한국소프트웨어저작권협회 생성형 AI 기반 웹 서비스 개발자 양성 과정 대망의 1일차
간단한 OT 이후 강사님의 이력에 대한 이야기가 대다수였다.
어마어마한 이력과 그를 뒷받침해주는 지식 덕분에 신뢰도가 올라갔다.
VS Code, Git, Anaconda, Node.js를 설치하며 개발환경 셋업을 하는 동안 부트캠프에 임하는 마음가짐에 대해서도 생각해보게 됐다.
힘든 과정이고 만약 완주할 자신이 없으면 금요일까지 매니저님께 말씀드려 나가길 권해주셨다. 무서워...
첫날부터 용어의 정의를 잘 알고있는지 강조해 앞으로 정리해나갈 계획이다.
http와 https의 차이
HTTP(Hypertext Transfer Protocol)
클라이언트와 서버 간 통신을 위한 규칙 세트 또는 프로토콜
HTTPS(Hypertext Transfer Protocol Secure)
HTTP의 더 안전한 버전
HTTPS에서는 브라우저와 서버가 데이터를 전송하기 전에 안전하고 암호화된 연결을 설정한다.
HTTP의 응답값
100 Continue: 클라이언트가 서버로 보낸 요청에 문제가 없으니 다음 요청을 이어서 보내도 된다
101 Switching Protocols: 서버가 전환되는 프로토콜을 가리킨다
200 OK: 요청이 성공했음을 나타내는 성공 응답 상태 코드
성공의 의미는 다음과 같이 HTTP 요청 메서드에 따라 나뉜다.
GET: 리소스를 가져왔고 메시지 본문으로 전송되었다
HEAD: 메시지 본문 없이 표현 헤더가 응답에 포함되어 있다
POST: 리소스가 명시하는 행동의 결과가 메시지 본문에 전송되었다
TRACE: 서버가 요청받은 메시지가 메시지 본문에 포함되어 있다
PUT 또는 DELETE의 성공 결과는 종종 200 OK가 아니라 204 No Content(리소스를 새로 생성한 경우 201 Created)
201 Created: 요청이 성공적으로 처리되었으며, 자원이 생성되었음을 나타내는 성공 상태 응답 코드
응답이 반환되기 이전에 새로운 리소스가 생성되며, 응답 메시지 본문에 새로 만들어진 리소스 혹은 리소스에 대한 설명과 링크를 메시지 본문에 넣어 반환한다. 그 위치는 요청 URL 또는 Location 헤더 값의 URL 이다.
300 Multiple Choices: 리디렉션 상태 응답 코드는 요청에 가능한 응답이 두 개 이상 있음을 의미
응답 중 하나를 선택하는 표준화된 방법이 없기 때문에 이 응답 코드는 거의 사용되지 않는다.
400 Bad Request: 서버가 클라이언트 오류(예: 잘못된 요청 구문, 유효하지 않은 요청 메시지 프레이밍, 또는 변조된 요청 라우팅) 를 감지해 요청을 처리할 수 없거나, 하지 않는다는 것을 의미
500 Internal Server Error: 요청을 처리하는 과정에서 서버가 예상하지 못한 상황에 놓였다는 것
HTTPS 프로토콜의 작동 프로세스
HTTPS는 HTTP 요청 및 응답을 SSL(Secure Sockets Layer) 및 TLS(Transport Layer Security) 기술에 결합한다.
HTTPS 웹 사이트는 독립된 인증 기관(CA)에서 SSL/TLS 인증서를 획득해야 한다. 이러한 웹 사이트는 신뢰를 구축하기 위해 데이터를 교환하기 전에 브라우저와 인증서를 공유한다. SSL 인증서는 암호화 정보도 포함하므로 서버와 웹 브라우저는 암호화된 데이터를 교환할 수 있다.
프로세스는 다음과 같다
1. 사용자 브라우저 주소 표시줄에 https:// URL 형식을 입력하여 HTTPS 웹 사이트를 방문한다.
2. 브라우저는 서버의 SSL 인증서를 요청하여 사이트의 신뢰성을 검증하려고 시도한다.
3. 서버는 퍼블릭 키가 포함된 SSL 인증서를 회신으로 전송한다.
4. 웹 사이트의 SSL 인증서는 서버 아이덴티티를 증명한다. 브라우저에서 인증되면, 브라우저가 퍼블릭 키를 사용하여 비밀 세션 키가 포함된 메시지를 암호화하고 전송한다.
5. 웹 서버는 개인 키를 사용하여 메시지를 해독하고 세션 키를 검색한다. 그런 다음, 세션 키를 암호화하고 브라우저에 승인 메시지를 전송한다.
