
8.1 해시 테이블
해시 테이블(Hash Table)이란?
키-값(key-value) 쌍을 통해 데이터를 저장하는 자료구조 중 하나
빠르게 데이터를 검색할 수 있는 장점을 가진다.
룩업(look-up)이란?
특정 원소가 있는지 확인하거나 또는 특정 키에 해당하는 값을 찾는 작업을 의미한다.
대부분의 프로그래밍 언어는 해시 테이블 자료구조를 포함하며, 해시 테이블에는 '빠른 읽기'가 가능하다.
해시 테이블은 프로그래밍 언어별로 다르게 불리는데 해시, 맵, 해시 맵, 딕셔너리, 연관 배열 등의 이름을 갖는다.
menu = { "french fries" => 0.75, "hamberger" => 2.5, "hot dog" => 1.5, "soda" => 0.6 }해시 테이블은 쌍으로 이뤄진 값들의 리스트로, 첫 번째 항목을 키(key), 두 번째 항목을 값(value)라고 부른다.
즉, 위 루비 코드에서 "french fries"가 키(key), 0.75가 값(value)이다.
menu["french fries"]
# 0.75그리고 위와 같은 문법으로 키의 값을 룩업할 수 있고 결과로는 0.75 라는 값(value)를 반환한다.
룩업은 딱 한 단계만 걸리므로 평균적으로 효율성이 이다.
8.2 해시 함수로 해싱
비밀 코드 해독
A = 1
B = 2
C = 3
D = 4
E = 5
.
.
.🤖 : AEB?
👾 : 152
🤖 : BDB?
👾 : 242
이렇게 문자를 가져와 숫자로 변환하는 과정을 해싱(hasing)이라고 한다.
또한 글자를 특정 숫자로 변환하는 데 사용한 코드를 해시 함수(hash function)이라고 한다.
이 밖에도 각 문자에 해당하는 숫자를 가져와 모든 수를 합쳐 반환하거나, 곱해서 반환하는 것도 해시 함수다.
해시 함수가 유효하려면 딱 한가지 기준을 충족해야 한다.
바로 동일한 문자열을 적용할 때마다 동일한 숫자로 변환해야 한다는 것이다.
주어진 문자에 대해 반환하는 결과가 일관되지 않으면 해당 해시 함수는 유효하지 않다.
8.3 유의어 사전 만들기
(예시 참고사항)
곱셈 해시를 사용한 예시로, 0번째 인덱스가 존재하지 않아 패스
| ᅠ | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 |
theSaurus = {}
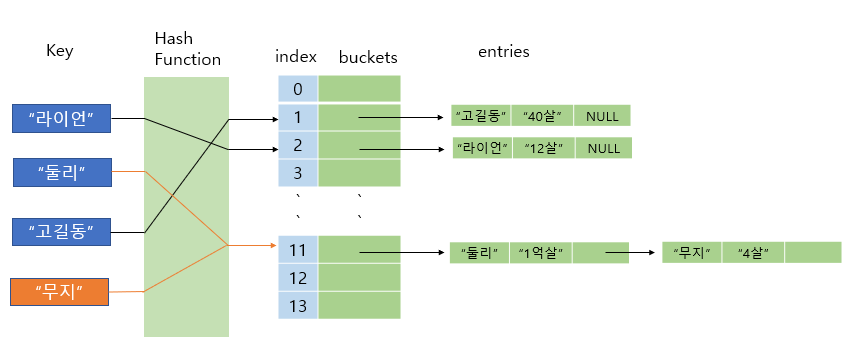
theSaurus["bad"] = "evil"{ "bad" => "evil" }🥸 위처럼 해시 테이블을 만들어 항목을 추가한다고 했을 때, 컴퓨터는 데이터를 어떻게 저장할까?
