를 실행하여 압축 해제
sudo tar -xzvf debezium-connector-mysql-2.3.4.Final-plugin.tar압축이 풀렸으면 해당 디렉토리를 S3 버킷에 업로드한다.
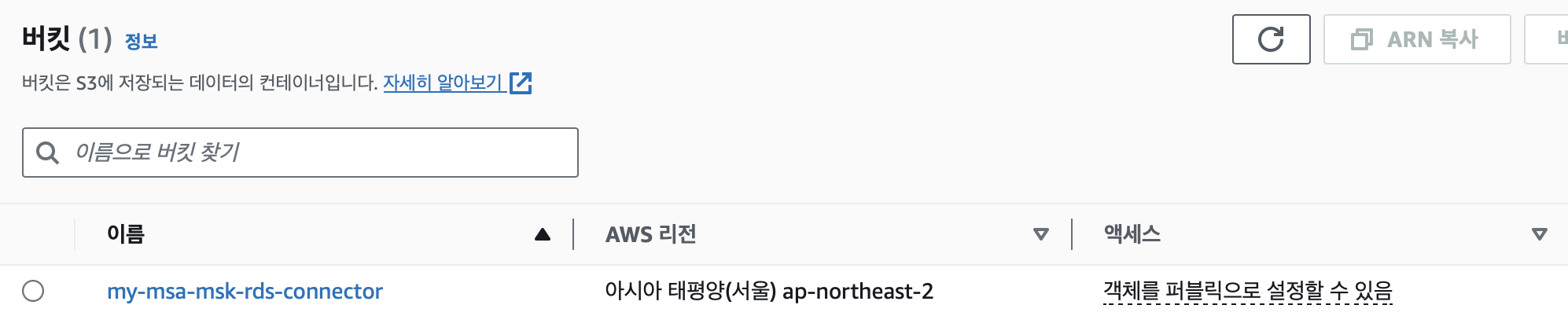
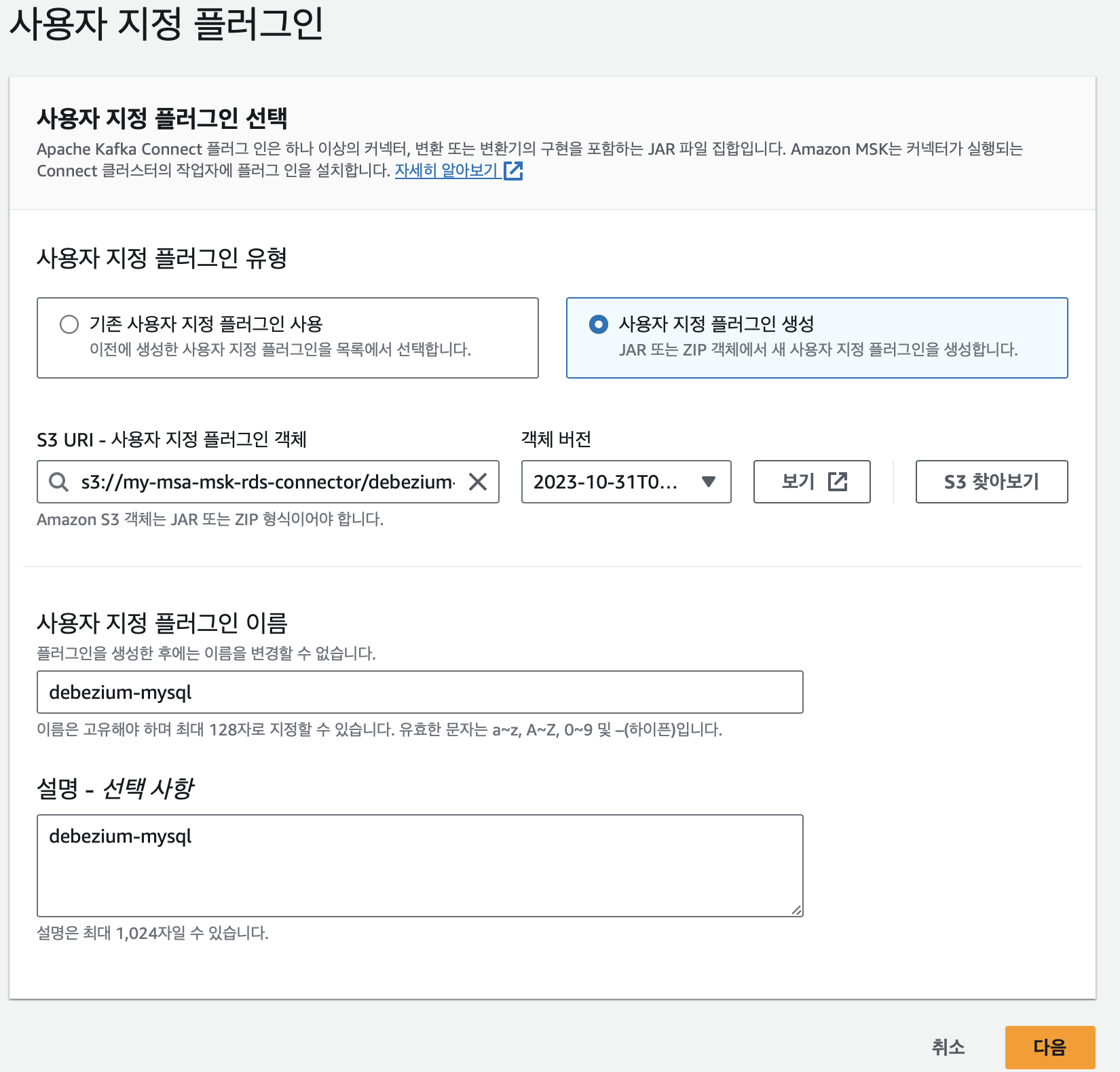
Custom Plugin 생성

connector.class=io.debezium.connector.mysql.MySqlConnector
tasks.max=1
database.hostname=my-msa-rds.ckam5ywrz4q7.ap-northeast-2.rds.amazonaws.com
database.port=3306
database.user=admin
database.password=dlatkdrb123!
database.server.id=980219
database.include.list=ecommerce
topic.prefix=my-prefix-
schema.history.internal.kafka.topic=dbhistory.ecommerce
schema.history.internal.kafka.bootstrap.servers=b-2.mymsamskcluster.eznb0f.c3.kafka.ap-northeast-2.amazonaws.com:9098,b-3.mymsamskcluster.eznb0f.c3.kafka.ap-northeast-2.amazonaws.com:9098,b-1.mymsamskcluster.eznb0f.c3.kafka.ap-northeast-2.amazonaws.com:9098
schema.history.internal.consumer.security.protocol=SASL_SSL
schema.history.internal.consumer.sasl.mechanism=AWS_MSK_IAM
schema.history.internal.consumer.sasl.jaas.config=software.amazon.msk.auth.iam.IAMLoginModule required;
schema.history.internal.consumer.sasl.client.callback.handler.class=software.amazon.msk.auth.iam.IAMClientCallbackHandler
schema.history.internal.producer.security.protocol=SASL_SSL
schema.history.internal.producer.sasl.mechanism=AWS_MSK_IAM
schema.history.internal.producer.sasl.jaas.config=software.amazon.msk.auth.iam.IAMLoginModule required;
