
Semantic Segmenatation
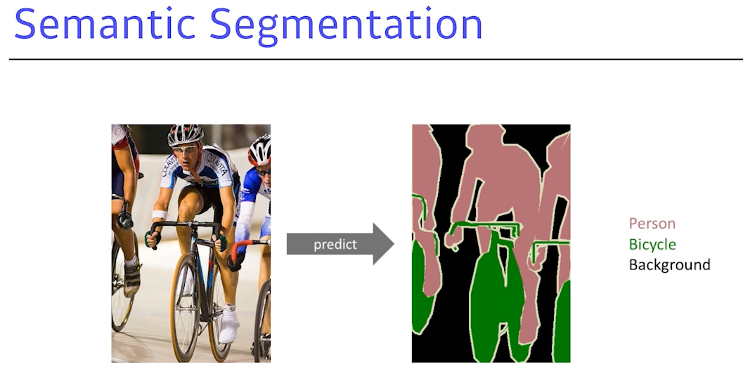
= dense classification
Ex) 자율주행, 운전보조장치
기존 CNN 구조
Fully Convolutional Network
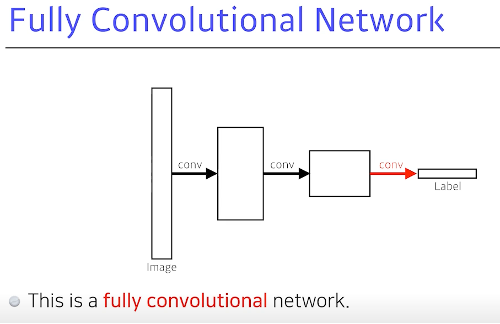
Dense 를 없애는게 기본 목적 하지만 파라미터의 숫자는 동일하다는 것.
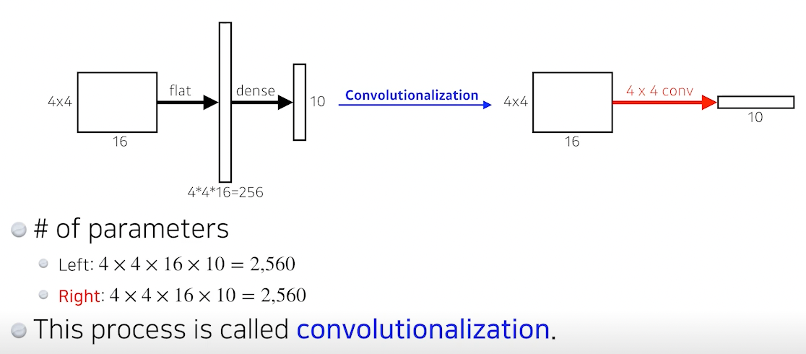
이를 convolutionalization이라 한다.
파라미터의 수는 동일한데 이 짓을 왜하느냐??
FCN은 핵심 아이디어는 FC layer를 사용하지 않고 1x1 convolutional layer를 사용한것이다. 기존의 FC layer 의 경우 입력의 모든 차원을 출력의 모든 차원과 연결하도록 가중치를 훈련 시키므로 입력을 더 크게 만들면 더 많은 가중치가 필요하다. 즉, 고정된 입력 크기를 가질 수 밖에 없다. 또한, 이미지의 공간적 정보가 소실 된다. 이를 보완하기 위해 convolutional layer 는 각 이미지를 flattening 하는 것이 아닌 다음과 같이 각 channel 의 이미지 위치마다 flattening 하여 얻는 벡터들을 fully-connected 하는데, 이것은 1x1 convolution 연산과 동일하다.
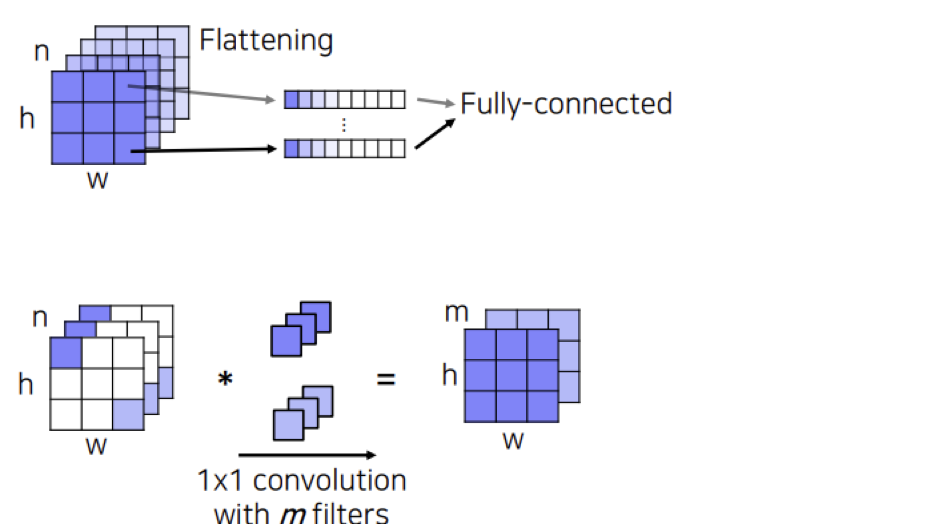
그래서 convolutional layer 는 입력사이즈에 independent 하기 때문에 입력사이즈의 제한을 받지 않고, 공간 정보를 보존할수 있게 되는 이점이 있다.