6. 이제 브라우저와 웹 서버 모두 동일한 세션 키를 사용하여 메시지를 안전하게 교환하도록 전환한다.
빅 엔디안과 리틀 엔디안
컴퓨터는 모든 데이터를 2진수로 표현하고 처리한다.
비트와 바이트
비트(bit): 컴퓨터가 데이터를 처리하기 위해 사용하는 데이터의 최소 단위
바이트(byte): 8비트로 구성되며 한 문자를 표현할 수 있는 최소 단위
바이트 저장 순서(byte order)
컴퓨터는 데이터를 메모리에 저장할 때 바이트(byte) 단위로 나눠서 저장한다.
컴퓨터가 저장하는 데이터는 대부분 32비트(4바이트)나 64비트(8바이트)로 구성된다. 이렇게 연속되는 바이트를 순서대로 저장해야 하는데, 이것을 바이트 저장 순서(byte order)라고 한다. 이때 바이트가 저장되는 순서에 따라 빅 엔디안(big endian)과 리틀 엔디안(little endian)으로 나눌 수 있다.
빅 엔디안(big endian)
낮은 주소에 데이터의 높은 바이트(MSB, Most Significant Bit)부터 저장하는 방식이다.
예를 들어 다음과 같이 저장할 32비트 크기의 정수가 있다고 가정합니다.
예제
0x12345678이 정수는 각각 다음과 같이 1바이트값 4개로 구성됩니다.
예제
0x12, 0x34, 0x56, 0x78이 4개의 1바이트 값을 빅 엔디안 방식으로 저장하면 다음 그림과 같이 저장됩니다.
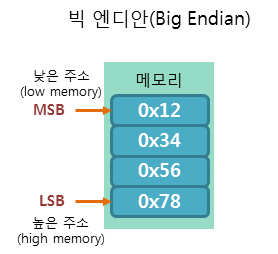
여기서 낮은 주소와 높은 주소란?
높은 바이트: 정수 값에서 가장 왼쪽에 위치한 바이트
위 예제에서는 0x12가 가장 왼쪽에 있으므로 높은바이트다
낮은 바이트: 정수 값에서 가장 오른쪽에 위치한 바이트
참고: 0x는 16진수 표기법의 접두사로, 숫자가 16진수임을 나타낸다.
리틀 엔디안(Little Endian)
리틀 엔디안 방식은 낮은 주소에 데이터의 낮은 바이트(LSB, Least Significant Bit)부터 저장하는 방식이다.
이 방식은 평소 우리가 숫자를 사용하는 선형 방식과는 반대로 거꾸로 읽어야 한다.
대부분의 인텔 CPU 계열에서는 이 방식으로 데이터를 저장한다.
앞서 예를 든 정수 "0x12345678"를 리틀 엔디안 방식으로 저장하면 다음 그림과 같이 저장된다.
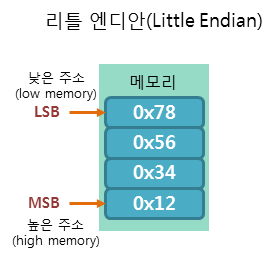
빅 엔디안 vs 리틀 엔디안
빅 엔디안과 리틀 엔디안은 단지 저장해야 할 큰 데이터를 어떻게 나누어 저장하는가에 따른 차이일 뿐, 어느 방식이 더 우수하다고는 단정할 수 없다.
물리적으로 데이터를 조작하거나 산술 연산을 수행할 때에는 리틀 엔디안 방식이 더 효율적이다.
하지만 데이터의 각 바이트를 배열처럼 취급할 때에는 빅 엔디안 방식이 더 적합하다.
현재 대부분의 시스템은 인텔 기반의 윈도우이므로 리틀 엔디안 방식을 사용하고 있을 것이다.
하지만 네트워크를 통해 데이터를 전송할 때에는 빅 엔디안 방식이 사용된다.
따라서 인텔 기반의 시스템에서 소켓 통신을 할 때는 바이트 순서에 신경을 써서 데이터를 전달해야 한다.
이 외에 개발자가 가져야할 태도
- Why에 대한 고민하기
- 원리와 개념에 대해 계속 관심 갖기.
- 좋은 습관을 들일 것(원문 찾아보기, 변수명 직관적으로 짓기 등)
참고 사이트
https://aws.amazon.com/ko/compare/the-difference-between-https-and-http/
https://developer.mozilla.org/ko/docs/Web/HTTP
https://developer.mozilla.org/ko/docs/Web/HTTP/Reference/Status
https://www.tcpschool.com/c/c_refer_endian
