
MSK 란

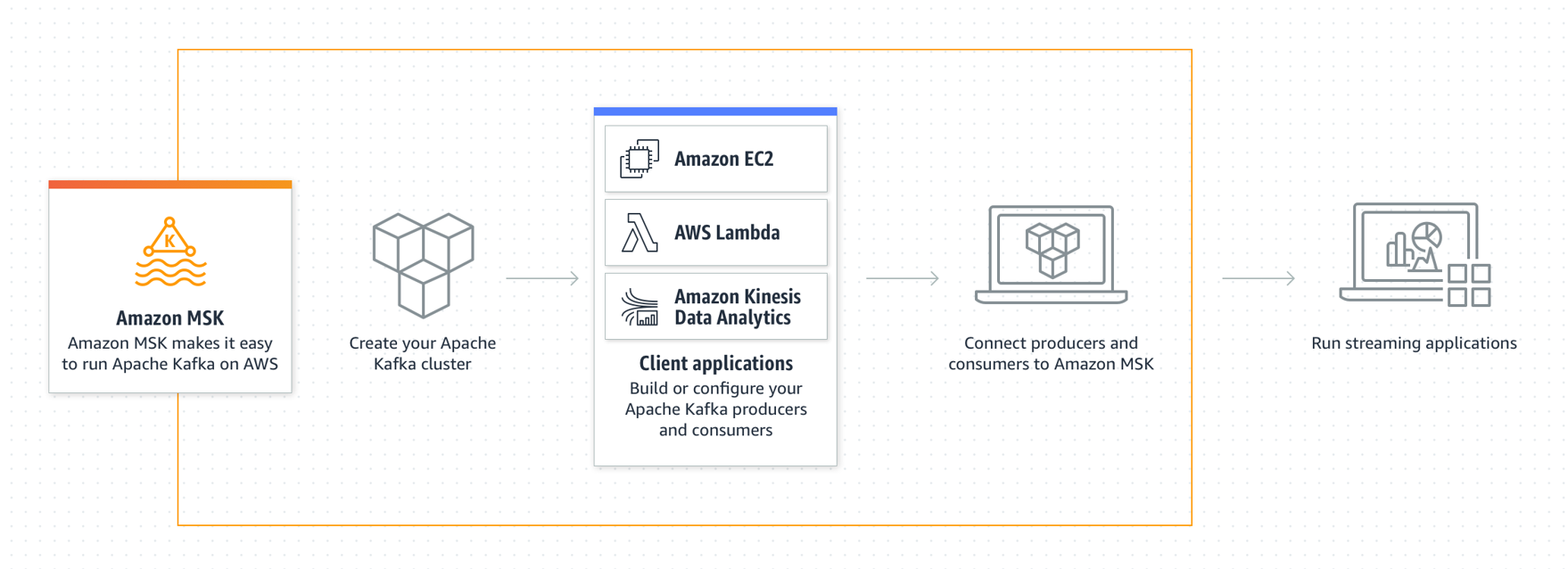
- Apache Kafka를 사용하여 스트리밍 데이터를 처리하는 애플리케이션을 빌드하고
실행할 수 있는 완전 관리형 서비스 - Amazon MSK는 클러스터 생성, 업데이트 및 삭제 등에 필요한 제어 영역 작업을 제공
- Apache Kafka의 배포 모범 사례를 기반으로 하는 설정과 구성으로
고가용성 Apache Kafka 클러스터를 만들 수 있음. - 클러스터 상태를 지속적으로 모니터링하고, 애플리케이션 가동 중지 없이
비정상적인 노드를 자동으로 교체 - 미사용 데이터를 암호화하여 Apache Kafka 클러스터를 안전하게 유지
스트리밍 데이터
스트리밍 데이터란?
