
4.1 버블 정렬
정렬 알고리즘(Sorting Algorithm)이란?
원소들을 번호순이나 사전 순서와 같이 일정한 순서대로 열거하는 알고리즘
"정렬되지 않은 배열이 주어졌을 때, 어떻게 오름차순으로 정렬할 수 있을까?"와 같은 문제를 해결한다.
버블 정렬(Bubble Sort)이란?
두 개의 인접한 요소를 비교하여 순서에 맞지 않으면 교환하여 정렬하는 알고리즘
원소의 이동이 거품이 수면으로 올라오는 듯한 모습을 보이기 때문에 지어진 이름으로 "거품 정렬"이라고 부르기도 한다.
버블 정렬은 아래 단계에 따라 실행된다.
-
배열 내에서 연속된 두 요소를 가리켜 비교한다. (처음에는 배열의 첫 번째 ~ 두 번째 원소)
2 1 3 5 👆 👆 -
두 요소의 순서가 뒤바뀌어 있다면, 순서를 교환(swap)한다.
만약 두 요소의 순서가 올바르다면 2단계에서는 아무 것도 실행하지 않는다.1 2 3 5 👆 👆 -
포인터를 오른쪽으로 한 셀 이동한다.
1 2 3 5 👆 👆 -
배열의 마지막까지 1~3단계를 반복한다. (= 첫 패스스루 종료)
-
포인터를 다시 배열의 처음 두 값으로 옮겨 1~4단계를 다시 실행하며 새로운 패스스루를 실행하고, 교환(swap)이 일어나지 않는 패스스루가 생길 때까지 반복한다.
-
교환이 생기지 않으면 배열이 정렬되었다는 의미이다. (= 문제 해결)
패스스루(pass-through)란?
알고리즘의 주요 단계를 통과했다는 의미
4.2 버블 정렬 실제로 해보기
첫 번째 패스스루
-
가장 처음 연속된 두 요소인
4와2를 비교한다.4 2 7 1 3 👆 👆 -
두 번째 요소인
2가 첫 번째 요소인4보다 작으므로 순서가 맞지 않아 서로 교환(swap)한다.2 4 7 1 3 👆 👆 -
포인터를 한 셀 이동하여
4와7을 비교한다.
4가7보다 작으므로 순서가 올바르기 때문에 교환이 일어나지 않는다.2 4 7 1 3 👆 👆 -
포인터를 한 셀 이동하여
7과1을 비교한다.2 4 7 1 3 👆 👆 -
1이7보다 작으므로 순서에 맞지 않아 서로 교환한다.2 4 1 7 3 👆 👆 -
포인터를 한 셀 이동하여
7과3을 비교한다.2 4 1 7 3 👆 👆 -
3이7보다 작으므로 순서에 맞지 않아 서로 교환한다.2 4 1 3 7 👆 👆
위 과정을 통해 7은 적절한 위치로 자리하기까지 계속 이동되었다. (💯)
버블 정렬은 각 패스스루마다 정렬되지 않은 값 중 가장 큰 값, 즉 '버블'이 올바른 위치로 이동하게 된다.
첫 번째 패스스루에서 최소 1회 이상 교환을 수행했으니 다음 패스스루를 실행해야 한다.
두 번째 패스스루
-
다시 처음 두 요소로 돌아가
2와4를 비교한다.
2가 4보다 작으므로 순서가 올바르기 때문에 교환이 일어나지 않는다.2 4 1 3 7 👆 👆 💯 -
포인터를 한 셀 이동하여
4와1을 비교한다.2 4 1 3 7 👆 👆 💯 -
1이4보다 작으므로 순서에 맞지 않아 서로 교환한다.2 1 4 3 7 👆 👆 💯 -
포인터를 한 셀 이동하여
4와3을 비교한다.2 1 4 3 7 👆 👆 💯 -
3이4보다 작으므로 순서에 맞지 않아 서로 교환한다.2 1 3 4 7 👆 👆 💯
첫 번째 패스스루를 통해 7이 최적의 자리에 위치해 있으므로 4와 7은 비교하지 않는다. 그리고 4 역시 두 번째 패스스루를 통해 적절한 자리로 이동했다.