컴퓨터는 키(key)에 해시 함수를 적용한다. (예시로는 곱셈 해시 함수 사용)
BAD = 2 * 1 * 4 = 8키 "bad"는 8로 해싱되므로 컴퓨터는 값 "evil"을 다음과 같이 셀 8에 넣는다.
| ᅠ | "evil" | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 |
theSaurus["cab"] = "taxi"cab = 3 * 1 * 2 = 6키 "cab"는 6로 해싱되므로 컴퓨터는 값 "taxi"을 다음과 같이 셀 6에 넣는다.
| ᅠ | "taxi" | "evil" | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 |
theSaurus["ace"] = "star"ace = 1 * 3 * 5 = 15키 "ace"는 15로 해싱되므로 컴퓨터는 값 "star"을 다음과 같이 셀 15에 넣는다.
| ᅠ | "taxi" | "evil" | "star" | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 |
즉, 모든 키와 값마다 먼저 키를 해싱한 후 각 값을 키의 인덱스에 저장한다.
그리고 현재 해시 테이블은 아래와 같다.
{ "bad" => "evil", "cab" => "taxi", "ace" => "star" }8.4 해시 테이블 룩업
해시 테이블에서 항목을 룩업(look-up)할 때, 키를 사용해 연관된 값을 찾는다.
theSaurus["bad"]위처럼 "bad"의 값을 찾기 위해 컴퓨터는 아래 두 단계를 실행한다.
1. 컴퓨터는 룩업하고 있는 키를 해싱한다. ()
2. 해싱 결과가 8이므로 셀 8을 찾아 저장된 값을 반환한다. 위 예제에서는 문자열 "evil" 이다.
전체 상황을 살펴보면,
- 해시 테이블에서 각 값의 위치는 키로 결정된다.
즉, 키 자체를 해싱하여 연관된 값이 놓일 인덱스를 계산한다. - 키가 값의 위치를 결정하므로, 어떤 키가 있을 때 값을 찾고 싶다면 키 자체로 값의 위치를 알 수 있다.
값을 넣기 위해 키를 해싱했던 것처럼, 키를 해싱하여 값을 넣었던 곳을 찾을 수 있기 때문이다.
위와 같은 이유로 해시 테이블의 룩업 효율이 인지 명확히 알 수 있다.
컴퓨터는 키를 해싱하여 숫자로 바꾼 후 그 수의 인덱스로 가서 저장된 값을 반환한다.
🧐 만약 배열에서 메뉴 항목의 값을 룩업하려면?
배열에서는 항목을 찾을 때까지 각 셀을 순회하며 검색해야 한다.
정렬되지 않은 배열에서는 최대 , 정렬된 배열에서는 최대 단계가 소요된다.
하지만 해시 테이블을 사용할 경우 실제 메뉴 항목을 키로 사용하여 단계만에 룩업할 수 있다.
이것이 바로 해시 테이블의 매력이며, 왜 배열보다 빠른지를 이해할 수 있다.
단방향(one-directional) 룩업
해시 테이블에서 한 단계만에 값을 찾는 것은 그 값의 키를 알고있을 때만 가능하다.
키를 모른 채 값을 찾기 위해서는 해시 테이블 내 모든 키와 값의 쌍을 검색하는 수밖에 없고, 이 과정은 이다.
다시 말해 "키"를 이용해 "값"을 찾을 때에만 효율의 룩업이 가능하다는 것이다.
거꾸로 "값"을 이용해 "키"를 찾을 때에는 해시 테이블의 빠른 룩업 기능을 활용할 수 없다.
😢 왜죠?
키가 값의 위치를 결정한다는 해시 테이블의 대전제 때문이다. 하지만 이 전제는 한 방향으로만 동작한다.
다시 말해서, 키를 사용해 값을 찾는 식으로만 동작한다는 것이다.
값으로 키를 알아내는 것에는 동작하지 않으니 전부 순회하는 것 외에는 방법이 없다.
🤓 그럼 키는 어디에 저장되나요?
8.3 예제에서는 값이 해시 테이블에 어떻게 저장되는지를 알 수 있었다.
언어에 따라 다르지만 어떤 언어는 키를 값 바로 옆에 저장하기도 한다.
그러나 이렇게 저장할 경우 충돌이 일어날 수 있다.
