#230203 금
5일차에 했던 것을 이어서 <열혈 c++ 프로그래밍>으로 부족했던 c++ 학습을 채워보겠다.
1. 헤더 <<Done!
2. 복사 생성자 : 오늘의 주제
3. 상속
1. 복사 생성자란?
코드를 짜다 보면 대입하는 경우가 굉장히 많이 생긴다. 버블 정렬에서 다음과 같은 코드를 쓰면
int tmp = array[i];
array[i] = array[i+1];
array[i+1] = tmp;(코드 고작 세 줄에 대입만 무려 세 번이네..)
이러한 a=b 형식의 대입은 얕은 복사에 속한다. 얕은 복사는 단순한 코드에서는 괜찮지만, 복사하는 대상이 복잡한 객체라면 문제가 생길 수 있다. (2.에서 구체적으로)
한편 그런 오류가 없는 깊은 복사를 위한 연산자와 생성자도 있다. 복사 생성자는 어떤 객체가 생성되자마자 다른 객체를 복사하는 생성자이고, 복사 대입 연산자는 이전에 생성된 객체에 다른 객체를 복사하는 연산자이다. 사실 생성되자마자/이전에 생선된 으로 구분하는 것보다 생성자냐 연산자냐로 차이를 이해하는 게 더 쉬운 것 같다. 생성자가 호출되면 멤버변수를 초기화된 클래스가 만들어지는 것처럼, 복사생성자가 호출되면 멤버변수가 복사 대상의 멤버변수와 동일하게 초기화된 클래스가 생성되는 것이다. 연산자가 호출되면 이미 존재하던 두 객체를 대상으로 연산을 수행하는 것처럼, 복사 대입 연산자가 호출되면 이미 존재하는 두 객체에 대하여 한 객체를 다른 객체에 복사하는 연산을 수행한다.
이것만 보면 복사가 별 게 아닌 것 같지만 사실 복사를 배울 때 좀 더 중요한 건 얕은 복사와 깊은 복사이다.
2. 얕은 복사와 깊은 복사
둘 중 뭐가 더 좋은 거냐 하면 당연히 깊은 복사이다. 얕은 복사는 다음과 같은 문제들을 일으킬 수 있다.
1) 참조변수를 포함하고 있는 복잡한 객체 A, B에 대해서 B에 A를 복사한 후, A와 B를 개별관리하려고 한다. 깊은 복사를 하면 개별관리가 가능하고, 얕은 복사를 하면 개별관리가 불가능하다. B를 바꾸면 A도 같이 바뀌고, A를 바꾸면 B도 같이 바뀌기 때문이다.
물론 1. 복사생성자란?에서 예로 든 버블 정렬 같은 단순 대입 코드는 얕은 복사를 걱정할 일이 없다. 참조를 사용하지 않은 코드에서는 대입 연산자를 사용할 때 얕은 복사를 크게 신경쓰지 않아도 된다. 얕은 복사는 A를 B에 복사할 때 A가 참조타입의 객체일 때, 혹은 참조타입의 객체를 가지고 있는 클래스일 때 발생하는 것이기 때문이다.
2) 동적 배열 할당을 할 때 A의 변수들이 가리키는 메모리와 B의 변수들이 가리키는 메모리가 같아져 소멸자를 실행하면 B가 먼저 메모리를 반환해 A가 반환할 메모리가 없어지고 결국 컴파일 에러가 난다.
따라서 올바른 코드라면 당연히 깊은 복사가 이루어져야한다.
그러면 얕은 복사와 깊은 복사를 비교해보자.
당신은 평행 세계를 코드로 구현하는 이상한 취미를 갖고 있다. 닥터 스트레인지 1호와 2호는 대부분의 조건을 같게 하되, 1호는 눈이 두 개고 2호는 세 개라는 차이가 있다. 각자 만들어주기 귀찮아서 스트레인지 클래스 1호를 만들고 2호에는 1호를 복사한 후 눈 개수만 다르게 해주려고 한다.