schema.history.internal.producer.sasl.client.callback.handler.class=software.amazon.msk.auth.iam.IAMClientCallbackHandler
include.schema.changes=true➡️ connector.class: 사용할 Debezium 커넥터의 클래스를 MySQL 커넥터로 지정
database.history.producer.sasl.mechanism / database.history.producer.sasl.jaas.config:
MSK에서 인증을 수행하기 위한 설정입니다. IAM 인증 메커니즘을 사용하며,
"AWS_MSK_IAM"을 기반
database.user: MySQL 데이터베이스에 연결할 사용자 이름
database.server.id: RDS 인스턴스의 이름 또는 ID
tasks.max: 처리할 Debezium 태스크 수
database.history.consumer.sasl.jaas.config: 변경 이력을 읽기 위한 MSK 인증 설정
database.history.producer.security.protocol: Kafka 토픽에 대한 보안 프로토콜 설정으로
SASL_SSL을 사용
database.history.kafka.topic: 변경 이력을 전송할 Kafka 토픽의 이름
database.history.kafka.bootstrap.servers: Kafka 브로커의 부트스트랩 서버 주소를 제공
database.server.name: RDS 인스턴스의 이름 또는 ID
database.history.producer.sasl.client.callback.handler.class 및
database.history.consumer.sasl.client.callback.handler.class:
IAM 클라이언트 콜백 핸들러 클래스를 지정.
database.history.consumer.security.protocol: 변경 이력을 읽을 때 사용하는 보안 프로토콜로
SASL_SSL을 사용
database.port: MySQL 데이터베이스에 연결할 때 사용할 포트번호
include.schema.changes: 스키마 변경을 포함할지 여부를 나타내는 불리언 값
database.hostname: MySQL 데이터베이스 서버의 호스트 이름 또는 IP 주소
database.password: MySQL 데이터베이스에 연결할 때 사용할 암호
database.history.consumer.sasl.mechanism: MSK 변경 이력을 읽을 때 사용하는
IAM 인증 메커니즘
database.include.list: 스트리밍할 MySQL 데이터베이스의 이름 목록을 포함합니다.
