
다이나믹 프로그래밍(DP)
큰 문제를 부분 문제로 나눈 후 답을 찾아가는 과정에서, 계산된 결과를 기록하고 재활용하며 문제의 답을 구하는 방식 즉 해당 문제는 특정 문제해결에 패러다임으로 볼 수 있다.
DP를 쓰는 이유
그렇다면 왜 DP를 사용하는가? 사실 DP는 일반적인 재귀 방식과 DP는 매우 유사하다. 큰 차이점은 일번적인 재귀를 단순히 사용시 동일한 작은 문제들이 여러번 반복되어 비율적인 계산이 될 수 있다는 것이다.
예를 들어 대표적인 피보나치 수열이 그렇다. 피보나치 수열을 재귀함수로 풀었을 때 f(n) = f(n - 1) + f(n + 2)가 된다 하지만 이는 각 함수를 1번씩 호출하면 동일한 값을 두번씩 구하게 되고 이로 인해 100번째 피보나치 수를 구하기 위해 호출 되는 함수는 기하급수적으로 증가를 하게 된다.
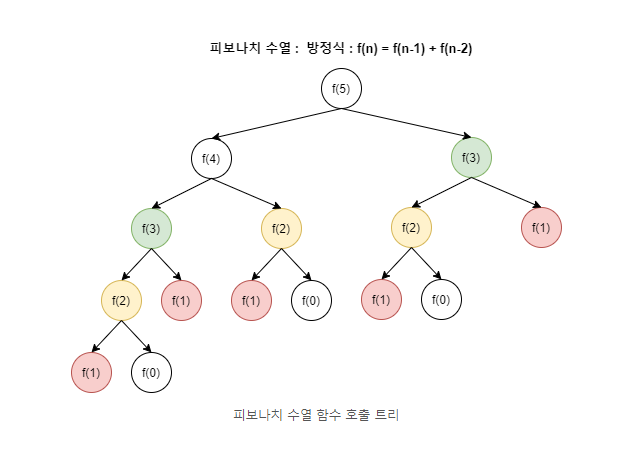
그러나 이러한 문제를 한 번 구한 작은 문제의 결과 값을 저장해두고 재사용 한다면 어떨까? 앞에서 계산된 값을 다시 반복할 필요학 없이 약 200회 내에 계산이 가능하다.
즉, 매우 효율적으로 문제를 해결할 수 있게 된다. 시간 복잡도를 기준으로 아래와 같이 개선이 가능하다.
O(n^2) -> O(f(n))로 개선
DP의 사용 조건
위에서 DP의 가장 큰 장점이 있듯이 무조건적으로 선행되어야 하는 조건들이 몇가지 있다.
1. 겹치는 부분 문제(Overlappiung Subproblems)
2. 최적 부분 구조(Optimal Substructure)
Overlappiung Subproblems
DP는 기본적으로 문제를 나누고 그 문제의 결과 값을 재활용해서 전체 답을 구한다. 그렇기에 동일한 작은 문제들이 반복하여 나타난 경우에 사용이 가능하다!!
즉, 부분 문제의 결과를 저장하여 재 계산하지 않을 수 있어야 한다.
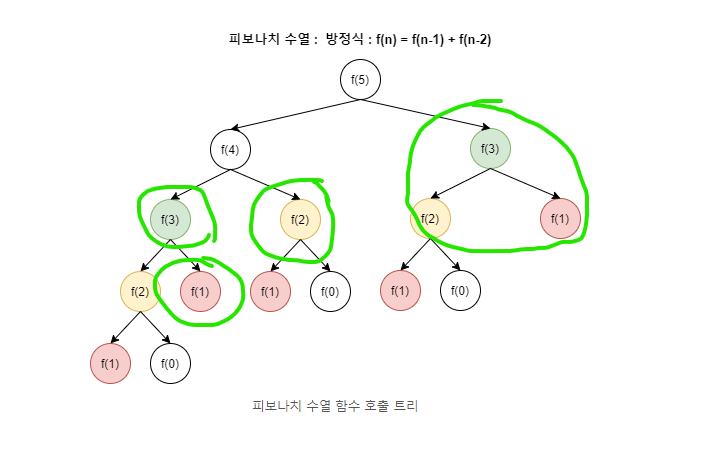
예를 들어 f(3) , f(2) , f(1) 이 있다고 가정을 하자 위에 피보나치로 예시를 들자면 3 , 2, 1은 반복하여 나타난 경우 해당 문제는 DP를 통해 해결이 가능한 문제가 된다.
최적 부분 구조
부분 문제의 최적 결과 값을 사용해 전체 문제의 최적 결과를 낼 수 있는 경우를 의미한다. 즉 작은 부분 문제에서 구한 최적의 답으로 합쳐진 큰 문제의 최적의 답을 수할 수 있어야 한다는 것이다.
그렇다면 아직도 전반적인 개념에 대해서는 어렵다는 감이 있을 것이다. 예를 들어 fibo(n - 1)를 구하기 위해서는 다시 fibo(n - 2) + fibo(n - 3)의 값을 구하기 위한 여정을 떠나야 한다. 하지만 fibo(n - 2) 는 사전에 fibo(n)을 구하기 위해서 fibo(n - 2)를 구할것이 아닌가?!! 즉 중복되게 되는데 이는 최적 부분 구조를 만족하게 된다. 그렇기에 문제의 크기에 상관없이 fibo(n - 1)은 언제나 일정한 값을 가진다.
그렇다면 이러한 중복되는 연산과정을 줄이기 위해서 필요로 할 것이 메모제이션 개념이다.