두 번째 패스스루에서도 교환이 일어났으므로 세 번째 패스스루를 실행해야 한다.
세 번째 패스스루
-
다시 처음 두 요소로 돌아와 2와 1을 비교한다.
2 1 3 4 7 👆 👆 💯 💯 -
1이 2보다 작으므로 순서에 맞지 않아 서로 교환한다.
1 2 3 4 7 👆 👆 💯 💯
-
포인터를 한 셀 이동하여
2와3을 비교한다.
그러나 순서가 올바르기 때문에 교환이 일어나지 않고4는 두 번째 패스스루를 통해 최적의 자리에 위치해있기 때문에 추가 비교를 하지 않는다. 이로써3도 적절한 자리로 이동이 완료됐다.1 2 3 4 7 👆 👆 💯 💯
세 번째 패스스루에서도 최소 1회 이상의 교환이 일어났으므로 네 번째 패스스루를 실행한다.
네 번째 패스스루
-
처음 두 요소로 돌아와
1와2를 비교한다.
그러나 순서가 올바르기 때문에 교환이 일어나지 않고 나머지 요소들도 전부 최적의 자리에 위치해있으므로 네 번째 패스스루를 종료한다.1 2 3 4 7 👆 👆 💯 💯 💯
네 번째 패스스루에서는 교환이 일어나지 않았으므로 배열이 완전히 정렬되었다고 판단한다.
코드로 구현한다면
for문, swap 변수 사용
function bubbleSort(array) {
let length = array.length;
for (let i = 0; i < length; i++) {
for (let j = 0; j < length; j++) {
if (array[j] > array[j + 1]) {
let swap = array[j];
array[j] = array[j + 1];
array[j + 1] = swap;
}
}
}
return array;
}while문, 구조분해할당 사용
function bubbleSort(array) {
let length = array.length;
let isSorted = false;
while (!isSorted) {
isSorted = true;
for (let i = 0; i < length; i++) {
if (array[i] > array[i + 1]) {
[array[i], array[i + 1]] = [array[i + 1], array[i]];
isSorted = false;
}
}
length -= 1;
}
return array;
}(이외에도 여러가지 방법으로 버블 정렬 코드를 구현할 수 있다.)
4.3 버블 정렬의 효율성
버블 정렬 알고리즘은 '비교와 교환' 이라는 두 가지 중요한 단계를 포함한다.
- 비교(comparison) : 어느 쪽이 더 큰지 두 수를 비교
- 교환(swap) : 정렬을 위해 두 수를 교환
비교
4.2 예제에서 배열의 원소는([4, 2, 7, 1, 3]) 총 5개였다.
- 첫 번째 패스스루 : 4번의 비교 수행
- 두 번째 패스스루 : 3번의 비교 수행
- 세 번째 패스스루 : 2번의 비교 수행
- 네 번째 패스스루 : 1번의 비교 수행
따라서, 의 비교를 수행했다.
만약 원소가 개라면 의 비교를 수행한다.
교환
배열이 내림차순으로 정렬된 최악의 시나리오라면 비교할 때마다 교환을 해야 한다.
🤔 원소가 5개일 경우부터 생각해보자.
원소 5개가 역순(내림차순)으로 정렬된 배열에서는 의 비교를 해야 한다.
더불어 교환도 해야하니 총 20단계가 필요하다.
🤨 원소를 2배 늘려서, 10개일 때는?
- 비교 :
- 교환 :
총 90단계가 필요하다.
😰 그럼 20개일 때는?
- 비교 :
- 교환 :
총 380단계가 필요하다.
이처럼 버블 정렬은 원소의 개수가 증가할 때마다 알고리즘에 필요한 단계 수가 기하급수적으로 늘어나고, 그 수치는 에 가까이 늘어나는 것을 알 수 있다.
| 데이터 원소 N개 | 버블 정렬 단계 수 | |
|---|---|---|
| 5 | 20 | 25 |
| 10 | 90 | 100 |
| 20 | 380 | 400 |
| 40 | 1560 | 1600 |
| 80 | 6320 | 6400 |
👀 그래서 버블 정렬의 시간 복잡도는?