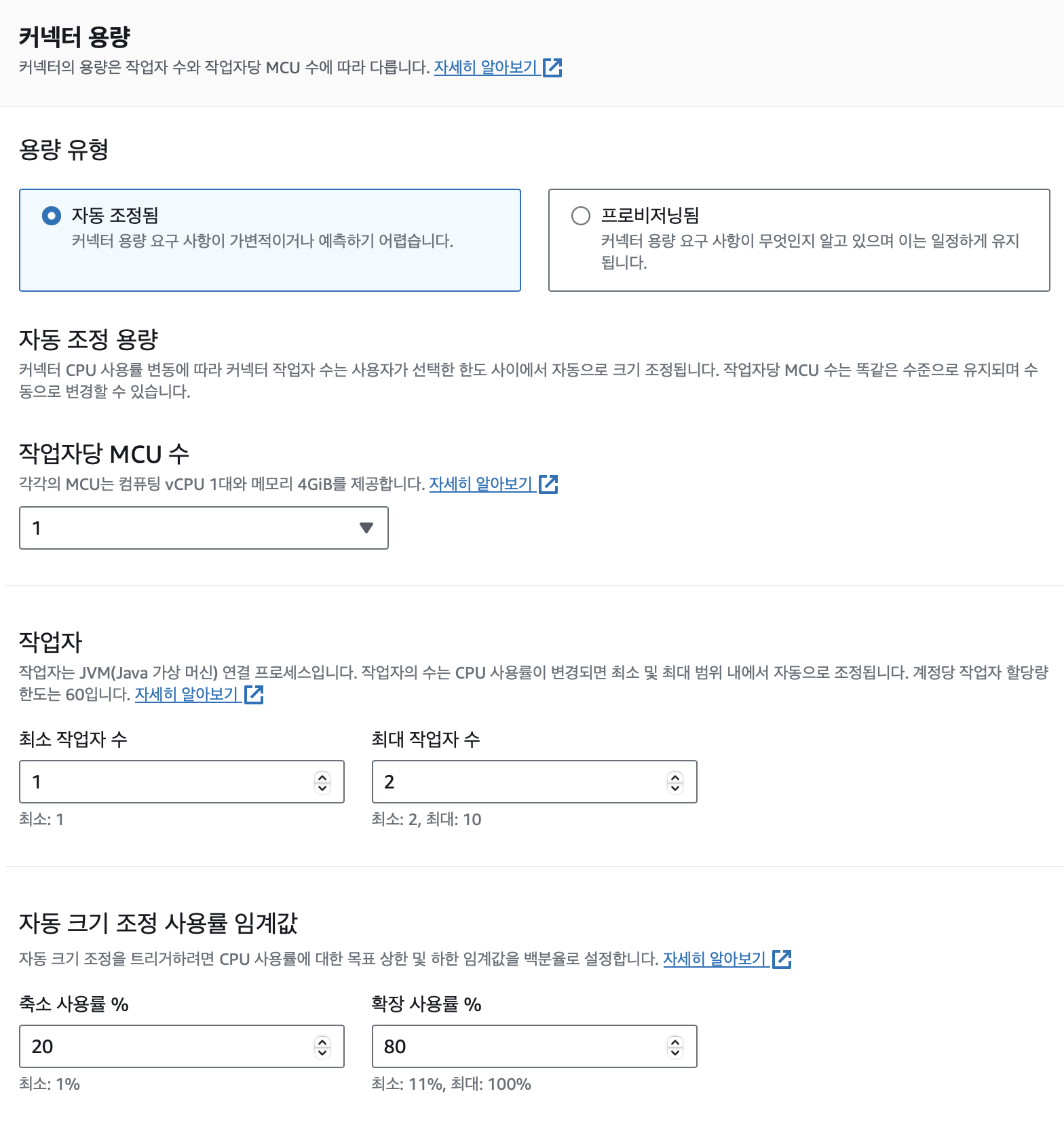
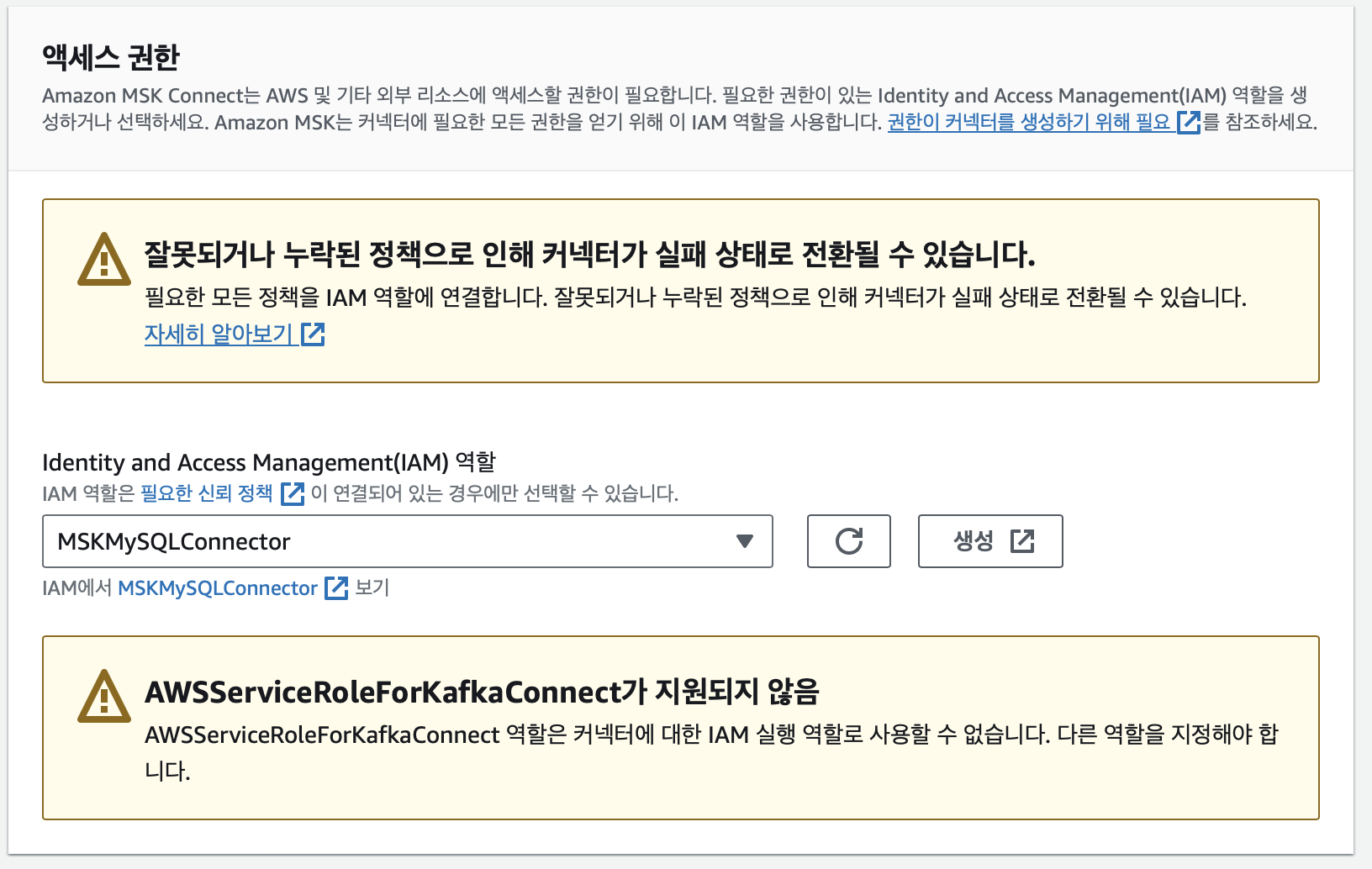
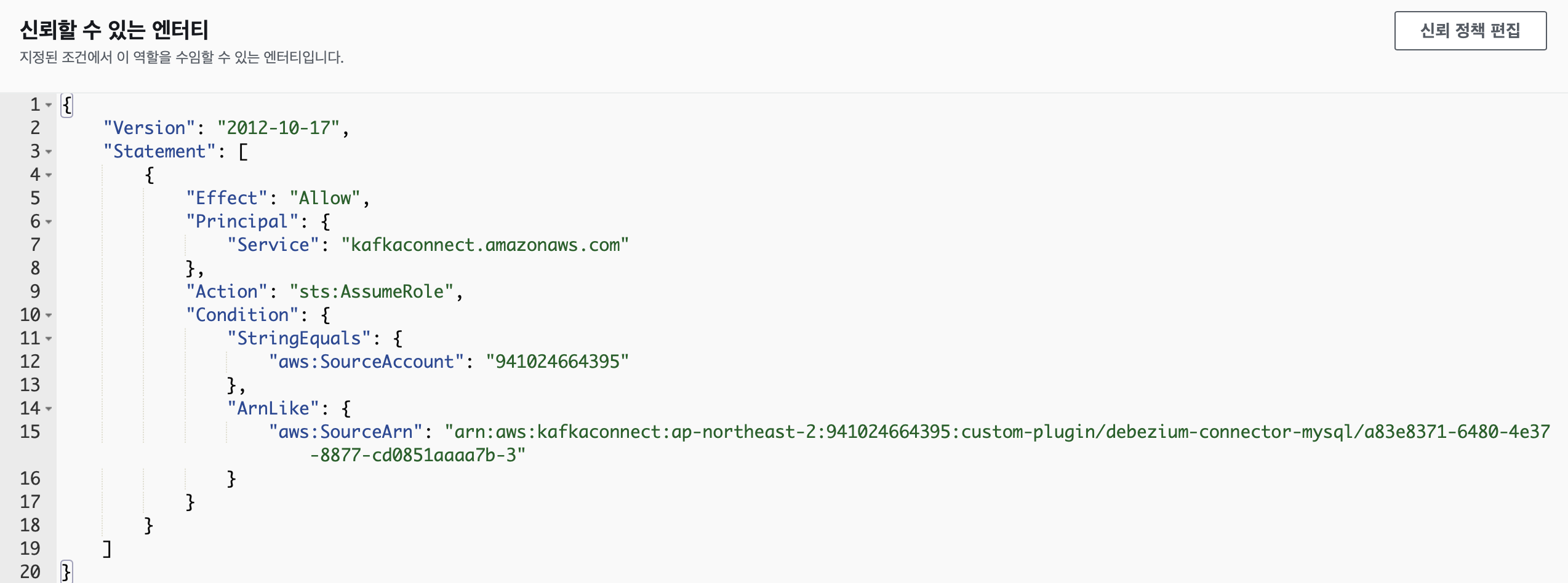
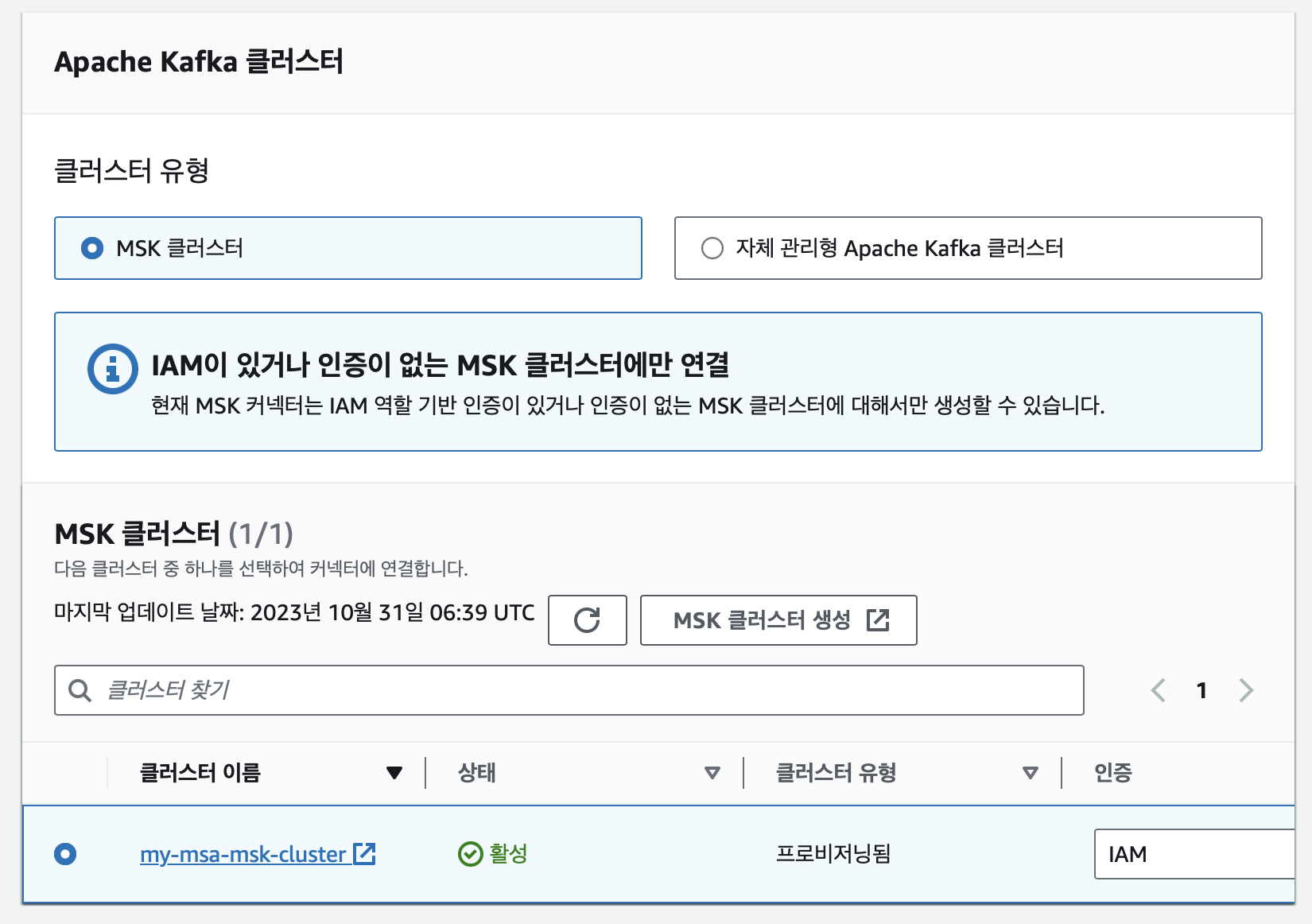
위와 같이 설정하며 해당 신뢰정책을 가진 IAM Role을 생성하여 선택하였다.
스트림 데이터를 활용한 대시보드 구축
통계 API 작성 (dash-board app)
- order-app에서 conn/database.py 파일을 복사해서 dashboard-app으로 붙여넣기
- models/tb_order.py 파일도 동일하게 진행
- crud 디렉토리에 statistics.py 생성 후, 아래 코드 작성
from sqlalchemy.orm import Session
from sqlalchemy.sql import func
from app.models.tb_order import TbOrder
def read_statistics(db: Session):
orders = db.query(func.substr(TbOrder.created, 1, 10).label('created'), func.count(TbOrder.order_id).label('count'))\
