
들어가기 전에
혹시 읽으시는 분이 계시다면,
이번 챕터는 책에서는 루비, 파이썬, 자바스크립트 코드로 다양하게 나와있지만
저는 프론트엔드를 준비 중이기 때문에 모든 코드를 자바스크립트로 바꾸어 포스팅 했습니다.
코드를 변환하면서 책에 기재된 코드의 뉘앙스와 다른 점이 생길 수도 있고,
제가 바꾼 코드 내에서 오류가 발견될 수도 있으니 참고해 주시고, 발견하신다면 제보해 주세요!
7.1 짝수의 평균
기본 코드
function getEvenAvg(array) {
let sum = 0;
let count = 0;
for (let i = 0; i < array.length; i++) {
if (array[i] % 2 === 0) {
sum += array[i];
count += 1;
}
}
return sum / count;
}getEvenAvg([1, 2, 3, 4, 5, 6, 7, 8]); // 5
getEvenAvg([10, 11, 12, 13, 14, 15]); // 12해설
function getEvenAvg(array) {
let sum = 0; // 짝수들의 합을 담을 변수
let count = 0; // 짝수의 갯수를 담을 변수
for (let i = 0; i < array.length; i++) {
if (array[i] % 2 === 0) { // 만약 array[i]가 짝수일 경우,
sum += array[i]; // sum에 해당 수를 더하고
count += 1; // 짝수 개수를 카운트 한다.
}
}
return sum / count; // 짝수의 합을 짝수의 갯수로 나누어 평균을 구한다.
}빅 오는 원소가 개일 때 알고리즘 수행에 얼마나 많은 단계 수가 필요한가를 체크하는 것이므로,
알고리즘의 빅 오를 알기 위해서 가장 먼저 해야 할 일은 원소 이 무엇인가를 알아내는 것이다.
짝수의 평균 예제 알고리즘 getEvenAvg 함수에서는
매개변수로 전달된 숫자 배열을 처리하기 때문에 은 배열의 크기(길이)이다.
getEvenAvg 함수의 핵심은 for 루프를 통해 배열 내 각 수를 순회하는 것인데, 해당 루프는 원소 개를 모두 순회하고 있으니 이 알고리즘에서는 최소 단계가 필요하다. 하지만 for 루프 내부에서 해당 수가 짝수인지를 검사하고, 짝수일 경우 sum과 count 두 단계를 더 실행한다. 즉, 홀수일 때보다 짝수일 때 세 단계가 더 실행된다.
🧐 최악의 시나리오는?
빅 오는 (별다른 말이 없다면 주로) 최악의 시나리오에 초점을 맞춘다.
만약 배열의 모든 수가 짝수라면, for 루프 내부의 3단계인 짝수 계산, sum, count를 매 루프마다 수행하게 된다. 즉, 원소가 개일 때 단계가 소요된다.
🤨 for 루프 바깥의 단계를 함께 생각해보면?
변수를 선언하고 0을 할당하는 2개의 단계와 평균을 구하기 위해 sum / count를 실행하는 단계가 추가된다.
따라서, getEvenAvg 함수의 수행 단계는 총 이다.
그러나 빅 오의 경우 지수가 아닌 수는 제외하므로 getEvenAvg 함수의 시간 복잡도는 으로 표기한다.
7.2 단어 생성기
기본 코드
function wordBuilder(array) {
let collection = [];
for (let i = 0; i < array.length; i++) {
for (let j = 0; j < array.length; j++) {
if (i !== j) collection.push(array[i] + array[j]);
}
}
return collection;
}wordBuilder(['a', 'b', 'c']); // (6) ['ab', 'ac', 'ba', 'bc', 'ca', 'cb']
wordBuilder(['1', '2', '3']); // (6) ['12', '13', '21', '23', '31', '32']해설
function wordBuilder(array) {
let collection = []; // 문자열 조합을 담을 배열
// 중첩 루프를 통해 배열 내 문자열을 순회 (i, j)
for (let i = 0; i < array.length; i++) {
for (let j = 0; j < array.length; j++) {
// i와 j가 같은 문자열을 가리키는 경우를 제외하고
// 두 문자열을 이어 붙여 collection에 추가한다.
if (i !== j) collection.push(array[i] + array[j]);
}
}
return collection; // 문자열 조합 배열을 반환한다.
}wordBuilder 함수에서 은 함수로 전달된 배열 내 항목(문자열)의 수이다.