어느 경우든 해시 테이블의 단방향 속성이 갖는 또 다른 측면도 주목할 가치가 있다.
각 키는 해시 테이블에 오직 하나만 존재할 수 있으나 값은 여러 인스턴스가 존재할 수 있다.
menu = { "french fries" => 0.75, "hamberger" => 2.5, "hot dog" => 1.5, "soda" => 0.6 }위 코드에서 살펴보면,
"hamberger" 키는 두 번 사용할 수 없지만 2.5 라는 값을 가진 메뉴는 여러 개 존재할 수 있다는 의미이다.
대부분의 언어는 이미 존재하는 키에 키-값 쌍을 저장하려 한다면, 키는 그대로 두고 기존 값만 덮어쓴다.
8.5 충돌 해결
| ᅠ | "taxi" | "evil" | "star" | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 |
{ "bad" => "evil", "cab" => "taxi", "ace" => "star" }8.3 예제에서 만들었던 유의어 사전을 살펴보면 위와 같다.
여기에 아래와 같이 새로운 항목을 추가하면,
theSaurus["dab"] = "pat"DAB = 4 * 1 * 2 = 8해싱 함수의 결과를 적용하여 셀 8에 "pat"을 추가하려 한다. 그러나 이미 "evil"이 들어있다.
이처럼, 이미 채워진 셀에 데이터를 추가하는 것을 충돌(collision)이라고 한다.
충돌을 해결할 수 있는 고전적인 방법 중 하나는 분리 연결법(Separate Chaining)이다.
분리 연결법(Separate Chaining)이란?
동일한 셀에 저장되어야하는 데이터에 체인을 걸어 찾는 데이터가 나올 때까지 계속 체인을 따라가는 방식
다른 자료구조를 버킷에 연결해서 다음 데이터를 저장하며 주로 연결 리스트나 트리를 사용한다.
| "taxi" | "evil" | |||
|---|---|---|---|---|
| 5 | 6 | 7 | 8 | 9 |
👇
| | "bad":"evil" | "dab":"pat" | |
|---|
| 8 |
🤔 이렇게 바꿨을 때 해시 테이블 룩업이 어떻게 동작하나요?
theSaurus["dab"]위와 같이 "dab" 키를 룩업할 때 컴퓨터는 아래 세 단계를 수행한다.
- 컴퓨터는 키를 해싱한다. ()
- 셀 8을 룩업한다. 이 때 컴퓨터는 셀 8이 하나의 값이 아닌 배열들의 배열을 포함하고 있음을 알게된다.
- 각 하위 배열의 인덱스 0을 찾아보며 룩업하고 있는 단어
"dab"을 찾을 때까지 배열을 검색한다.
일치하는 하위 배열의 인덱스 1에 있는 값을 반환한다.
이 단계를 그림으로 표현하면 아래와 같다.
컴퓨터가 확인 중인 셀이 배열을 참조할 경우 다수의 값이 들어있는 배열을 선형 검색(Linear Search)해야 하므로 검색 단계가 더 소요된다. 만약 모든 데이터가 해시 테이블의 한 셀 안에 들어있다면, 해당 해시 테이블은 배열보다 나을 것이 없다. 따라서 최악의 경우 해시 테이블 룩업의 성능은 사실상 이다.
그렇기 때문에 해시 테이블에 충돌이 거의 없도록 구현해야 한다.
다행히 대부분의 프로그래밍 언어는 해시 테이블을 구현하고 대신 처리해준다.
그러나 우리는 해시 테이블의 내부 동작 방식을 이해하며 어떻게 성능을 유지하는지 이해할 수 있다.
8.6 효율적인 해시 테이블 만들기
해시 테이블은 아래 세 가지 요인에 따라 효율성이 정해진다.
- 얼마나 많은 데이터를 저장하는가?
- 얼마나 많은 셀을 쓸 수 있는가?
- 어떤 해시 함수를 사용하는가?
🤨 해시 함수가 영향을 주는 이유가 뭐죠?