.group_by(func.substr(TbOrder.created, 1, 10)).order_by(func.substr(TbOrder.created, 1, 10).asc()).all()
return orders➡️ order table 에서 주문 일자별로 주문수를 카운트하는 쿼리
- main.py에 API 추가
@app.get("/dashboard/statistics")
async def dashboard(db: Session = Depends(get_db)):
return statistics.read_statistics(db)➡️ dashboard 웹페이지에서 호출할 REST API 기입.
Chart.js
- statics/chart.js 파일을 만들어 chart.js 내용을 기입한다.
- dashboard.html 파일에서 아래 내용 추가
<div class="container">
<!-- Content here -->
<div>
<canvas id="myChart"></canvas>
</div>
</div><script src="/dashboard/static/bootstrap.bundle.min.js"></script>
<script src="/dashboard/static/chart.js"></script>➡️ 대시보드에 동적으로 차트를 구현하기위한 div 추가
- script.js에 아래 코드 작성
$(document).ready(function () {
const ctx = document.getElementById('myChart');
var label = []
var data = []
$.ajax({
url: "/dashboard/statistics",
method: "GET",
dataType: "json"
})
.done(function (items) {
for (var item of items) {
label.push(item.created)
data.push(item.count)
}
new Chart(ctx, {
type: 'bar',
data: {
labels: label,
datasets: [{
label: "Count of order",
data: data,
borderWidth: 1
}]
}]
}]
}]➡️ stastics API를 호출해서 일별 통계를 가져오고 차트 div의 그래프를 구성
대시보드 애플리케이션
카프카와 연결하기위한 종속성 설치
pip install kafka-python
