서론
MSA에서 DDD 패턴이 필요한 이유
- MSA가 추구하는 방향성에는 밑과 같다.
- Strong Module Boundaries (명확한 모듈 경계)
- DDD(Domain Driven Design) 패턴에 바운디드 컨텍스트(Bounded Context)을 이용하여 서비스간 결합도를 낮출수 있다.
- Independent Deployment (독립적 배포)
- DDD(Domain Driven Design) 패턴에서 Domain별로 나누기에 독립적인 서비스 배포가 가능하다.
- Technology Diversity (기술 다양성)
- 위 방향성도 위에 1, 2번에서 말한 장점으로 얘기할 수 있다.
- 예를들어 service 단위로 다른 프레임 워크, 다른 언어를 사용해서 개발이 가능하다.
- Strong Module Boundaries (명확한 모듈 경계)
본론
DDD 패턴 정의
- DDD의 주요 설계 원칙
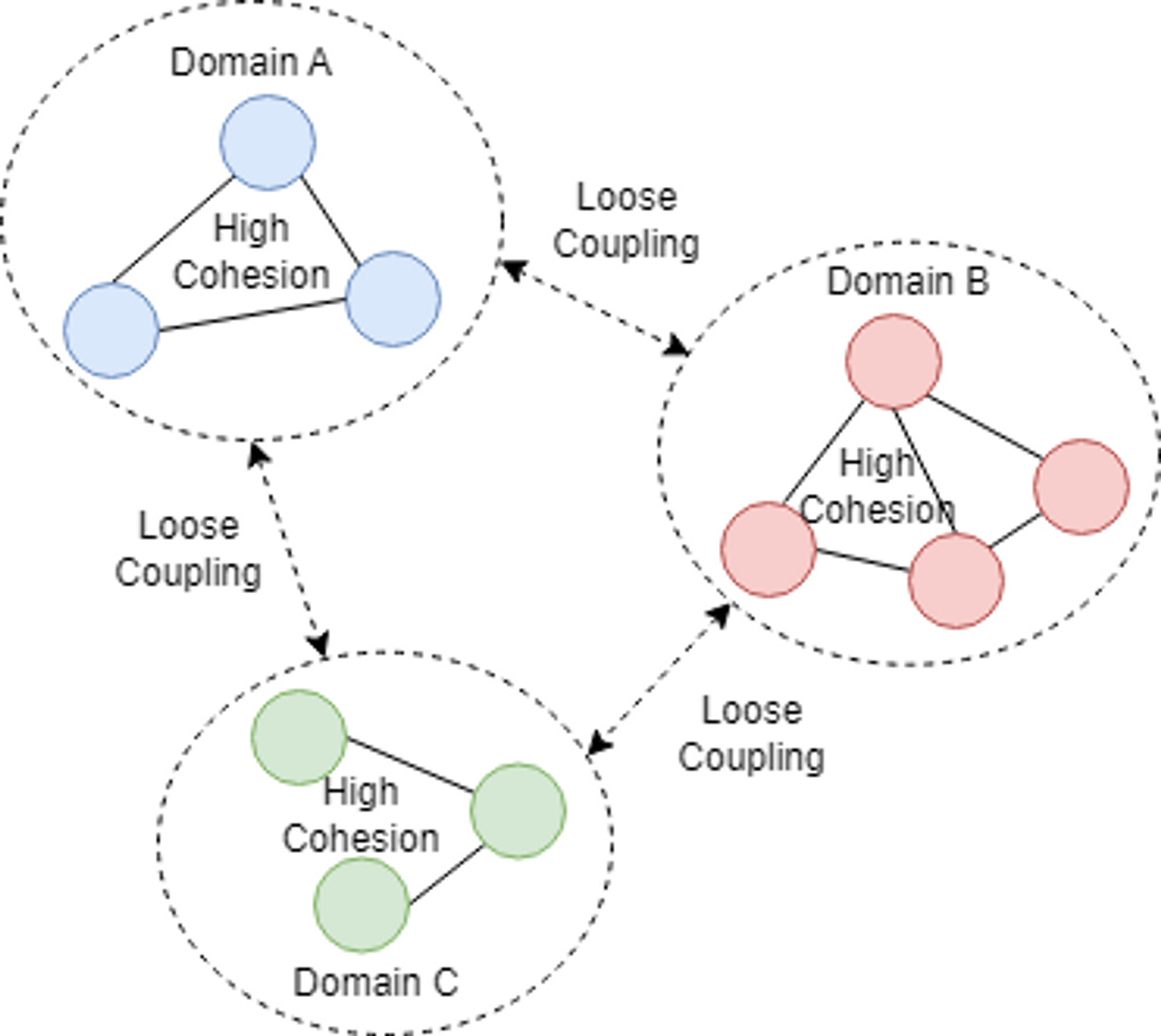
- 도메인들 간에는 Loose Coupling하고 도메인 내에서는 High Cohesion 해야 한다.