빅 오는 데이터가 개일 때 알고리즘의 (최악의) 실행 단계 수를 측정하는 것이므로 값이 개일 때 버블 정렬은 단계가 필요하고, 빅 오로 표기하면 이다.
: 이차 시간(Quadratic Time) 복잡도
입력값이 증가함에 따라 시간이 의 제곱수의 비율로 증가하는 알고리즘을 로 표현한다. 그리고 이차 시간(Quadratic Time)이라고 부르기도 한다.
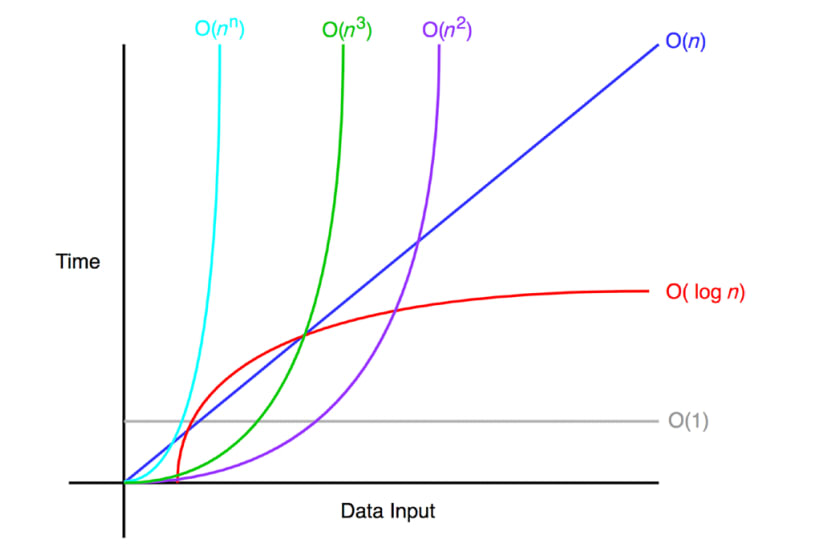
위 그래프를 보면 은 데이터가 늘어날수록 단계 수가 급격히 증가한다.
4.4 이차 문제
같은 느린 알고리즘을 빠른 알고리즘으로 대체할 수 있을까?
function hasDuplicateValue1(array) {
for (let i = 0; i < array.length; i++) {
for (let j = 0; j < array.length; j++) {
if (i !== j && array[i] === array[j]) {
return true;
}
}
}
return false;
}hasDuplicateValue1([1,5,3,9,1,4]); // true
hasDuplicateValue1([1,2,3,4,5]); // false위 코드는 인자로 받은 배열 내 요소에 중복된 값이 있는지를 체크하여 boolean 값으로 반환하는 함수이다. 과연 이 함수에 개의 데이터를 가진 배열을 대입하면, 최악의 시나리오에서 알고리즘 수행에 필요한 단계는 얼마일까?
hasDuplicateValue1 함수는 i와 j를 반복해서 비교하며 중복을 체크한다. 만약 배열이 중복 값을 포함하지 않는 경우라면 false를 반환하기 위해 모든 루프를 돌며 가능한 모든 조합을 전부 비교해야 한다.
즉, 배열에 개의 데이터가 있을 때 hasDuplicateValue1 함수는 번의 비교를 수행한다. 바깥쪽 for문이 번, 안쪽 for문이 번 순회하므로 번의 비교 수행, 의 시간 복잡도를 가진다
function hasDuplicateValue1(array) {
let steps = 0;
for (let i = 0; i < array.length; i++) {
for (let j = 0; j < array.length; j++) {
steps += 1;
if (i !== j && array[i] === array[j]) {
return true;
}
}
}
console.log(`수행 단계 수 : ${steps}`);
return false;
}hasDuplicateValue([1,2,3,4,5]);
// 수행 단계 수 : 25
// false
hasDuplicateValue([9,5,3,14,7,28]);
// 수행 단계 수 : 36
// false함수의 실행 결과처럼 배열의 크기(length)의 제곱이 출력된다. 이는 전형적인 이다.