그리고 중첩 루프를 통해 바깥 for 루프에서 을 순회하고, 내부 for 루프에서도 다시 을 순회하므로 단계와 같다. 대표적인 의 경우이며, 대부분의 중첩 루프 알고리즘이 이다.
😧 만약 세 글자짜리 문자열 조합을 계산하려면?
function threeWordBuilder(array) {
let collection = [];
for (let i = 0; i < array.length; i++) {
for (let j = 0; j < array.length; j++) {
for (let k = 0; k < array.length; k++) {
if (i !== j && j !== k && i !== k) {
collection.push(array[i] + array[j]);
}
}
}
}
return collection;
}threeWordBuilder 함수는 원소가 개일 때 i, j, k 단계에서 각각 을 순회하므로
단계, 즉 단계가 소요되며 빅 오로는 으로 표기한다.
이렇게 중첩 루프가 네 개, 다섯 개로 늘어난다면 해당 알고리즘의 복잡도는 각각 , 가 될 것이다.
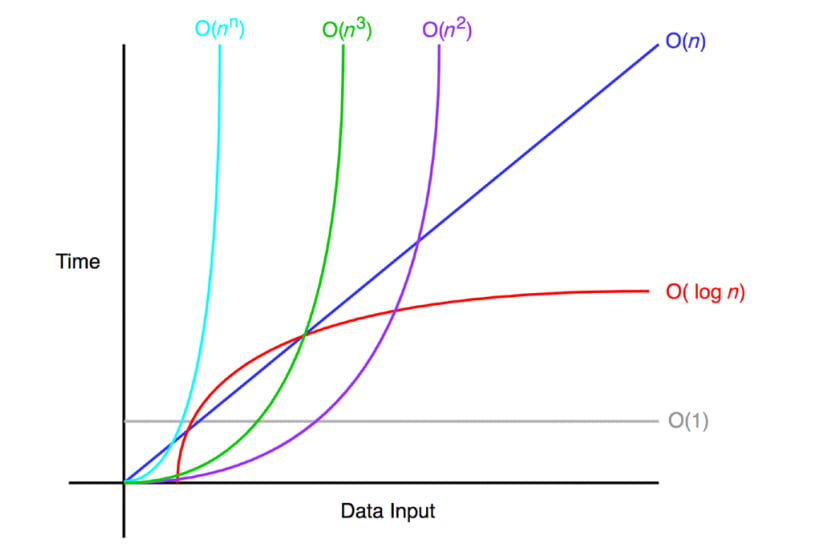
위 그래프처럼 만약 코드 최적화를 통해 을 로 바꿨다면 기하급수적으로 빨라지는 것을 확인 할 수 있다.
7.3 배열 예제 (소규모 샘플링)
기본 코드
function getSample(array) {
let first = array[0];
let middle = array[parseInt(array.length / 2, 10)];
let last = array[-1];
return [first, middle, last];
}getSample([1, 2, 3, 4, 5, 6, 7, 8]); // (3) [1, 5, 8]
getSample([1, 3, 5, 7, 9]); // (3) [1, 5, 9]해설
function getSample(array) {
// 매개변수로 받은 배열의 처음, 중간, 마지막 요소를 변수에 할당한다.
// 중간값의 경우 배열 길이 절반의 정수 부분을 파싱하여 사용한다.
let first = array[0];
let middle = array[parseInt(array.length / 2, 10)];
let last = array[array.length - 1];
// 각 값을 배열에 담아 반환한다.
return [first, middle, last];
}getSample 함수에서 은 매개변수로 들어온 배열의 원소 수, 즉 배열의 크기(길이)이다.
하지만 이 무슨 수인지와는 무관하게 getSample 함수 수행에 필요한 단계 수는 동일하다.
배열의 처음, 중간, 마지막 인덱스는 배열의 크기에 상관없이 한 단계이기 때문이다.
단계 수가 상수이므로, 즉 에 관계 없이 단계 수가 일정하므로 getSample 함수의 시간 복잡도는 이다.