pip install websocketsRequirements.txt 업데이트
kafka-python==2.0.2
websockets==10.4Docker 빌드
docker build -t dashboard-app --platform linux/amd64 .Consumer 작성
퍼블릭 액세스가 가능하지 않게 클러스터를 구성했기 때문에 로컬에서 테스트가 불가
따라서 EC2에 올리거나 ECR에 배포해서 테스트 진행
- main.py에 아래 코드 추가
from json import loads
from kafka import kafkaConsumer
@app.websocket("/dashboard/ws")
async def websocket_endpoint(websocket: WebSocket):
await websocket.accept()
consumer = KafkaConsumer('orders',
group_id='my-group',
bootstrap_servers=['b-1.mskcluster2.kk9qho.c2.kafka.ap-northeast-2.amazonaws.com:9092'])
for message in consumer:
print("%s:%d:%d: key=%s value=%s" % (message.topic, message.partition,
message.offset, message.key,
message.value))
websocket.send_text(f"{message.value}")➡️ 주문 애플리케이션과 동일하게 웹소켓을 통해 웹 브라우저와 커넥션을 생성하고
컨슈머가 데이터를 가저오면 비동기로 웹브라우저로 전송
- script.js에 다음 코드 추가
var ws = new WebSocket("ws://localhost:8080/dashboard/ws");
ws.onmessage = function (target) {
print(target)
data = target.data.split("'")[1]
order = JSON.parse(data)
for (var item of data) {
if (item.created == target.created)
item[i].count = count++
ctx.update()
}
};➡️ 웹소켓을 사용해서 작성한 API를 호출하고 변경된 데이터를 응답받아서 해당 일자에
카운트 그래프에 재반영
대시보드 애플리케이션 배포
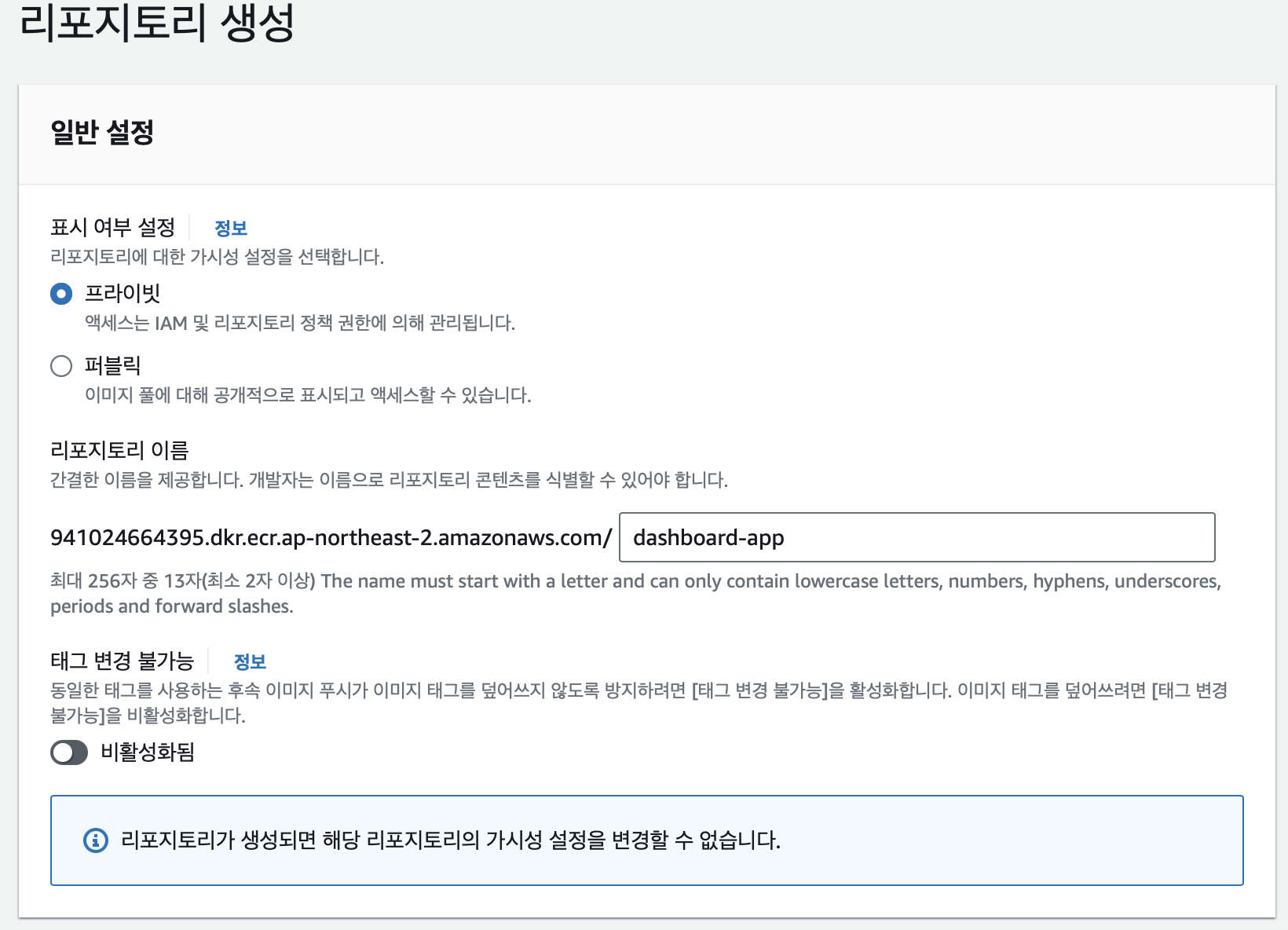
리포지토리 생성 후 이미지를 리포지토리로 푸쉬한다.