DP 사용하기
지금까지 적어나간 내용을 이해했다면 DP는 하나의 문제를 해결하기 위한 방법론이다! 라는 것을 직감하실 수 있을것이다.
그래서 이번에는 DP에 사용하기 좋은 유형들인지를 체크할 사항들을 알아보고자 한다.
📌첫 번째 DP로 풀 수 있는 문제인지 확인한다.
사실상 이 부분이 가장 난제이다. DP의 조건 부분에서 DP로 풀 수 있는지 체크를 하고 현재 직면한 문제가 작은 문제들로 이루어진 하나의 함수로 표현될 수 있는지를 판단해야한다.
즉 위에서 쓴 조건들을 먼저 체크를 해야한다.
하지만 보통은 특정 데이터 내 최대화 / 최소화 계산을 하거나 특정 조건 내 데이터를 숫자 세기 / 확률 등의 계산의 경우 DP로 풀 수 있는 경우가 아니지 않나 싶다.
📌두 번째 문제의 변수 파악
DP는 현재 변수에 따라 그 결과 값을 찾고 그것을 전달하여 재사용 하는 것을 거친다. 즉 문제 내 변수의 개수를 알아내야 한다는 것이다.
예를 들어, 피보나치 수열에서는 n 번째 숫자를 구하는 것이므로 n이 변수가 된다. 그 변수가 얼마이냐에 따라 결과값이 다르지만 그 결과를 재사용하고 있다.
또한 문자열간의 차이를 구할 때는 문자열의 길이, Edit 거리 등 2가지의 변수를 사용한다.
마지막으로 유명한 배낭 채우기 문제에서는 index, 무게로 2가지의 변수를 사용한다.
즉 해당 문제에서 어떤 변수가 있는지 파악해야 그에 따른 답을 구할 수 있다.
📌세 번째 변수 간 관계식 만들기(점화식)
변수들에 대한 결과 값이 달라지지만 동일한 변수값인 경우 결과는 동일하다. 또한 우리는 그 결과값을 그대로 이용할 것이므로 그 관계식을 만들어 낼 수 있어야한다.
하지만 해당 관계식은 짜는 것 자체가 어려울 수 있다. 그렇기에 많이 풀어보는 수밖에 없다.
📌네 번째 메모하기
작은 문제들을 나누어 그것을 재사용하기 때문에 가장 중요한 메모가 필요로 하다. 메모제이션이 필요로 하는데 이는 변수 간 관계식까지 정상적으로 생성됐다면 이때 변수 간에 기록하는 행위를 메모제이션이라고 부른다.
보통은 배열로 쓰이며 크게는 3차원까지 사용되는 경우가 있다.
📌다섯 번째 기저 상태 파악하기
여기 까지 알아봤다면 가장 작은 문제의 상태를 알아야한다.
예를 들어 피보나치 수열에서는 f(0) = 0, f(1) = 1는 고정적인 기저 상태 값이며 이후 두 가지의 숫자를 더해가면서 문제를 해결해 나간다.
하지만 이는 피보나치 수열은 매우 간단했지만 문제에 따라 파악하기는 어려워진다.
📌여섯 번째 구현에 대한 종류
다이나믹 프로그래밍에 대한 방법은 크게 두 가지로 나뉜다. 크게 두 가지로 나뉘는 이유는 우리는 처음에 개념을 짚고 넘어갔을 때 계산된 결과를 기록하고 재활용한다고 했었다. 그렇다면 크게 상향식 , 하양식이 있을것이라고 생각 할 수 있다. 그렇기에 방법에는 두 가지로 나뉜다.
타뷸레이션
타뷸레이션 방식은 상향식 접근 방법으로서 작은 부분 dp를 확인하고 점화식을 통해서 풀면서 올라가는 형식이다. 그렇기에 점차적으로 큰 문제를 풀면서 올라가는 형식이다. 그렇기에 보통은 for문을 통해서 구현이 가능하다.
public static int fibDP(int n) {
int[] dp = new int[n < 2 ? 2 : n + 1];
dp[0] = 0;
dp[1] = 1;
for (int i = 2; i <= n; i++) {
dp[i] = dp[i - 1] + dp[i - 2];
}
return dp[n];
}메모이제이션
큰 문제에서 하위 문제를 확인해가며 진행되는 형식이다. 즉 계산이 필요한 순간만을 계산이 진행되면서 큰 문제를 부분 문제로 쪼개면서 답을 구하는 형식이다. 그렇기 때문에 주로 재귀 호출을 통해서 문제를 해결하는 경향이 있다.
public static int fibDP(int n) {
if (n <= 2) {
return 1;
}
if (dp[n] != 0) {
return dp[n];
}
dp[n] = fibDP2(n - 1) + fibDP2(n - 2);
return dp[n];
}마치면서
이렇게 다이나믹 프로그래밍을 알아봤는데 이렇게 정리를 했다고 한들 마찬가지로 나에게 다이나믹 프로그래밍은 아직은 나에게 어렵다. 왜냐하면 문제를 메모제이션을 찾고 그것을 재귀함수를 짜기에는 어렵기 때문이다. 하지만 문제를 계속해서 풀어나간다면 언젠가는 DP를 마스터하는 날이 오지 않을까 싶다. (그날까지 열심히 달리자✌️✌️)
자료 제공
https://hongjw1938.tistory.com/47#2.-dp%EB%A5%BC-%EC%93%B0%EB%8A%94-%EC%9D%B4%EC%9C%A0
https://didu-story.tistory.com/220