Convolutionalization 을 통해 얻은 heatmap은 하나의 class를 대표하는 대략적인(coarse) 정보이다. 하지만 우리의 목적은 dense prediction 이기 때문에 coarse map 을 dense map 으로 복원하는 deconvolution 이 필요하다.
-> 기존 FC 이용시 이미지의 크기는 항상 동일해야했음. 하지만 FCN을 사용하여 입력 이미지의 크기 값이 고정되지 않아도 되며, 이를 히트맵 형식으로 리턴 받으므로 단순 classification 외에도 어떤 이미지가 어느 부분에 있는지, 즉 semantic segmentation 의 가능성이 보인다.
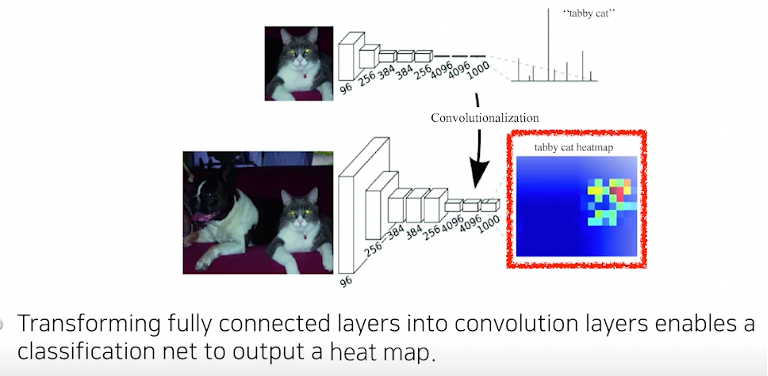
TODO
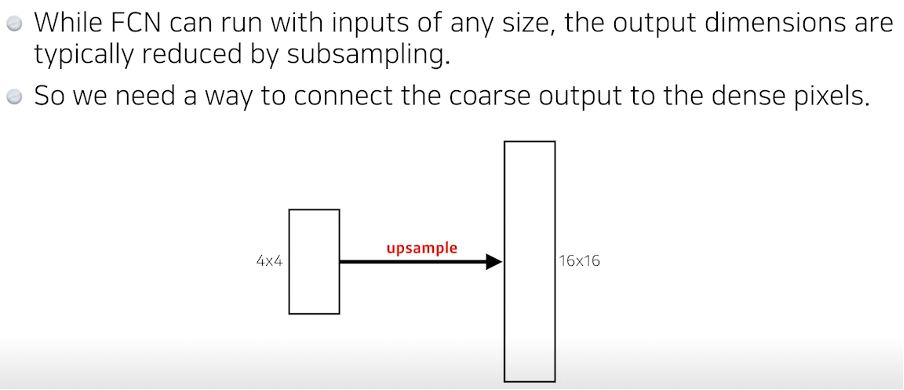
하지만 입력 100 X 100 이미지는 FCN을 통해 아웃풋이 줄 수 밖에 없다. 따라서 이를 다시 원래 사이즈로 바꿔주는 과정이 필요하다. -> 늘리는 과정이 다양!
Deconvolution(conv transpose)
= Conv의 역연산
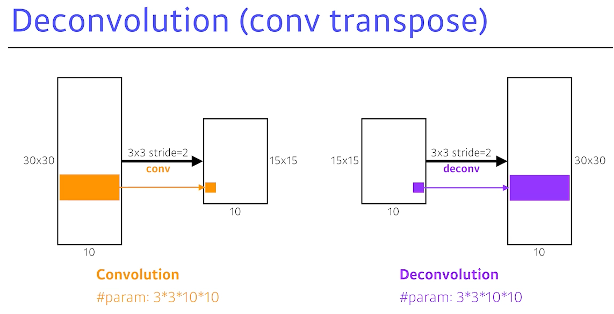
하지만 Conv의 역연산이란 것은 완벽하게 존재할 수는 없다. 다만 그렇게 생각하면 편해
R-CNN
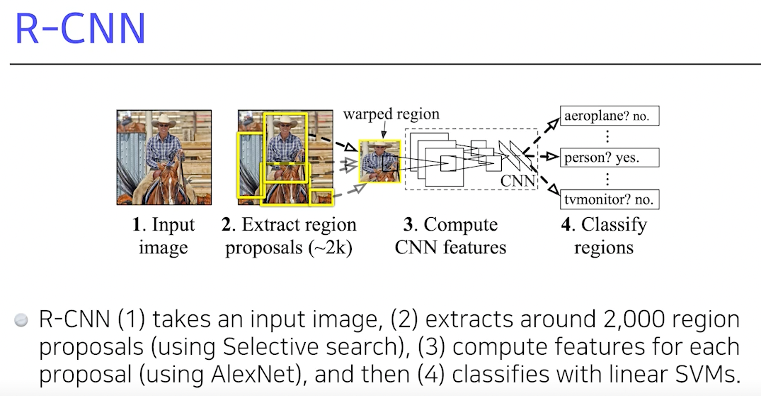
이미지에서 2000개 가량의 region을 뽑는다.