1) 복사 생성자 이용 <깊은 복사>
#include <iostream>
using namespace std;
class Stranger{
int eyes;
int mp; //magical power..
public:
Stranger(int eyes=2, int mp=100){this->eyes = eyes; this->mp = mp;}
Stranger(const Stranger& copy); //복사 생성자
void print(){cout<<"눈 개수:"<<eyes<<endl;}
void eye(int n){eyes = n;}
};
Stranger::Stranger(const Stranger& copy){
eyes = copy.eyes;
mp = copy.mp;
} //깊은 복사 구현
int main(){
Stranger Docs1;
Stranger Docs2 = Docs1; //복사
Docs2.eye(3); // 2호 눈 개수를 변경
Docs1.print();
Docs2.print();
}2) 복사 대입 연산자 이용 <깊은 복사>
#include <iostream>
using namespace std;
class Stranger{
int eyes;
int mp; //magical power..
public:
Stranger(int eyes=2, int mp=100){this->eyes = eyes; this->mp = mp;}
Stranger& operator=(const Stranger& copy); //복사 대입 연산자
void print(){cout<<"눈 개수:"<<eyes<<endl;}
void eye(int n){eyes = n;}
};
Stranger&Stranger::operator=(const Stranger& copy){
eyes = copy.eyes;
mp = copy.mp;
return *this;
} //깊은 복사 구현
int main(){
Stranger Docs1;
Stranger Docs2 = Docs1; //복사
Docs2.eye(3); // 2호 눈 개수를 변경
Docs1.print();
Docs2.print();
}3) 얕은 복사
Stranger(const Stranger& copy) 처럼 깊은 복사 생성자나 Stranger::operator=(const Stranger& copy)처럼 복사 대입 연산자를 따로 구현하지 않으면 얕은 복사가 이루어진다. Stranger 클래스를 선언할 때 자동으로 만들어지는 디폴트 복사 생성자(눈에 보이지는 않고 컴파일러 자동으로 만든다)를 사용하게 되기 때문이다.
근데 사실 위에서 만든 닥터 스트레인지 문제는 그냥 복사 생성자와 복사 대입 연산자가 어떻게 생겼는지 차이만 보려고 만든 거고, 깊은 복사 생성자를 구현하지 않아도 사실 컴파일 에러는 안 난다. 1호와 2호 눈 개수가 같이 바뀌는 오류도 나지 않는다. 아까도 말했듯이 깊은 복사 생성자를 만들지 않아서 오류가 생기는 경우는 복사하는 객체가 참조변수를 가지고 있거나, 동적 배열인 경우이기 때문이다.
그러면 이제 고통받은 우리의 뇌가 한 가지 의문을 던진다. ..참조랑 동적 배열을 안 만들면 되는 거 아닌가요?
3. 참조는 왜 필요한가요?
Q. 귀찮은데 그냥 참조를 안 쓰면 얕은 복사도 안 일어나는 거 아닌가요?
A. 그게 그렇게 간단한 문제가 아닙니다..
참조는 매우 중요한 친구이다. 왜 중요한지 얘기하려면.. 포인터의 이야기까지 가게 된다. 이야기의 순서는 이렇다 :
1) 포인터와 참조는 무엇인가? (차이점)
2) 포인터와 참조가 필요한 이유는 무엇인가?(공통점)
3) 2)에 의하면 포인터만 써도 충분할 것 같은데 참조라는 개념을 왜 굳이 새로 만들었는가?
### 1) 포인터와 참조는 무엇인가? (차이점)
포인터.. 한 땐 내가 너무 두려워했지만 지금 보니 별 거 아닌 것도 같은 친구이다. 포인터는 어떤 변수, 객채의 주소를 가리키고 있는 것이다.
int *p = &a : 포인터 p는 a의 주소값을 가리킨다. 만약 p를 출력하려고 하면 a가 저장된 위치가 출력된다.
참조는 주소값 대신 변수나 객체 그 자체를 할당받는다.
int &r = a : r은 a를 참조한다. 만약 r을 출력하려고 하면 a의 값이 출력될 것이다. 만약 r의 값을 바뀌면 a도 r을 따라 똑같이 바뀔 것이다.
둘의 선언 방식이 비슷하게 생겨서(& 때문에 그렇게 보임..) 처음 공부할 땐 참조랑 포인터랑 비슷한 개념인 줄 알고 헛갈리고 그랬다. 포인터를 선언할 때 쓰는 &와 참조변수를 선언할 때 쓰는 &랑 서로 관련 없는 거라고 생각하면 편하다.
그리고 참조는 별명 만들기라고 생각하면 훨씬 쉽다. int &r = a에서 r은 a의 새 별명, 혹은 애칭이라고 할 수 있다. 같은 존재지만 필요에 따라 a라고 부를 수도 있고 r이라고 부를 수도 있다.
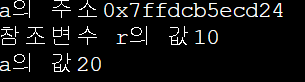
int a=10;
int *p = &a; //p는 a의 주소를 가리킴
cout<< "a의 주소" << p;
int &r = a; //r는 a를 참조함
cout<< "참조변수 r의 값" << r;
r= 20; //r의 값을 바꾸면 a도 변경됨
cout<< "a의 값" << a; 를 실행하면 다음과 같은 결과가 출력된다 :
2) 포인터와 참조가 필요한 이유는? (공통점)
개념을 보면 참조와 포인터가 아주 다른 별개의 존재 같지만 하는 일이 비슷할 때도 있다.