- 스트리밍 데이터는 수천개의 데이터 원본에서 연속적으로 생성되는 데이터
- 보통 데이터 레코드를 작은 크기(KB 단위)로 동시에 전송
- 스트리밍 데이터에는 모바일이나 웹 애플리케이션을 사용하는 고객이 생성하는 로그파일,
전자 상거래 구매, 게임 내 플레이어 활동, 소셜 네트워크의 정보, 주식 거래소, 지리공간 서비스, 연결된 디바이스의 텔레메트리, 데이터 센터의 계측 등 다양한 데이터가 포함
스트리밍 데이터의 이점
- 스트리밍 데이터 처리는 새로운 동적 데이터가 생성되는 시나리오 대부분에서 유용
- 기업은 최소-최대 컴퓨팅 롤링 같은 기본적인 처리와 시스템 로그 수집 등
간단한 애플리케이션으로 시작 - 애플리케이션이 기계 학습 알고리즘을 적용하고 데이터에서 심도 있는 통찰력을 추출하는 등
더욱 정교한 형태의 데이터 분석을 수행 - '타임 윈도우 감소' 알고리즘과 같은 스트림 및 이벤트 처리 알고리즘이 적용되어 통찰력이 강화
Apache Kafka

Apache Kafka란?
- 실시간을 기록 스트리믈 게시, 구독, 저장 및 처리할 수 있는 분산형 데이터 스트리밍 플랫폼
- 여러 소스에서 데이터 스트림을 처리하고 여러 사용자에게 전달하도록 설계
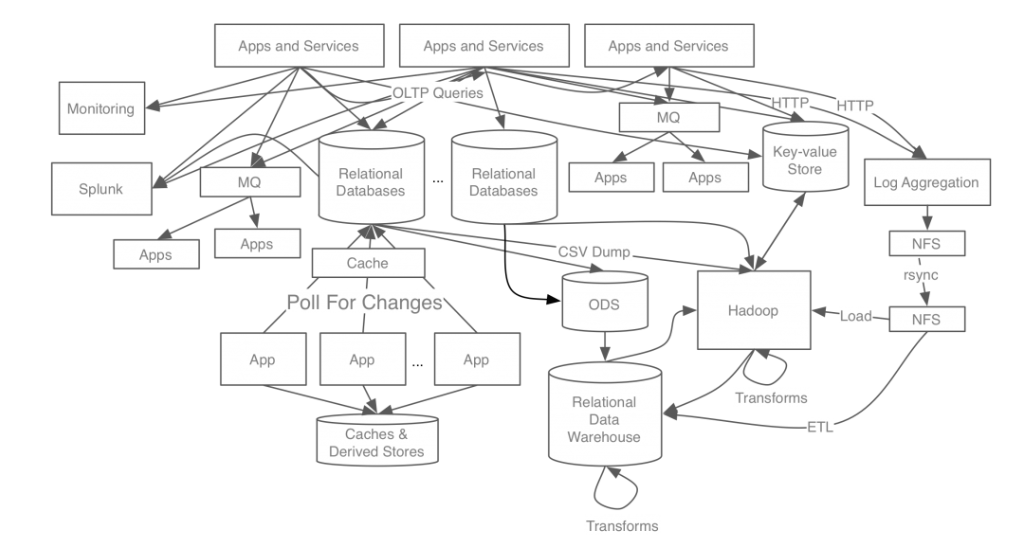
카프카 개발 전 링크드인 데이터 처리 시스템
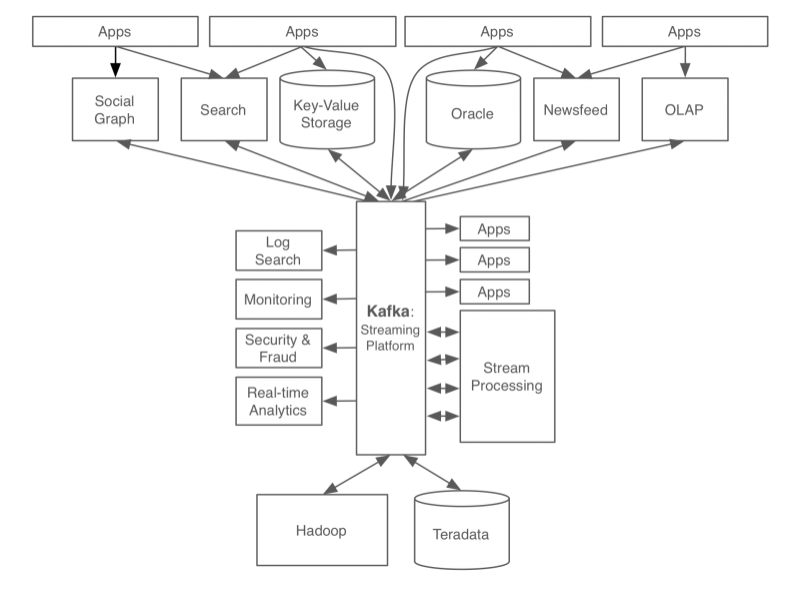