- 도메인 모델링
- 개발팀과 기획팀 등등 사이의 통신이 되는 언어를 구성한다.
- 중요한 비즈니스 로직을 캡슐화한다.
- 바운디드 컨텍스트(Bounded Context)
- 도메인 모델이 적용되는 특정 영역을 의미한다.
- 하나의 큰 시스템 내에서 여러개의 컨텍스트가 존재할 수 있다.
- 각 컨텍스트는 자신만의 도메인 모델과 우선적인 언어를 가진다.
도메인 나누기
- 사실 도메인을 나누기 전에 이벤트 스토밍이라던지 명렁처리, 어그리게이션 등을 확실하게 이해하고 가는게 좋다
- 명령처리, 어그리게시션과 같은 부분은 학습 곡선이 크지 않지만, 이벤트 스토밍은 큰 공수가 들어가므로 필자는 이벤트 스토밍은 넘어간 채 개발하였다.
- 따라서 이벤트 스토밍을 안 했는데 어떻게 도메인을 나눴는가에 답을 주자면, 일단 큰 분류로 나누고 그 후에 디테일하게 세부적으로 나눴다.
- User-Service → 회원을 관리하는 서비스이다.
- Mate-Service → 운동 매칭 서비스이다. (Mate, MatePost 두개의 서비스가 합쳐져있다.)
- Order-Service → 주문을 관리하는 서비스이다.
- Product-Service → 상품을 관리하는 서비스이다.
- Stcok-Service → 재고를 관리하는 서비스이다.
- Delivery-Service → 배달을 관리하는 서비스이다.
- 위 6가지의 서비스를 보면 크지도 작지도 않은 서비스들을 갖고있다.
- 위 서비스중 원래는 order-service와 stock-service는 같이 존재하였는데, 서비스가 커질것을 우려해 세부적으로 분리를 해주었다.
- 각 서비스는 DDD와 Clean Arch를 따르도록 설정하였다.
연관관계 매핑
- MSA에서는 각 서비스별로 DB와 Table이 다르기에 연관관계 매핑을 해주는데 어려움이 있다.
- 아, 물론 여러서비스를 나눠도 하나의 DB를 사용할 수 있긴하다.
- 하지만 그렇게 된다면 MSA가 지향하는 방식과는 다른 방향이 아닐까 싶다. → 필자는 이렇게 말했지만 회사 사정상 어쩔수 없는 부분도 분명 존재할 것이다. 모든 서비스엔 정답이 없기에 잘 맞춰나가면 될 것 이라고 생각한다.
- 여러 서비스가 각 고유의 DB를 가지게 된다면 그럼 어떻게 해줘야하나?
- 그것에 대한 저의 대답은 저희가 테이블을 직접적으로 조인하는 방식인 직접 매핑이 아닌 간접 매핑을 이용해서 해결하였다.
직접 매핑 → DB를 1개만 사용하는경우
@Table(name = "user")
public class UserJpaEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
}- 유저 테이블이다.
@Table(name = "mate_post")
public class MatePostJpaEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private long id;
@ManyToOne(
targetEntity = User.class,
fetch = FetchType.LAZY
) // 실제로 요청하는 순간 가져오기 위해 LAZY로 사용함.
@JoinColumn(name = "id")
private User user;
}- 운동 매칭 게시글 테이블이다.
- 직접 매핑은 유저 테이블 전체를 조인하는 방식으로 유저에 키값으로 매칭을 해준다.
- 이렇게 매칭 했을 때 post 테이블을 조회시 user 테이블에 대한 정보를 계속 가지고 다니므로 user에 대한 데이터 변환(데이터 무결성 관리), 성능 이유 등이 대한 문제가 발생한다.
간접 매핑 → DB를 여러개 사용할 때
@Table(name = "user")
public class UserJpaEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
}- 유저 테이블이다.
- 여기까진 직접 매핑과 같다.
@Table(name = "mate_post")
public class MatePostJpaEntity {
@Id
@GeneratedValue(strategy = IDENTITY)
private Long id;
@Column(name = "user_id")
private Long userId;
}- 운동 매칭 게시글 테이블이다.
- 여기서도 마찬가지로 어떤 유저가 게시글을 작성했는지 알기 위해 userId 받아주었다.
- 이렇게 받아주면 userId 값 하나만 계속 가져오므로 나머지 데이터에 대한 무결성을 지킬수 있고, 전체 값을 다 가져오는 것이 아니라 성능적인 측면에서도 좋은 장점이 있다.
결론
후기
- 이로서 간단하게 DDD에 대한 경험을 녹여서 블로그를 작성했다.
- 아직 DDD 패턴에 대해서는 배워야할 부분이 너무 많은 것 같다.
- DDD 패턴을 조금 더 잘 쓰게 된다면 Event Driven Architecture, Event Soucring 두개도 공부해 볼 예정이다.

지나가는 개발자