
📊 Clustering(군집화)
📌 클러스터링이란?
- 정의
- 비지도 학습
- 사전정보(label)가 없는 자료에 대해 컴퓨터가 스스로 패턴을 찾아 여러 개의 군집을 형성함
- 분포된 데이터들 사이에 임의의 초기값을 지정한 후 점차 데이터 분포의 중앙으로 이동하여 군집화시킨다.
📌 계층적 클러스터링이란?
- 정의
- 개별 데이터 간의 거리에 의하여 가장 가까운 대상부터 시작하여 군집화 진행
- 군집화 과정을 통해 나무 모양의 계층적 구조를 형성
- 장점
- 군집이 형성되는 과정을 정확하게 파악 가능
- 단점
- 대용량 데이터의 군집화를 분석하기 어렵다.
📌 비계층적 클러스터링이란?
- 정의
- 초기 K값(군집개수, 군집 중심값)을 정한 후, 가장 가까운 개체를 하나씩 포함해 나간다.
- 장점
- 대용량 데이터를 빠르고 쉽게 분석 가능
- 단점
- 초기 K값에 따라 군집 결과가 달라진다.
📌 K-Means에서 최적의 K값을 정하는 방법
- 방법
방법1) 계층적 군집화를 통해 K값 유추
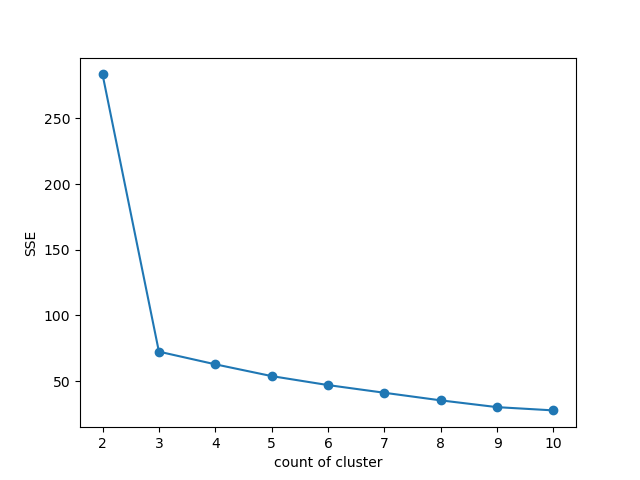
방법2) 엘보우(elbow) 기법 - 클러스터 간 SSE의 차이를 이용 → 많이 사용함
방법3) 실루엣(silhoutte) 기법 - 클러스터 간 실루엣 계수값을 수평 막대 그래프로 표현
📊 비계층적 클러스터링 실습
📌 비계층적 클러스터링 K-Means 실습
- 1. 라이브러리 Import
[ K-Means 모델 ]
- 비계층형 클러스터링 모델에서 가장 많이 사용함
- 데이터가 비선형일 때, 성능이 떨어짐import matplotlib.pyplot as plt from sklearn.datasets import make_blobs from sklearn.cluster import KMeans
- 2. 데이터 준비
x, y = make_blobs(n_samples=150, n_features=2, centers=3, cluster_std=0.5, shuffle=True, random_state=0) print(x) # [[ 1.04829186 5.03092408] # [ 1.35678894 4.36462484] # [ 2.21180137 0.47061579] # [ 0.92466065 4.50908658] # [-1.09468591 2.54679975] # [-0.3920267 2.19069942] # [-2.80339892 3.24469156] # [ 2.80230706 0.79508453] # [ 2.27719914 1.06450082] # [ 1.45131429 4.22810872]]
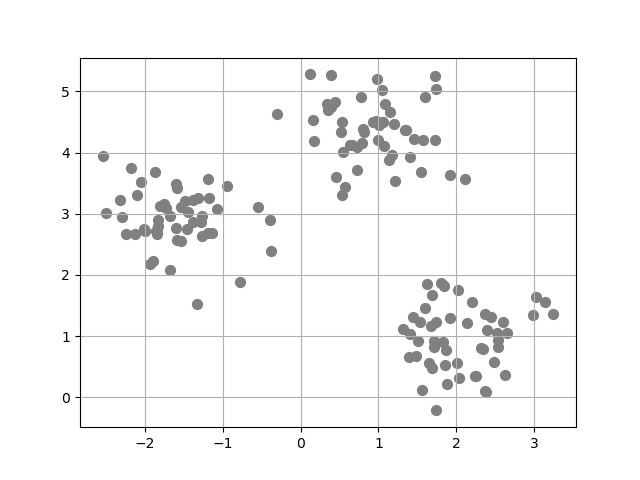
- 3. 데이터 산점도 시각화