리포지토리 생성 및 푸쉬
정상적으로 배포되었다.
TroubleShooting
인스턴스 메타데이터 기입
MSK 클러스터에 접근하기 위한 인스턴스를 만들고 부트스트랩 서버에 접속해서 인스턴스 메타데이터 값을 넣으려고 하니 해당 명령어에서 계속 에러가 났다.
export AWS_REGION=$(curl -s 169.254.169.254/latest/dynamic/instance-identity/document | jq -r '.region')
parse error: Invalid numeric literal at line 1, column 6해당 명렁어는 인스턴스의 메타데이터를 가져와서 AWS_REGION 값을 export하는 구문이다.
하지만 위 에러로 인해
curl -s 169.254.169.254/latest/dynamic/instance-identity/document단독적으로 이 명렁어를 사용하니 401 - Unauthorized 에러가 났다.
그래서 '인스턴스에 iam 권한이 필요한가' 싶어서 ec2-metadata 라는 역할을 만들어서
아래 정책을 넣었다.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "ec2:DescribeInstances",
"Resource": "*"
},
{
"Effect": "Allow",
"Action": "ec2:DescribeInstanceAttribute",
"Resource": "*"
},
{
"Effect": "Allow",
"Action": "ec2:DescribeInstanceStatus",
"Resource": "*"
}
]
}하지만 동일한 401 에러가 반복되었고, .aws/config, credentails 파일에도 직접 계정 인증정보를 넣었으나 해결되지 않았다.
그래서 위 문제를 직접
export AWS_REGION=ap-northeast-2
export AWS_SECRET_ACCESS_KEY=my-secret-access-key
export AWS_ACCESS_KEY_ID=my-access-key-id내용을 기입해서 해결했다.
커넥터 에러
InvalidInput.InvalidConnectorConfiguration
해당 에러는 계속 클래스를 인식못하고 다른 클래스 경로에서 다른 커넥터를 찾았다고 하였다.
제대로 JAR 파일도 설정해서 플러그인을 만들었는데도 같은 에러가 발생하였다.
내가 해결한 방법이 맞는지 모르겠지만 JAR파일이 아닌 커넥터 파일들을 .Zip파일로 압축 후 S3에 업로드하여 더이상 해당 에러가 뜨질 않았다.
UnkownError. Unknown (1)

위 에러를 해결하니 새로운 에러가 발생하였다.
다시 생성하여도 같은 에러가 발생하여서 CloudWatch에 로그 연결 후 다시 실행하였다.
발생의 원인은
io.debezium.DebeziumException: The MySQL server is not configured to use a ROW binlog_format, which is required for this connector to work properly. Change the MySQL configuration to use a binlog_format=ROW and restart the connector.해당 에러로 MySQL 서버의 binlog_format 설정이 connector가 요구하는 설정과 일치하지 않았다는 것이었다.
따라서 RDS 파라미터 그룹을 생성하여 해당 파라미터를
binlog_format=ROW로 수정하고 변경하였다.
UnkownError. Unknown (2)
또 새로운 에러다.
The 'schema.history.internal.kafka.topic' value is invalid: A value is required
The 'schema.history.internal.kafka.bootstrap.servers' value is invalid: A value is required현재 내 Connector 구성에는
schema.history.internal.kafka.topic, schema.history.internal.kafka.bootstrap.servers에 대한 값을 지정해주지 않았다.
schema.history.internal.kafka.topic: 스키마 변경 내역을 저장할 kafka 토픽의 이름을 지정
schema.history.internal.kafka.bootstrap.servers: kafka 브로커의 부트스트랩 서버 목록 지정
하는 설정이다.
따라서 해당 설정값들을 Connector 구성에 기입하였다.