7.4 평균 섭씨 온도 구하기
기본 코드
function getCelsiusAvg(fahrenheit) {
let celsius = [];
for (let i = 0; i < fahrenheit.length; i++) {
const convertCelsius = (fahrenheit[i] - 32) / 1.8;
celsius.push(convertCelsius);
}
let sum = 0;
for (let i = 0; i < celsius.length; i++) {
sum += celsius[i];
}
return sum / celsius.length;
}getCelsiusAvg([140, 270, 340]); // 121.11111111111113
getCelsiusAvg([99, 199, 299]); // 92.77777777777779해설
function getCelsiusAvg(fahrenheit) {
// 섭씨 온도를 모을 배열
let celsius = [];
// fahrenheit의 각 값을 섭씨로 변환하여 celsius에 추가한다.
for (let i = 0; i < fahrenheit.length; i++) {
const convertCelsius = (fahrenheit[i] - 32) / 1.8;
celsius.push(convertCelsius);
}
// 섭씨 온도의 합
let sum = 0;
// celsius를 순회하며 섭씨 온도의 합을 구한다.
for (let i = 0; i < celsius.length; i++) {
sum += celsium[i];
}
// 섭씨 온도의 합을 섭씨의 수로 나누어 평균을 반환한다.
return sum / celsius.length;
}getCelsiusAvg 함수에서 은 fahrenheit 배열의 개수이다.
그리고 두 개의 for 루프를 실행하는데 하나는 읽은 값을 섭씨로 변환하고, 다른 하나는 섭씨의 합을 구한다.
2개의 for 루프에서 모두 을 순회하므로 , 즉 단계가 걸린다. (추가로 상수 몇 단계가 있지만 생략)
빅 오에서는 상수는 무시되므로 getCelsiusAvg 함수의 시간 복잡도는 으로 표기한다.
❗️ 중첩 루프와 헷갈리지 말자❗️
for 루프가 2개이기 때문에 이라고 생각할 수 있다.
그러나 알고리즘은 중첩 루프의 경우이므로
getCelsiusAvg 함수 예제같이 for 루프를 중첩이 아닌 나란히 실행할 경우는 단순히 단계,
즉 단계가 소요되므로 상수를 무시하여 이다.
7.5 의류 상표
기본 코드
function markInventory(clothingItems) {
let clothingOptions = [];
for (let i = 0; i < clothingItems.length; i++) {
for (let size = 1; size <= 5; size++) {
clothingOptions.push(`${clothingItems[i]} Size: ${size}`);
}
}
return clothingOptions;
}markInventory(['Chanel', 'Miu Miu', 'Ami']);
/*
[
'Chanel Size: 1',
'Chanel Size: 2',
'Chanel Size: 3',
'Chanel Size: 4',
'Chanel Size: 5',
'Miu Miu Size: 1',
'Miu Miu Size: 2',
'Miu Miu Size: 3',
'Miu Miu Size: 4',
'Miu Miu Size: 5',
'Ami Size: 1',
'Ami Size: 2',
'Ami Size: 3',
'Ami Size: 4',
'Ami Size: 5'
]
*/해설
function markInventory(clothingItems) {
// 품명과 1부터 5까지 사이즈가 포함된 상표 텍스트 배열
let clothingOptions = [];
// clothingItem을 순회하며
// 1부터 5까지의 상표 텍스트를 만들어 clothingOptions에 넣는다.
for (let i = 0; i < clothingItems.length; i++) {
for (let size = 1; size <= 5; size++) {
clothingOptions.push(`${clothingItems[i]} Size: ${size}`);
}
}
// 상표 텍스트 배열을 반환한다.
return clothingOptions;
}markInventory 함수에서 은 매개변수로 받는 clothingItems 배열의 수이다.
중첩 루프가 있는 코드이므로 으로 착각하기 쉽지만 위 예제에서는 바깥 for 루프가 을 순회하는 동안, 내부 for 루프에서 을 순회하지 않고, 과 상관 없이 항상 5번 실행된다.
즉 바깥 루프가 번 실행될 때, 내부 루프는 에 대해 각각 5번 실행되므로 총 이다.
그러나 빅 오는 상수를 무시하므로 markInventory 함수의 시간 복잡도는 으로 표기한다.
7.6 1세기
기본 코드
function countOnes(multiArray) {
let count = 0;
for (let i = 0; i < multiArray.length; i++) {
for (let j = 0; j < multiArray[i].length; j++) {
if (multiArray[i][j] === 1) count += 1;
}
}
return count;
}countOnes([[1, 0, 1], [0, 1], [0, 0, 1, 1]]); // 5
countOnes([[1, 0, 1], [1], [0, 1, 1, 0, 1]]); // 6해설
function countOnes(multiArray) {
// 1의 개수를 담을 변수
let count = 0;
// multiArray의 요소(배열)을 순회한다.
for (let i = 0; i < multiArray.length; i++) {
// 각 요소(배열) 내부의 수를 순회한다.
for (let j = 0; j < multiArray[i].length; j++) {
// 1일 경우 count 변수의 수를 1 증가한다.
if (multiAray[i][j] === 1) count += 1;
}
}
// 1의 개수를 반환한다.
return count;
}위 예제의 경우에도 중첩 루프로 인해 로 오해할 수 있다. 하지만 두 개의 루프가 완전히 다른 배열을 순회한다.