만약 1부터 9 사이의 값만 반환하는 해시 함수가 있다고 가정했을 때,
아래와 같은 해시 테이블에서는 10부터 16까지의 셀은 존재하지만 컴퓨터는 이 셀을 사용하지 않는다.
| ᅠ | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 |
즉 다시 말해 좋은 해시 함수란, 사용 가능한 모든 셀에 데이터를 잘 분산시킬 수 있는 함수이다.
데이터를 넓게 퍼뜨릴 수록 충돌이 적어진다.
훌륭한 충돌 조정
충돌 횟수가 낮을수록 해시 테이블의 효율성이 높아진다.
이론상으로 충돌을 피하는 최선의 방법은 해시 테이블에 많은 셀을 두는 것이다.
5개의 항목을 저장하고 싶은 해시 테이블에 1000개의 셀을 둔다면 충돌 가능성이 거의 없을 것이다.
하지만 충돌을 피하는 것 외에도 메모리를 많이 사용하지 않도록 균형을 맞춰야 한다.
좋은 해시 테이블이란
- 많은 메모리를 낭비하지 않으며
- 균형을 유지하고
- 충돌을 피한다
충돌 조정을 위해 컴퓨터 과학자는 경험에 기반하여 다음과 같은 규칙을 세웠다.
- 해시 테이블에 저장된 데이터가 7개라면, 셀은 10개여야 한다.
데이터와 셀 간의 이러한 비율을 부하율(load factor)이라고 부른다.
8.7 해시 테이블로 데이터 조직
해시 테이블은 데이터를 쌍으로 저장하므로 데이터를 조직하는 많은 시나리오에 유용하다.
앞선 예제와 같이 패스트푸드 메뉴나 유의어 사전 시나리오가 그렇다.
실제로 파이썬은 해시 테이블을 딕셔너리(dictionary)라 부른다.
사전이야말로 단어와 정의가 각각 쌍으로나열된 데이터 형태이기 때문이다.
해시 테이블은 쌍으로 된 데이터와 자연스럽게 들어맞기 때문에 어떤 경우에는 해시 테이블로 조건부 로직을 간소화 할 수도 있다.
function statusCodeMeaning(number) {
if (number === 200) {
return "OK"
} else if (number === 301) {
return "Moved Permanently";
} else if (number === 401) {
return "Unauthorized";
} else if (number === 404) {
return "Not Found";
} else if (number === 500) {
return "Internal Server Error";
}
}위 코드는 조건부 로직에서 쌍으로 된 데이터, 즉 상태 코드 번호와 각각의 의미를 처리하는 로직이다.
이 조건부 로직을 해시 테이블로 간소화 해보자. (객체 활용)
const STATUS_CODES = {
200: "OK",
301: "Moved Permanently",
401: "Unauthorized",
404: "Not Found",
500: "Internal Server Error"
}
function statusCodeMeaning(number) {
return STATUS_CODES[number];
}8.8 해시 테이블로 속도 올리기
해시 테이블은 쌍으로 된 데이터와 완벽하게 들어맞지만, 쌍이 아닌 데이터라도 코드를 빠르게 만들 때 쓰일 수 있다.
const array = [61, 30, 91, 11, 54, 38, 72];위 배열에서 어떤 값을 찾기 위해서는,
먼저 정렬되지 않은 배열이므로 단계의 선형 검색을 수행해야 한다.
🤓 하지만 어떤 코드를 실행하여 위 배열을 해시 테이블로 바꾼다면?
const HASH_TABLE = {
64: true,
30: true,
91: true,
11: true,
54: true,
38: true,
72: true
}HASH_TABLE[38];
// true각 수를 키로 저장하여 값에 true를 할당 후, 키를 사용해 검색하면 1단계만에 룩업 할 수 있다.
true를 반환하면 해시 테이블에 있다는 것이고, 그렇지 않으면 없다는 것이다.
이처럼 배열을 해시 테이블로 변환하면 검색이 검색으로 바뀌게 된다.
그리고 이 예시에는 쌍으로 된 데이터가 아닌 수 리스트를 처리한다.