plt.scatter(x[:, 0], x[:, 1], s=50, c='gray', marker='o') plt.grid(True) plt.show()
- 4. K-Means 모델
[ 속성 소개 ]
- n_clusters 속성 : 군집 개수 지정
- init 속성 : 초기 중심값 설정 방법 지정
[ 초기 중심값 설정 방법 ]
- random : 랜덤하게 설정 (초기 중심점들이 몰릴 수 있다.)
- k-means++ : 랜덤하게 설정 (초기 중심점끼리 최대한 떨어뜨린다.)model = KMeans(n_clusters=3, init='k-means++', random_state=0) model.fit(x)
- 5. 예측값
y_pred = model.predict(x) print(y_pred[:10]) # [0 2 2 2 0 2 2 0 1 2]
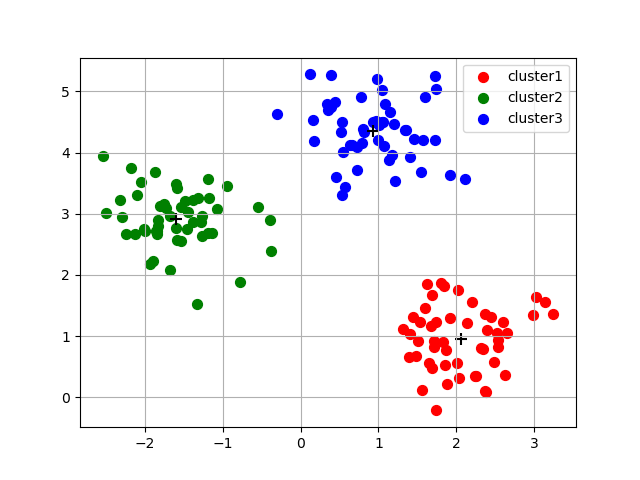
- 6. 각 군집 중심점 확인
centroid = model.cluster_centers_ print('centroid(군집 중심점) 확인 : ', centroid) # centroid(군집 중심점) 확인 : # [[ 2.06521743 0.96137409] # [-1.5947298 2.92236966] # [ 0.9329651 4.35420712]]
- 7. 군집 시각화
plt.scatter(x[y_pred == 0, 0], x[y_pred == 0, 1], s=50, c='r', marker='o', label='cluster1') plt.scatter(x[y_pred == 1, 0], x[y_pred == 1, 1], s=50, c='g', marker='o', label='cluster2') plt.scatter(x[y_pred == 2, 0], x[y_pred == 2, 1], s=50, c='b', marker='o', label='cluster3') plt.scatter(centroid[:, 0], centroid[:, 1], s=70, c='black', marker='+') plt.grid(True) plt.legend() plt.show()
- 8. 엘보우 방법으로 K값 구하기
def elbos(x): sse = [] for i in range(2, 11): model = KMeans(n_clusters=i, init='k-means++', random_state=0) model.fit(x) sse.append(model.inertia_) plt.plot(range(2, 11), sse, marker='o') plt.xlabel('count of cluster') plt.ylabel('SSE') plt.show() elbos(x)

데이터 사이언티스트를 목표로 하는 개발자