바깥 for 루프는 multiArray의 각 요소인 내부 배열을 순회하고, 안쪽 for 루프는 내부 배열 내 실제 숫자 요소들을 순회한다. 결국 안쪽 for 루프가 실제 숫자의 개수만큼 실행되기 때문에 countOnes 함수에서 은 숫자 요소의 개수다. 빅 오로는 으로 표기한다.
7.7 팰린드롬 검사기
팰린드롬(Palindrome)이란?
'회문(回文)'이라는 뜻으로, "eye", "madam" 처럼 역순으로 읽어도 같은 말이 되는 말을 말한다.
기본 코드
function isPalindrome(string) {
let left = 0;
let right = string.length - 1;
while (left < string.length / 2) {
if (string[left] !== string[right]) return false;
left++;
right--;
}
return true;
}isPalindrome('level'); // true
isPalindrome('junehee'); // false해설
function isPalindrome(string) {
// 왼쪽 인덱스와 오른쪽 인덱스 변수 선언
// 왼쪽 인덱스는 0에서 시작, 오른쪽 인덱스는 마지막 인덱스에서 시작한다.
let left = 0;
let right = string.length - 1;
// 왼쪽 인덱스가 배열 중간에 도달할 때까지 반복 순회한다.
while (left < string.length / 2) {
// 왼쪽 문자와 오른쪽 문자가 일치하지 않으면 팰린드롬이 아니다.
if (string[left] !== string[right]) return false;
// 왼쪽 인덱스를 오른쪽으로 한 칸,
// 오른쪽 인덱스를 왼쪽으로 한 칸 이동시킨다.
left++;
right--;
}
// 불일치하는 문자 없이 통과하면 문자열은 팰린드롬이다.
return true;
}위 예제 isPalindrome 함수에서 은 매개변수로 전달된 string의 크기이다.
그리고 핵심은 while 루프인데, 문자열 중간에 도달할 때까지만 실행된다.
즉, while 루프가 만큼 실행된다는 뜻이다.
하지만 계속해서 말했듯이 빅 오에서는 지수를 제외한 상수는 무시하기 때문에
isPalindrome 함수의 시간 복잡도는 이다.
7.8 모든 곱 구하기
기본 코드
function twoNumberProducts(array) {
let products = [];
for (let i = 0; i < array.length; i++) {
for (let j = i + 1; j < array.length; j++) {
products.push(array[i] * array[j]);
}
}
return products;
}twoNumberProducts([1, 3, 5, 7]); // (6) [3, 5, 7, 15, 21, 35]
twoNumberProducts([9, 8, 7, 6, 5]); // (10) [72, 63, 54, 45, 56, 48, 40, 42, 35, 30]해설
function twoNumberProducts(array) {
// 모든 두 숫자의 곱을 담을 배열
let products = [];
// array의 각 요소를 순회
// j는 항상 i의 오른쪽에서 시작한다.
for (let i = 0; i < array.length; i++) {
for (let j = i + 1; j < array.length; j++) {
// 두 수의 곱을 products에 담는다.
products.push(array[i] * array[j]);
}
}
// 두 숫자의 곱 배열을 반환한다.
return products;
}twoNumberProducts 함수에서 함수에 전달된 배열 array의 크기(길이)이다.
중첩 루프를 통해 바깥 for 루프에서 번 실행하고,
안쪽 for 루프는 항상 i + 1에서 시작하므로 바깥 for 루프가 1번씩 돌 때 마다 1씩 줄어들게 된다.
🧐 만약 원소가 5개인 배열이라면?
const arr = [0, 1, 2, 3, 4];i가 0일 때,j는 1, 2, 3, 4동안 실행된다.i가 1일 때,j는 2, 3, 4동안 실행된다.i가 2일 때,j는 3, 4동안 실행된다.i가 3일 때,j는 4동안 실행된다.
종합해보면 안쪽 for 루프는 실행된다.
의 관점에서 생각했을 때 실행되고,
이 공식은 항상 로 계산된다. 하지만 상수를 무시하는 빅 오에서는 로 표기한다.