루프 내에 다른 루프를 중첩하는 알고리즘이라면 대부분 의 시간 복잡도를 가진다. (항상은 아님⚠️)
따라서, 중첩된 루프가 보인다면 머릿 속에 알고리즘을 떠올려야 한다.
하지만 알고리즘은 비교적 느린 알고리즘에 속하기 때문에 더 나은 대안, 더 빠른 방법이 없는지 한 번쯤 고민해보는 것이 좋다.
선형 해결법
function hasDuplicateValue2(array) {
let existingNumbers = [];
for (let i = 0; i < array.length; i++) {
if (existingNumbers[array[i]] === 1) {
return true;
} else existingNumbers[array[i]] = 1;
}
return false;
}위 함수는 중첩 루프를 사용하지 않는 버전이다. existingNumbers 이라는 빈 배열을 생성하고 루프를 순회하며 array의 각 데이터(숫자)를 확인하여 existingNumbers 배열에서 그 숫자에 해당하는 인덱스(index)에 임의의 값 (예제 함수에서는 1)을 할당한다.
const arr = [2, 4, 5];
hasDuplicateValue2(arr); // false위 예제에서 중간에 콘솔을 찍어 existingNumbers 배열의 상태를 확인해보면,
[undefined, undefined, 1]
[undefined, undefined, 1, undefined, 1]
[undefined, undefined, 1, undefined, 1, 1]
위처럼 해당 인덱스에 임의의 값 1이 할당되고, 나머지 자리에는 undefined 처리된다.
그리고 if문의 조건인 '중복'에 해당되면 true를 반환하며 함수 실행이 중단된다.
😰 선형 해결법에서 최악의 시나리오는?
중복 값이 없을 때, hasDuplicateValue2 함수는 데이터 셋의 각 요소에 대해 모든 루프를 순회하기 때문에 최악의 시나리오가 발생한다. 아래와 같이 확인해볼 수 있다.
function hasDuplicateValue2(array) {
let steps = 0;
let existingNumbers = [];
for (let i = 0; i < array.length; i++) {
steps += 1;
if (existingNumbers[array[i]] === 1) {
return true;
} else existingNumbers[array[i]] = 1;
}
console.log(`수행 단계 수 : ${steps}`);
return false;
}const arr1 = [2, 4, 5, 7, 9];
const arr2 = [2, 4, 4, 7, 8];
hasDuplicateValue2(arr1);
// 수행 단계 수 : 5
// false
hasDuplicateValue2(arr2);
// true중복 값이 없는 배열에서는 수행 단계 수와 false가 반환되고, 중복 값이 있을 경우에는 if문에 해당되는 블럭 내에서 true가 반환된다. 수행 단계 수, 즉 선형 해결법 알고리즘의 시간 복잡도는 데이터 개수와 같은 이다.
의 시간 복잡도를 가졌던 hasDuplicateValue1 함수와 달리 hasDuplicateValue2 함수는 으로 속도 측면에서 엄청난 향상을 가져온 걸 알 수 있다. (그러나 메모리 측면에서는 더 소비가 이뤄진다고 한다 - 19장 내용에서 다룰 예정)
요약
- 정렬 알고리즘(Sorting Algorithm)이란 원소들을 번호순이나 사전 순서와 같이 일정한 순서대로 열거하는 알고리즘이다.
- 버블 정렬(Bubble Sort)이란 두 개의 인접한 요소를 비교하여 순서에 맞지 않으면 교환하여 정렬하는 알고리즘이다.
- 버블 정렬에서는 '비교'와 '교환'이 이뤄지고, 의 시간 복잡도를 가진다.
- 선형 해결법을 사용해 의 시간 복잡도를 으로 최적화 해볼 수 있다.