카프카 개발 후 링크드인 데이터 처리 시스템
Apache Kafka 개념
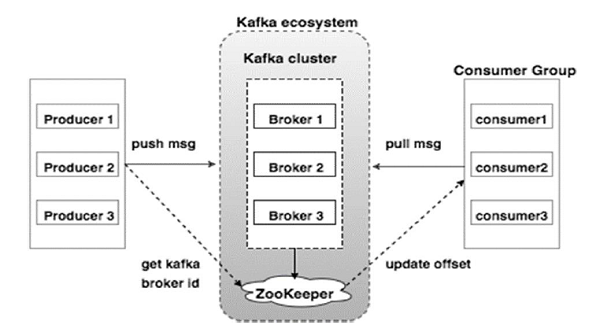
Kafka Cluster: 카프카의 브로커들의 모음
➡️ Kafka는 확장성과 고가용성을 위하여 broker들이 클러스터로 구성
Broker: 각각의 카프카 서버. 동일 노드에 여러 브로커를 띄울 수 있음
Zookeeper: 카프카 클러스터 정보 및 분산처리 관리 등 메타 데이터 저장.
카프카를 띄우기 위해 반드시 실행되어야 함
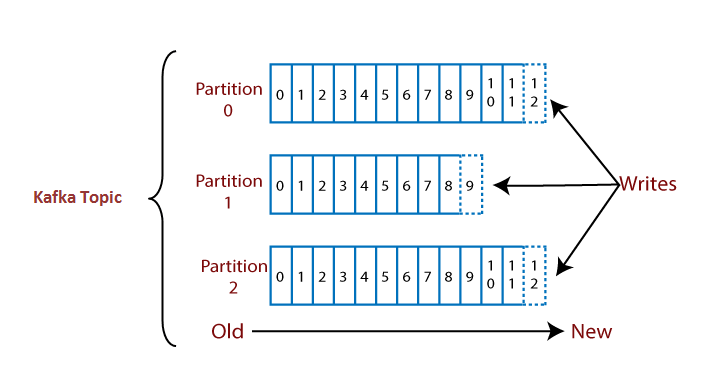
Topic: 메세지를 구분하는 단위
- 파일 시스템의 폴더, 메일함과 유사
Partition: 메세지를 저장하는 물리적인 파일
- 한개의 토픽은 한 개 이상의 파티션으로 구성
Offset: 파티션 내 각 메세지의 저장된 상대적 위치
- 프로듀서가 넣은 메시지는 파티션의 맨뒤에 추가 (Queue)
- 컨슈머는 오프셋을 기준으로 마지막 커밋 시점부터 메세지를 순서대로 읽어서 처리
- 파티션의 메세지 파일은 처리후에도 계속 저장되어 있으며 설정에 따라 일정시간 뒤 삭제
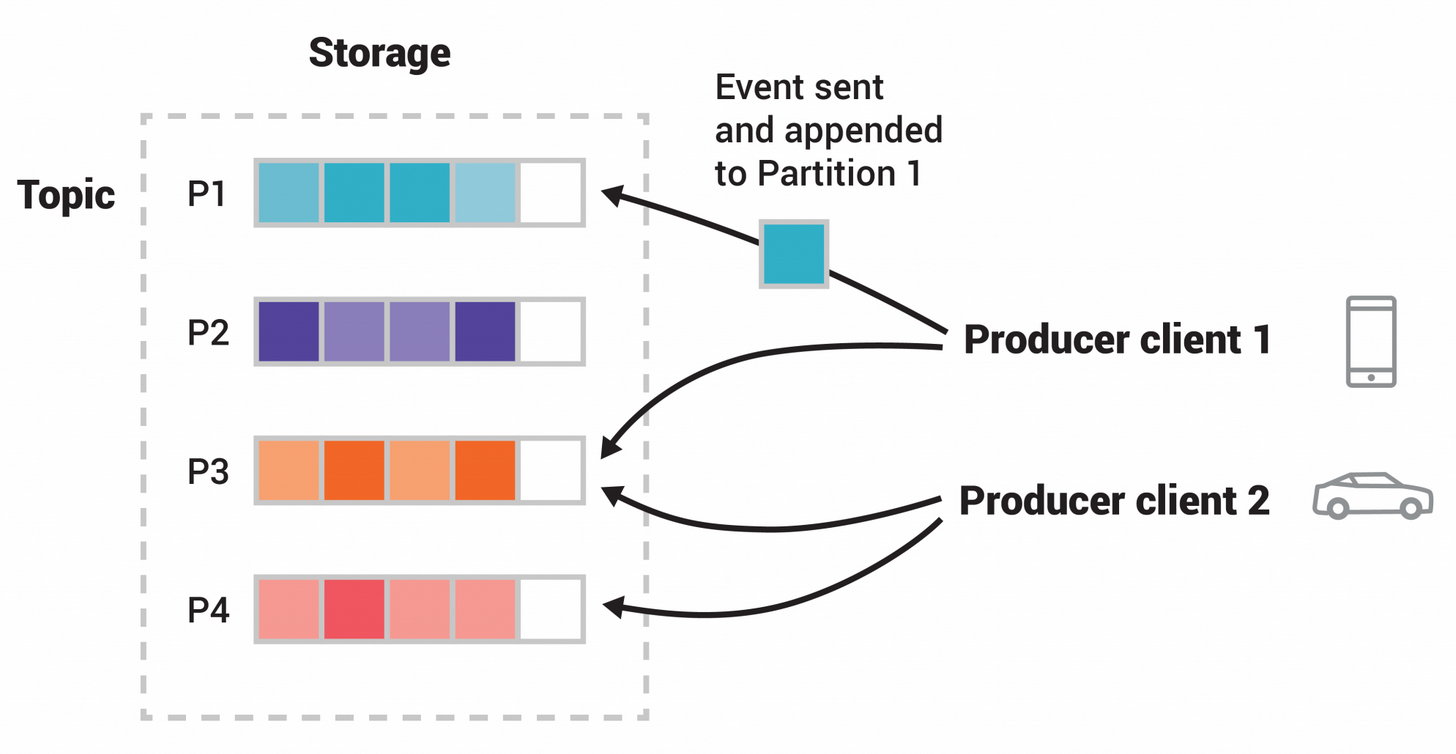
Producer
- 메세지(이벤트)를 발행하여 생산(Write)하는 주체
- 프로듀서는 메세지 전송 시 토픽을 지정