여러 데이터 세트 다루기
🤓 한 배열의 모든 수와 다른 한 배열의 모든 수를 곱하면 어떻게 될까?
function twoNumberProduct2(array1, array2) {
let products = [];
for (let i = 0; i < array1.length; i++) {
for (let j = 0; j < array2.length; j++) {
product.push(array1[i] * array2[j]);
}
}
return products;
}twoNumberProduct2 함수에서 은 두 개의 데이터 세트, 즉 두개의 배열이다.
만약 을 두 배열을 합쳤을 때의 총 항목 수라고 가정했을 때,
- 5개의 원소를 가진 배열 2개
- 9개의 원소를 가진 배열 / 1개의 원소를 가진 배열
위 두 시나리오에 대해 각각 을 계산해보면 1번과 2번의 경우는 모두 이다.
그러나 효율성 측면에서,
- 1번 시나리오는 가 소요되므로 가 소요된다.
- 2번 시나리오는 가 소요되므로 가 소요된다.
어떤 시나리오인지에 따라 달라지기 때문에 빅 오 표기법 관점에서 효율성을 정확하게 정의할 수 없으므로 을 두 배열의 총 항목 수라고 볼 수 없다.
한 배열의 크기를 , 다른 배열의 크기를 으로 설정 후 시간 복잡도를 으로 표현할 수밖에 없다. 그리고 이런 알고리즘은 빅 오 표기법 관점에서 올바르게 나타내는 방법이지만 다른 빅 오 표현보다 유용성이 떨어진다.
하지만 이 속하는 특정 범위가 있다.
- 과 이 같으면, 과 동일하다.
- 과 이 같지 않으면, 더 작은 수를 임의로 에 할당하여 이 된다.
따라서 은 ~ 사이 정도로 이해할 수 있다. 이것이 최선이다.
7.9 암호 크래커
브루트 포스(Brute Force)란?
조합 가능한 모든 경우의 수를 다 대입해보는 것이다.
최적화나 효율과는 거리가 멀며, 단순하게 보이기도 하지만 정확도 100%를 가진다.
누군가의 암호를 풀어야 하는 해커라고 가정했을 때, 브루트 포스 방식으로 문자열을 조합하는 코드를 작성하면 아래와 같다. (자바스크립트로 변환 실패.......)
기본 코드
def every_password(n)
(("a" * n)..("z" * n)).each do |str|
puts str
end
end해설
def every_password(n)
# "a" * n에서 "z" * n까지의 범위를 생성하고 각 문자열에 대해 반복
(("a" * n)..("z" * n)).each do |str|
puts str
end
end- 알파벳을 하나씩 출력할 경우,
- 알파벳을 두 개씩 조합하여 출력할 경우,
- 알파벳을 세 개씩 조합하여 출력할 경우, ...
의 관점에서 살펴보면 이 문자열의 길이일 때 총 조합의 수는 이다.
따라서 빅 오로는 으로 표기한다.
조차 얼마나 느린지는... 아래의 그래프를 보면 알 수 있다.
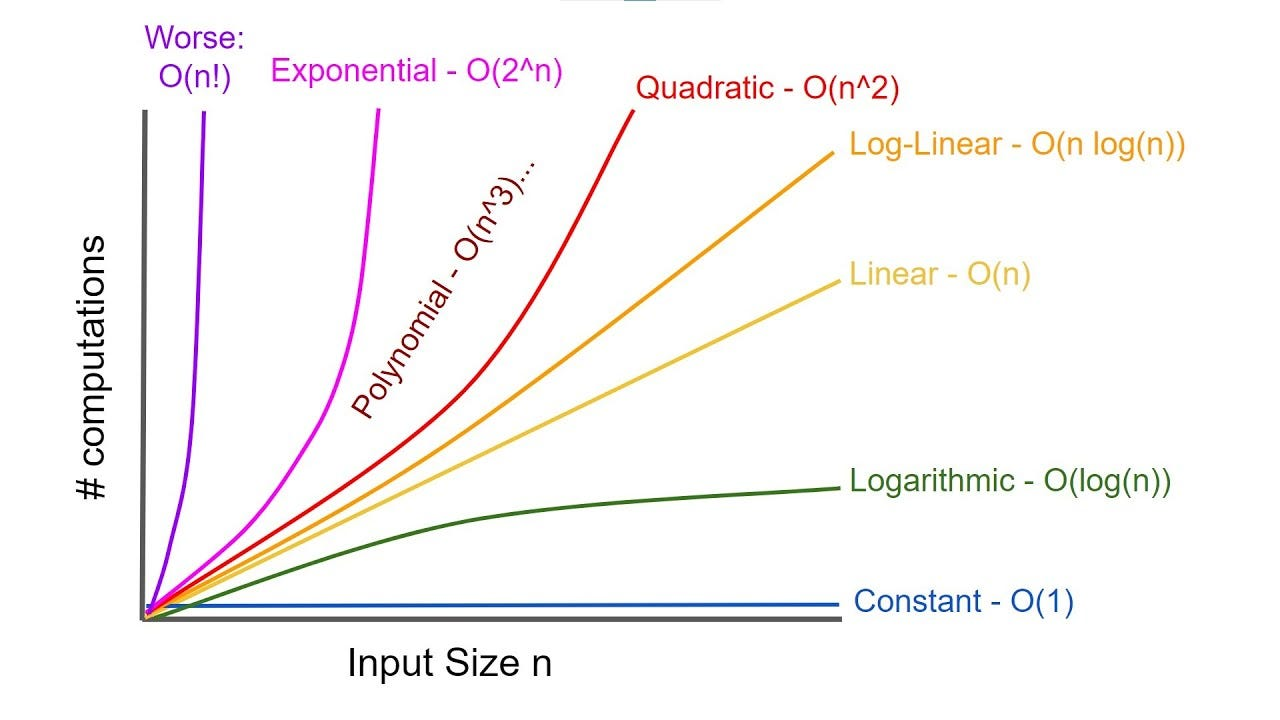
은 의 반대이다.
이진 검색처럼 인 알고리즘에서는 데이터가 두 배로 늘어날 때 알고리즘 수행 단계가 1단계씩 늘어난다. 반대로 는 데이터가 한 개 늘어날 때 알고리즘 수행 단계가 2배로 늘어나는 것이다.
everyPassword 함수에서는 이 1씩 늘어날 때마다, 알고리즘 수행 단계 수는 26배씩 늘어나게 된다.
실습
-
아래 조건을 만족하는 알고리즘이 있을 때, 다음 함수의 시간 복잡도는?