이처럼 해시 테이블의 키를 사용해 한 단계로 룩업하여 사용하는 것을 (이 책에서는) "해시 테이블을 인덱스로 사용하기" 라고 부른다.
배열 부분 집합
const arr1 = ["a", "b", "c", "d", "e", "f"];
const arr2 = ["b", "d", "f"];
const arr3 = ["b", "d", "f", "h"];한 배열이 다른 배열의 부분 집합인지 알아내야 할 때,
위 코드에서 arr2 배열의 모든 값이 arr1 배열에 있으므로 arr2는 arr1의 부분 집합이다.
하지만 arr3 배열에서는 값 "h"가 arr1에 없으므로 arr3은 arr1의 부분 집합이 아니다.
🤨 이렇듯 두 배열을 비교하여 한 쪽이 다른 한 쪽의 부분 집합인지 알려주는 함수를 어떻게 작성할까?
기본 코드 (중첩 루프 사용)
function isSubset1(array1, array2) {
let largerArray;
let smallerArray;
if (array1.length > array2.length) {
largerArray = array1;
smallerArray = array2;
} else {
largerArray = array2;
smallerArray = array1;
}
for (let i = 0; i < smallerArray.length; i++) {
let foundMatch = false;
for (let j = 0; j < largerArray.length; j++) {
if (smallerArray[i] === largerArray[j]) {
foundMatch = true;
break;
}
}
if (foundMatch === false) return false;
}
return true;
}해설
function isSubset1(array1, array2) {
let largerArray;
let smallerArray;
// 매개변수로 받은 두 배열 중 어느 배열이 더 작은지 크기를 비교하여
// 각각 largerArray, smallerArray에 할당한다.
if (array1.length > array2.length) {
largerArray = array1;
smallerArray = array2;
} else {
largerArray = array2;
smallerArray = array1;
}
// 작은 배열을 순회
for (let i = 0; i < smallerArray.length; i++) {
// 작은 배열의 현재 값이 큰 배열에 없다고 가정하고 시작한다.
let foundMatch = false;
// 작은 배열의 각 값에 대해 큰 배열을 순회
for (let j = 0; j < largerArray.length; j++) {
// 만약 두 값이 같으면 작은 배열의 현재 값이 큰 배열에 있음을 의미
if (smallerArray[i] === largerArray[j]) {
foundMatch = true;
break;
}
}
// 작은 배열의 현재 값이 큰 배열에 없으면 false 반환
if (foundMatch === false) return false;
}
// 루프를 모두 순회하면 작은 배열의 모든 값이 큰 배열에 있으므로 true 반환
return true;
}위 isSubset1 함수의 알고리즘의 효율성을 분석하면 첫 번째 배열의 항목 수에 두 번째 배열의 항목 수를 곱한 만큼 실행되므로 이다.
🤓 해시 테이블을 활용해 효율성을 개선해보자!
기본 코드
function isSubset2(array1, array2) {
let largerArray;
let smallerArray;
let hash = {};
if (array1.length > array2.length) {
largerArray = array1;
smallerArray = array2;
} else {
largerArray = array2;
smallerArray = array1;
}
for (const value of largerArray) {
hash[value] = true;
}
for (const value of smallerArray) {
if (!hash[value]) return false;
}
return true;
}해설
function isSubset2(array1, array2) {
let largerArray;
let smallerArray;
let hash = {};
// 매개변수로 받은 두 배열 중 어느 배열이 더 작은지 크기를 비교하여
// 각각 largerArray, smallerArray에 할당한다.
if (array1.length > array2.length) {
largerArray = array1;
smallerArray = array2;
} else {
largerArray = array2;
smallerArray = array1;
}
// largerArray의 모든 항목을 순회하며 hash에 저장한다.
for (const value of largerArray) {
hash[value] = true;
}
// smallerArray의 모든 항목을 순회하며
// hash에 없을 경우 false 반환
for (const value of smallerArray) {
if (!hash[value]) return false;
}
// false를 반환하지 않았다면
// smallerArray의 모든 항목이 largerArray에 있다는 뜻이므로 true 반환
return true;
}해시 테이블을 통해 개선한 isSubset2 함수 수행에 필요한 단계는 이다.