- 파티션은 라운드로빈 방식 혹은 파티션 번호를 지정하여 넣을 수 있음
- 같은 키를 갖는 메세지는 같은 파티션에 저장되며 순서 유지
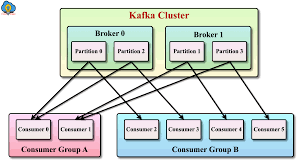
Consumer
- 메세지(이벤트)를 구독하며 소비(Read)하는 주체
Consumer Group
- 메세지를 소비하는 컨슈머들의 논리적 그룹
- Topic의 파티션은 컨슈머 그룹과 1:N 매칭 관계로 동일 그룹 내 한 개의 컨슈머만 연결 가능
- 파티션의 메세지는 순서대로 처리되도록 보장
- 특정 컨슈머에 문제가 생겼을 때 Failover를 통한 리밸런싱 가능
- 보통 파티션과 컨슈머는 1:1이 Best Practice로 봄
MSK 장점
완벽한 호환성
- Apache Kafka를 자동으로 실행하고 관리
- 기존 Apache Kafka 애플리케이션은 AWS로 마이그레이션하여 실행
완전 관리형
- Apache Kafka 환경 관리의 운영 오버헤드에 대한 걱정 없이 스트리밍 애플리케이션 생성에 집중
- 자동으로 Apache Kafka 클러스터와 Apache Zookeeper 노드의 프로비저닝, 구성 및 유지를 관리
- Amazon MSK는 AWS 콘솔에 주요 Apache Kafka 성능 지표를 표시
탄력적인 스트림 처리
- SQL, Java 또는 Scala로 작성된 완전 관리형 Apache Flink 애플리케이션을 실행하여
