
Modern Convolutional Network
ILSVRC

AlexNet 2012
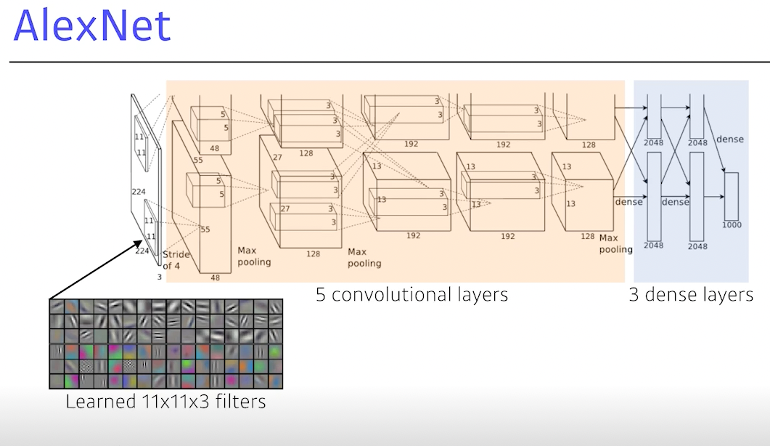
사실 11X11 필터 쓰면 파라미터가 너무 많이 필요해서 좋은 선택은 아니다.
Key Ideas
ReLU activation(activation이 가져야할 첫번째 덕목은 nonlinear)
2 GPU
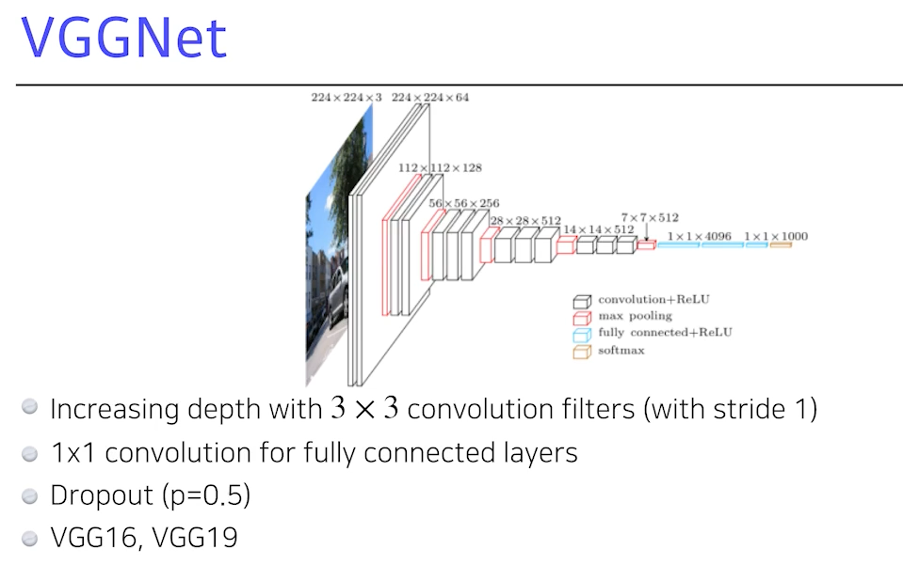
VGGNet 2014
왜 3X3 filter???
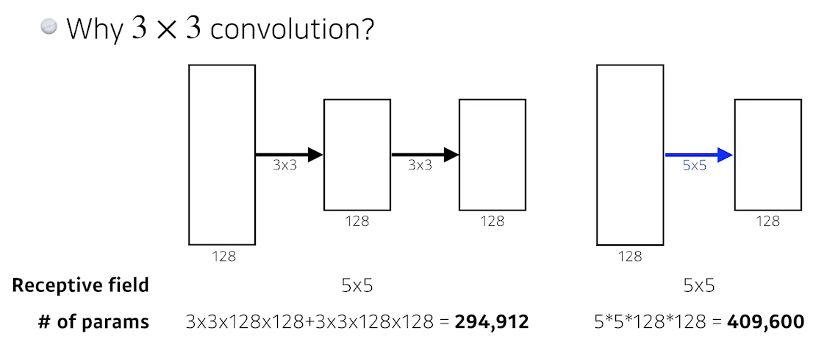
Receptive field
= 하나의 output 값이 만들어지는데 영향을 끼치는 입력들의 개수
Receptive field는 같지만 파라미터의 개수는 여러 층 쌓은게 더 적다.