- 큰 배열의 각 항목을 순회하며 해시 테이블을 만든다.
- 작은 배열의 각 항목을 순회하며 해시 테이블을 룩업한다.
두 배열을 합친 총 항목 수를 이라고 할 때, 각 항목을 한 번씩 순회했으므로 이라는 결과가 나온다. 의 효율성을 가졌던 isSubset1 함수에 비하여 엄청난 개선을 이루었다.
해시 테이블을 "인덱스(index)"로 사용하는 이 기법은 배열을 여러 번 검색해야 하는 알고리즘에 자주 쓰인다.
실습
- 두 배열의 교집합을 반환하는 함수를 작성하라. (단, 함수의 복잡도는 이어야 한다.)
function getIntersection(array1, array2) {
let intersection = [];
let hash = {};
for (const value of array1) {
hash[value] = true;
}
for (const value of array2) {
if (hash[value]) intersection.push(value);
}
return intersection;
}const arr1 = [1, 2, 3, 4, 5];
const arr2 = [0, 2, 4, 6, 8];
getIntersection(arr1, arr2); // [2, 4]- 문자열 배열을 받아 첫 번째 중복되는 값을 찾아 반환하는 함수를 작성하라. 배열에 반드시 하나 이상의 중복 쌍이 있다고 가정해도 된다. (단, 함수의 효율성은 이어야 한다.)
function getFirstDuplicateValue(array) {
let hash = {};
for (let i = 0; i < array.length; i++) {
if (hash[array[i]]) {
return array[i];
} else {
hash[array[i]] = array[i]
}
}
}const arr = ["a", "b", "c", "d", "e", "f", "c"];
getFirstDuplicateValue(arr); // "c"- 알파벳 문자를 한 글자만 제외하고 모두 포함하는 문자열을 받아 빠진 문자 하나를 반환하는 함수를 작성하라. (단, 함수의 시간 복잡도는 이어야 한다.)
function findMissingAlphabet(string) {
let alphabet = 'abcdefghijklmnopqrstuvwxyz';
let hash = {};
for (const char of string) {
if (!hash[char]) {
hash[char] = true;
}
}
for (const char of alphabet) {
if (!hash[char]) return char;
}
}const str = "the quick brown box jumps over a lazy dog";
findMissingAlphabet(str); // 'f'- 문자열에서 첫 번째 중복되지 않는 문자를 반환하는 함수를 작성하라. (단, 함수의 효율성은 이어야 한다.)
function getFirstNoDuplicateChar(string) {
let hash = {};
for (const char of string) {
if (hash[char]) {
hash[char] += 1;
} else {
hash[char] = 1;
}
}
for (const char of string) {
if (hash[char] === 1) return char;
}
}getFirstNoDuplicateChar("minimum"); // 'n'요약
- 해시 테이블이란 키-값(key-value) 쌍을 통해 데이터를 저장하는 자료구조 중 하나로 빠르게 데이터를 검색할 수 있는 자료구조다.
- 컴퓨터는 키를 해싱하여 숫자로 바꾼 후 그 수의 인덱스로 가서 저장된 값을 반환한다. 이 과정을 룩업(loo-up)이라고 칭하며, 룩업의 효율성은 이다.
- 해시 테이블의 키를 사용해 한 단계로 룩업하여 사용하는 것을 (이 책에서는) "해시 테이블을 인덱스로 사용하기" 라고 부른다.
- 해시 테이블에서 이미 채워진 셀에 데이터를 추가하는 것을 충돌(collision)이라고 한다.
- 해시 테이블의 충돌을 해결할 수 있는 고전적인 방법 중 하나는 분리 연결법(Separate Chaining)이 있다.
- 즉, 해시 테이블은 효율적인 소프트웨어 개발에 필수적이며, 해시 테이블의 장점인 읽기와 삽입은 다른 자료구조가 쉽게 따라잡을 수 없다.