- 첫 번째 수와 마지막 수를 더하면 100이다.
- 두 번째 수와 끝에서 두 번째 수를 더하면 100이다.
- 세 번째 수와 끝에서 세 번째 수를 더하면 100이다.
- (이하 동등)
function isOneHundredSum(array) {
let left = 0;
let right = array.length - 1;
while (left < array.length / 2) {
if (array[left] + array[right] !== 100) return false;
left += 1;
right -= 1;
}
return true;
}정답 :
- 두 정렬된 배열을 병합하여 두 배열의 모든 값을 포함하는 새로운 정렬된 배열을 생성하는 함수이다.
이 함수의 시간 복잡도는?
function getMergeArray(array1, array2) {
let newArray = [];
let pointer1 = 0;
let pointer2 = 0;
while (pointer1 < array1.length || pointer2 < array2.length) {
if (!array1[pointer1]) {
newArray.push(array2[pointer2]);
pointer2 += 1;
} else if (!array2[pointer2]) {
newArray.push(array1[pointer1]);
pointer1 += 1;
} else if (array1[pointer1] < array2[pointer2]) {
newArray.push(array1[pointer1]);
pointer1 += 1;
} else {
newArray.push(array2[pointer2]);
pointer += 2;
}
}
return newArray;
}정답 :
- 다음 함수는 주어진 배열에 들어 있는 수 세개를 곱해 가장 큰 값을 찾는 함수이다.
이 함수의 시간 복잡도는?
function getLargestNumber(array) {
let largest = array[0] * array[1] * array[2];
let i = 0;
while (i < array.length) {
let j = i + 1;
while (j < array.length) {
let k = j + 1;
while (k < array.length) {
if (array[i] * array[j] * array[k] > largest) {
largest = array[i] * array[j] * array[k];
}
k += 1;
}
j += 1;
}
i += 1;
}
return largest;
}정답 :
- 하나가 남을 때까지 양 쪽에서 번갈아 데이터를 반으로 제거하는 함수가 있다.
이 함수의 시간 복잡도는?
function pickOne(datas) {
let eliminate = "top";
while (datas.length > 1) {
if (eliminate === "top") {
datas = datas.slice(datas.length / 2, datas.length);
eliminate = "bottom";
} else if (eliminate === "bottom") {
datas = datas.slice(0, datas.length / 2);
eliminate = "top";
}
}
return datas[0];
}정답 :