GoogleNet 2015
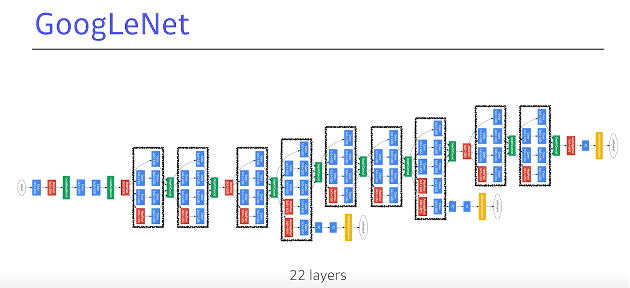
network in network(NIN구조)
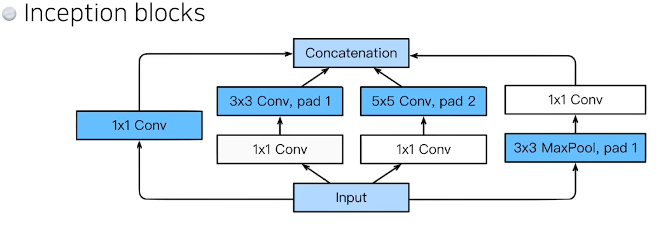
입력값 하나가 여러 path로 갈라졌다가 하나로 합쳐진다.
핵심은 1X1 Conv
Inception blocks의 효과는???
->전체적인 net의 parameter를 줄여준다.

1X1 Conv을 활용했을 때 파라미터 수의 차이
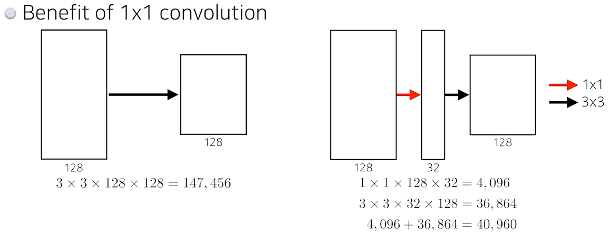
파라미터의 수는 30퍼센트 줄이되 입력->출력은 동일하다.
ResNet 2015
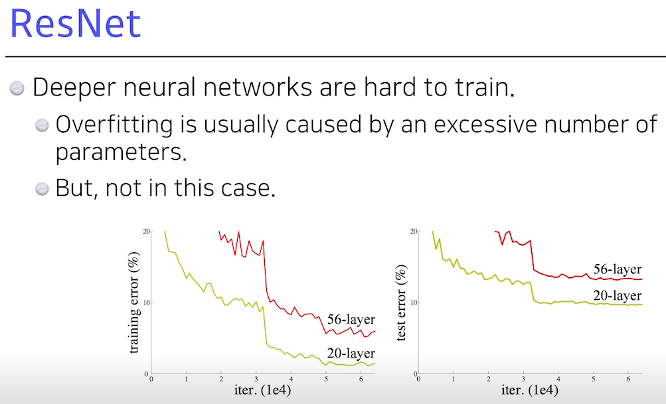
오버피팅
= trainingerror 낮아지지만 testerror는 높아진다. Epoch이 진행될수록
하지만 여기서는 아니다. 둘다 낮아지긴하지만 training은 잘됐지만 test는 성능이 별로야. 그리고 레이어가 너무 쌓이면 학습자체가 안돼 like 56layer
따라서 ResNet은 이를 해결하기 위해 identity map을 사용하여 residual connection 사용
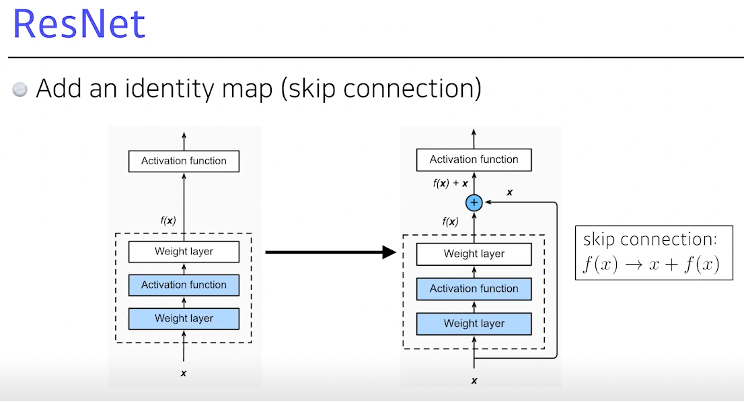
Conv layer가 학습 하고자 하는 quantity는 residual, fx가 실제로 학습하는 것은 그 차이이다.