->Region에 대한 feature를 alexnet 통해 얻고
->Linear SVM 으로 분류를 하자
딱 봐도 오래 걸려보인다.

SPPNet

그러나 SPPNet은 입력 이미지에 대해 CNN 연산을 먼저 적용한 후 feature map에 기반한 region propoal 과정을 거치기 때문에, 1번의 CNN 연산 과정을 가진다.
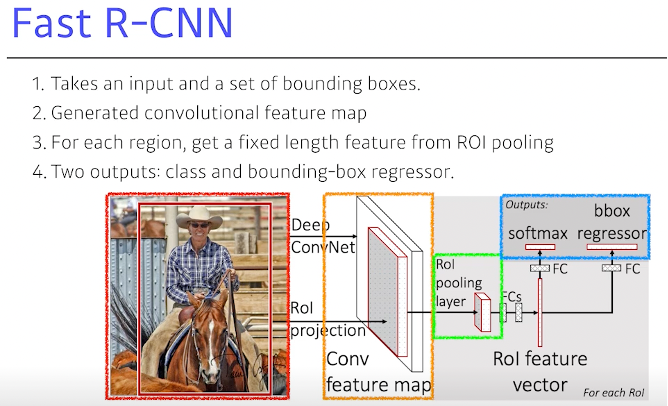
Fast R-CNN
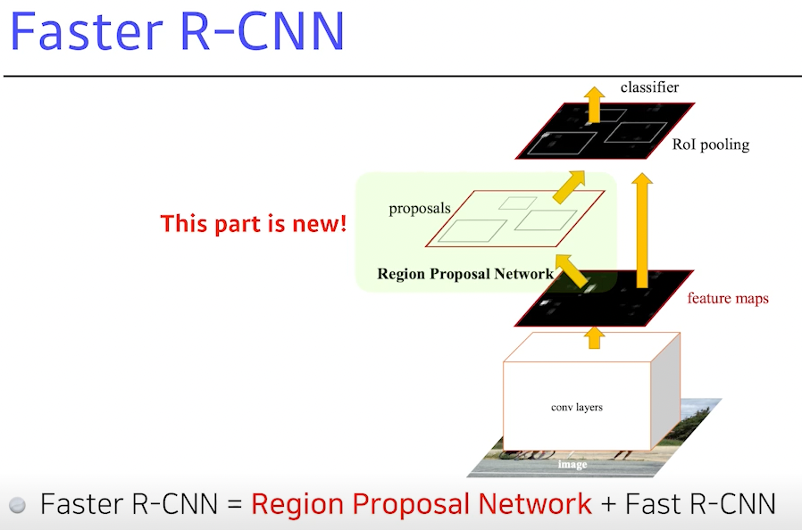
Faster R-CNN
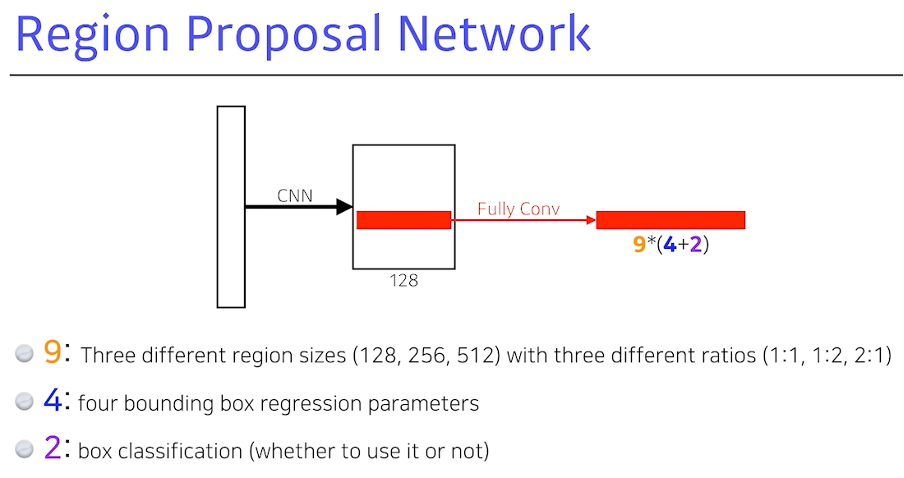
RPN의 역할 이 bounding에 물체가 있을 것 같다 혹은 아니다.
Anchor 박스의 필요(이 물체의 바운딩 박스의 크기를 미리 정해놓는다.)
채널의 개수
YOLO
한번만 딱 봐 -> 속도가 빠름