Amazon MSK 내에서 데이터 스트림을 처리하도록 탄력적으로 확장
뛰어난 가용성
- Apache Kafka 클러스터를 생성하고 AWS 리전 내에서 다중 AZ 복제를 제공
- 클러스터 상태를 지속적으로 모니터링하고, 구성 요소가 실패할 경우 자동으로 대체
뛰어난 보안
- VPC 네트워크 격리, 컨트롤 플레인 API 권한 부여를 위한 AWS IAM, 저장 데이터 암호화,
전송 데이터 TLS 암호화, TLS 기반 인증서 인증, AWS Secrets Manager를 통해 보호되는 SASL/SCRAM 인증, 데이트 플레인 권한 부여를 위한 Apache Kafka ACL(액세스 제어 목록) 지원을 비롯하여 Apache Kafka 클러스터를 위한 다양한 수준의 보안을 제공
MSK 동작 방식
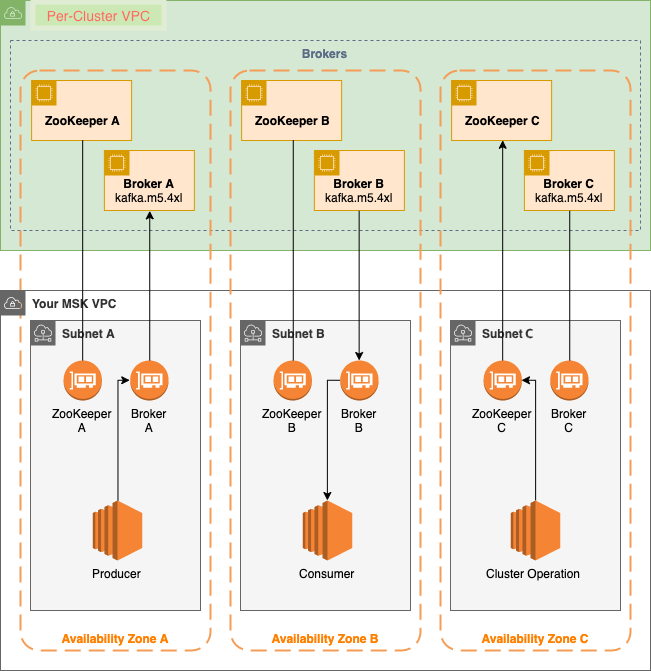
Broker 노드
- Amazon MSK 클러스터를 생성할 때 Amazon MSK를 생성
Zookeeper 노드
- 아파치를 생성
Producer, Consumer, Topic Producer
- Apache Kafka 데이터 영역 작업을 사용하고 주제를 만들고, 데이트를 생성 및 소비
클러스터 작업
- AWS 콘솔, AWS CLI 또는 SDK에서 제어 영역 작업을 수행하는데 필요한 제어 영역 작업을 수행

Junior DevOps Engineer