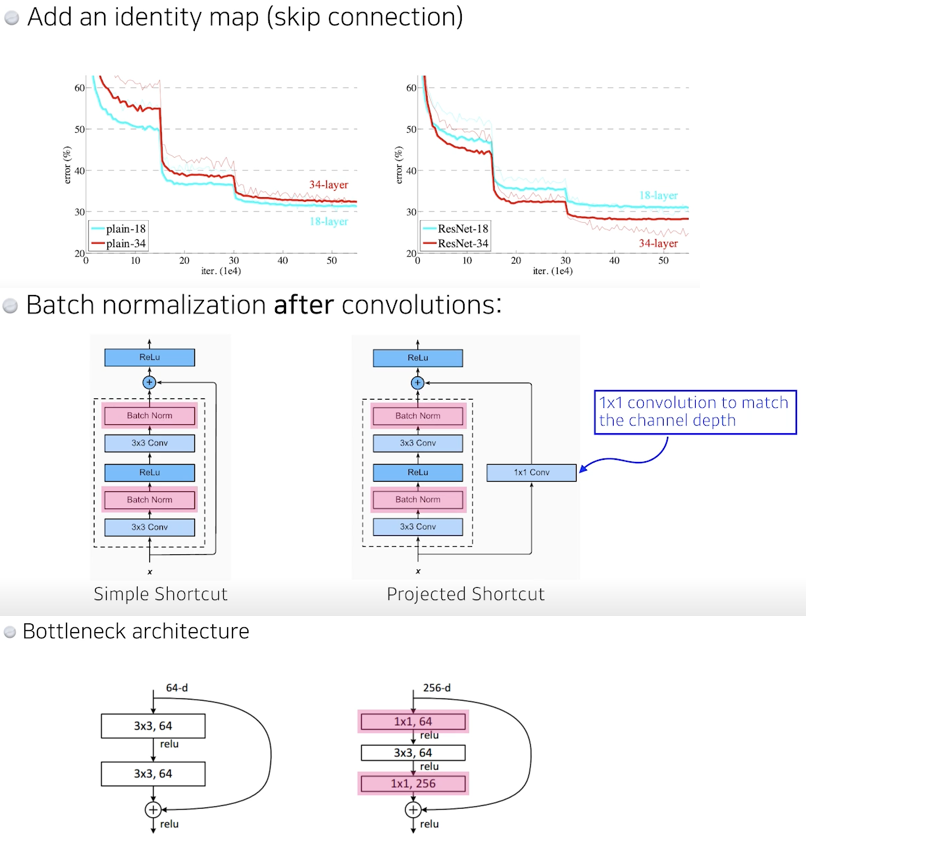
3X3 전에 input을 줄이기 위해 한번 후에 늘리기 위해 한번
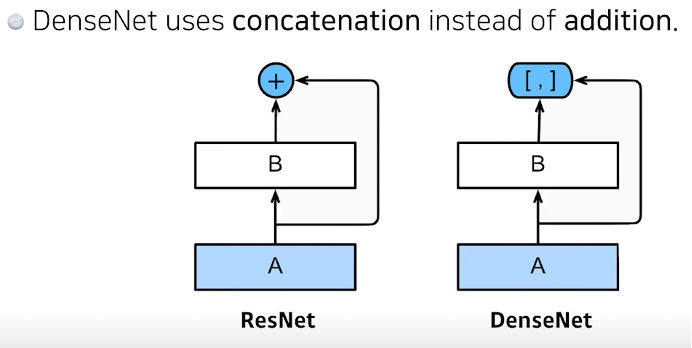
Concat은 대신에 채널이 기하급수 적으로 늘어난다. -> params도 계속 늘어나
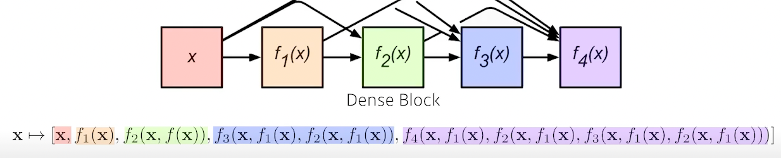
따라서

DenseBlock에서 concat으로 늘리다가 TransitionBlock에서 줄이고 다시 Dense….
그래서 넷을 하나 만들어서 무언가를 해야겠다 -> Resnet이나 Densenet 구조 하나 골라서 하면 대부분 잘 되는것을 볼 수 있다.


반 걸음씩 이라도 가보자.