예를 들어 우리가 코드에서 엄청나게 큰 클래스나 구조체를 관리한다고 해보자. 그런데 함수에 구조체를 넘겨줘야 하는 경우가 발생한다.
struct Account
{
string name;
int account;
int balance;
int statement[];
}
//Account는 명의, 계좌번호, 잔액, 매일매일의 거래내역 등 아주 많은 정보가 저장되는 구조체이다.
void function(Account a)
//구조체 입력을 받아 거래내역을 갱신하는 함수가 있다.
int main(){
Account jhbank; //bank_account라는 Account 타입의 구조체를 만들었다.
...
function(jhbank); //함수에 bank_account를 구조체를 넘겼다.
}만약 function에 jhbank 구조체를 통째로 넘겨주면 void function(Account a) 함수 정의에 따라 a에 jhbank가 복사된다. 그리고 함수는 입력 구조체의 거래내역을 갱신하라는 명령에 따라 a의 사람들의 거래내역을 갱신했다(코드에 구현하지는 않았음). 그러면 a는 jhbank를 복사한 것일 뿐이므로 a의 거래내역이 바뀐다고 jhbank의 거래내역도 같이 갱신되지는 않을 것이다. 하지만 우리에게 필요한 것은 jh 은행 통장을 사용하는 사람들의 거래내역 갱신이다. 따라서 void function(Account a)를 void function(Account *a) 혹은 void function(Account& a)로 수정하면 될 것이다. 전자의 경우 function은 a가 가리키고 있는 구조체 jhbank의 거래내역을 갱신할 것이고, 후자의 경우 function은 a가 참조하고 있는 jhbank의 거래내역을 갱신할 것이다.
이렇듯 복잡한 구조체나 클래스를 사용해야 할 때 참조와 포인터가 있으면 관리가 용이해진다.
3) 포인터로는 부족한가요? 참조는 왜 필요한가요?
처음에 제시했던 질문
'참조를 안 쓰면 얕은 복사도 없는 거 아닌가요? 참조라는 개념이 대체 왜 필요하죠??!'에 답할 때가 드디어 왔다.
2)에서처럼 복잡한 구조체의 어떤 변수를 가리키고 싶으면 포인터도 있는데 왜 꼭 참조라는 개념까지 써야할까? 포인터 대신 참조를 써야하는 상황은 어떤 것일까? 뭐.. 원래의 나였다면
왜 참조까지 필요한가요?
ㄴ 널 괴롭히기 위해서
(아님)
이러고 놀면서 시작했을 텐데 지금 너무 졸려서 그럴 힘이 없으니 pass..
2)처럼 참조랑 포인터랑 둘 다 쓸 수 있는 상황이면 나름 참조가 포인터보다 좋은 점이 있다.
1 - 메모리가 필요 없음 : 참조변수는 객체의 다른 이름일 뿐, 참조변수와 객체가 서로 다른 존재가 아니다. 따라서 참조변수를 선언해도 참조변수를 위한 메모리가 딱히 필요하지 않다.
2 - 코드가 더 간결함 : 어떤 객체에 변화를 주고 싶을 때 포인터로 접근하면 늘 *나 & 를 써줘야하는데 참조를 쓰면 한 번만 &쓰고 뭘 안 써도 돼서 좋음ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ 극강의 귀차니즘 ..하지만 읽은 사람에게도 좋지 않을까?ㅎ
당연히 참조는 쓸 수 없고 포인터만 쓸 수 있는 경우도 아주 많다. 동적 메모리 할당, 동적 배열 할당, 주소 출력 등등.. 이런 건 포인터만의 전문 분야이다. 그리고 사실 참조가 아예 메모리를 안 써서 그렇지 포인터도 불필요한 메모리를 아낄 수 있도록 해주는 좋은 친구이다. 2)에서 설명했던 은행 예시에서 함수에 구조체 전체를 넘겨주면 복사에 의해 메모리를 아주 많이 쓰게 되지만, 포인터를 이용해 구조체의 주소를 넘겨주면 포인터를 위한 메모리만 추가하면 되므로 메모리를 아낄 수 있다.
하여튼 쓰다보니 진심돼서 상속까지는 못 할 것 같다.. 머릿속에 이리저리 떠다니던 포인터, 참조, 복사를 한 번에 정리할 수 있어 좋았다. 쓰다보니 잘 몰랐던 것도 알게 돼서 좋았다. 이제 다시는 헛갈릴 일 없을 것 같다. 말투가 초딩 때 쓰던 일기처럼 됐다. 왜지?
