
들어가기 전에
앞 장에서는 자료구조에서 알고리즘 수행에 필요한 단계에 대해 알아보았다.
하지만 매 알고리즘마다 총 몇 단계가 필요한지 매번 계산하여 표기할 수는 없는 노릇이다.
왜냐하면 해당 알고리즘에 필요한 단계 수를 하나의 수로 못박을 수 없기 때문이다.
이러한 이유로 나오게된 방법이 '빅 오 표기법'이다. 빅 오 표기법은 매번 특정한 수의 단계가 소요된다고 인지하는 것보다, 자료 구조와 알고리즘의 효율성을 간결하고 일관된 언어로 설명하기 위해 수학적 개념을 차용하여 표현하는 것이다.
빅 오 표기법(big-O Notation)이란?
인자가 특정한 값이나 무한대로 향할 때 함수의 극한적인 동작을 설명하는 수학적인 표기법으로 '점근 표기법'이라고도 부릅니다. 알고리즘의 시간 복잡도를 나타내며, 알고리즘이 해당 차수이거나 그보다 낮은 차수의 시간복잡도를 가지고 있다는 의미입니다. 즉 알고리즘의 '최악 실행 시간'을 표기합니다.
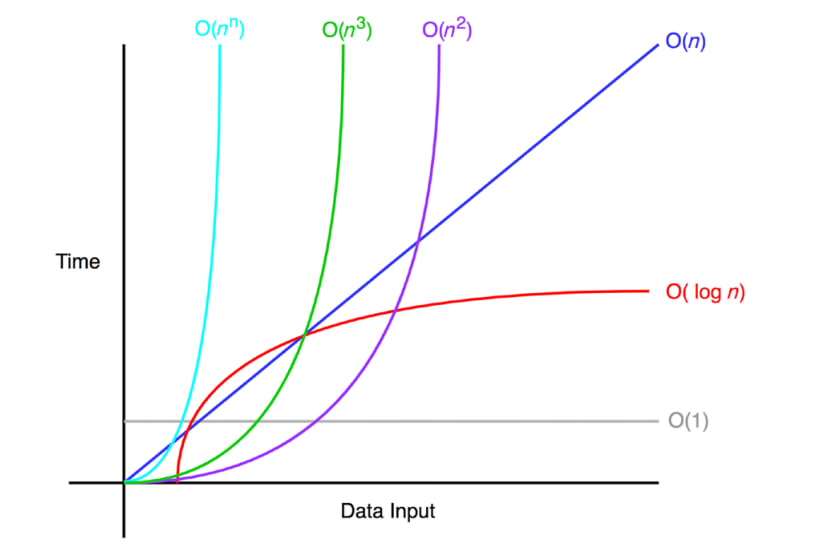
3.1 빅 오: 원소가 N개일 때 몇단계가 필요할까?
선형 검색 (Linear Search)
선형 검색은 원하는 데이터를 찾을 때까지 가장 앞에 있는 데이터에서 마지막 데이터까지 순차적으로 순회하므로, 단계가 필요하다. 고로 선형 검색의 시간 복잡도는 이다. ("오 N"이라고 부른다.)
의 시간복잡도를 가지는 알고리즘을 선형 시간(lenear time) 알고리즘이라고 부르기도 한다.
일반 배열에서 읽기
일반적인 배열에서 특정 위치의 값을 읽을 때에는 인덱스(index)를 통해 직접 접근하여 바로 데이터를 읽을 수 있다. 그러므로 배열 읽기에서 시간 복잡도는 이다. ("오 1"이라고 부른다.)
이러한 이유로 은 가장 빠른 알고리즘으로 분류한다.
데이터가 늘어나도 알고리즘 실행에 필요한 단계 수는 증가하지 않기 때문이다.
이 얼마든 항상 상수 단계만 필요하기 때문에 시간(constant time) 알고리즘이라고 부르기도 한다.
3.2 빅 오의 본질
🧐 데이터가 몇 개든 항상 3단계가 걸리는 알고리즘은 빅 오로 어떻게 표기할까?
보통은 이라고 답하겠지만 정답은 이다.
빅 오(big-O)의 본질이 의미하는 것은 데이터가 늘어날 때 알고리즘의 성능이 어떻게 바뀌는지를 뜻하기 때문이다. 단순히 알고리즘에 필요한 단계 수만 알려주는 것이 아닌, 데이터가 늘어날 때 단계 수가 어떻게 증가하는지를 설명하는 것이다.
이런 관점에서 과 은 크게 다르지 않다. 두 알고리즘 모두 데이터 증가에 따른 영향을 받지 않는 유형이므로 본질적으로 같은 알고리즘이라고 할 수 있다.
🤔 그럼 데이터에 증가에 따라 영향을 받는 알고리즘 유형은 뭔가요?
은 데이터의 증가가 성능에 영향을 미치는 알고리즘이다. 즉 데이터에 비례하여 단계 수가 늘어난다.
그래프로 확인했을 때 은 데이터가 하나 추가될 때마다 한 단계씩 증가하기 때문에 완벽한 대각선을 그린다.
반면에 은 데이터가 추가되더라도 상관없이 단계 수가 일정하게 유지된다.
👀 은 알고리즘보다 매번 성능이 우수할까?
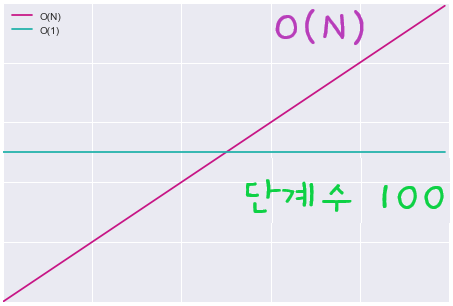
그래프를 보면 원소가 100개 이하일 경우 100단계가 걸리는 알고리즘보다 알고리즘의 단계수가 더 적은 것을 확인할 수 있다. 두 선의 교차시점인 원소 100개 지점에서는 두 단계가 동일하게 100단계가 소요된다. 그러나 핵심은 100보다 큰 모든 배열에서는 알고리즘에 더 많은 시간이 걸린다는 것이다.
100단계가 아니라 1000단계, 10000단계일 경우에도 데이터가 증가할수록 이 보다 덜 효율적인 지점이 반드시 생기며 이 지점부터 데이터 양이 무한대로 갈 때까지 바뀌지 않는다.
🤓 그럼 같은 알고리즘은 항상 같은 시간 복잡도를 가질까?
빅 오(big-O) 표기법은 별도로 명시하지 않는 한 최악의 시나리오를 의미한다. 배열의 선형 검색(Linear Search)에서 찾고싶은 데이터가 가장 처음과 가장 마지막에 있을 때 각각의 단계 수는 1단계, N단계이지만 선형 검색의 시간 복잡도는 보통 으로 표기한다.
이처럼 같은 알고리즘이어도 다른 시간 복잡도를 가질 수 있으며, 별도 명시가 없는 한 최악의 경우를 디폴트로 가져간다. 그 이유는 알고리즘의 비효율성을 알고 최악을 대비함과 동시에 알고리즘 선택에 중요한 영향을 미칠 수 있기 때문이다.
3.3 세 번째 유형의 알고리즘
이진 검색(Binary Search)은 데이터가 커질수록 단계 수가 늘어나므로 이라 표현할 수 없고, 검색보다 단계 수가 훨씬 적으므로 이라 표현할 수도 없다. 그렇다면 ~ 사이의 알고리즘은 어떻게 나타낼까?
: 로그 시간(log time) 복잡도
데이터가 두 배로 증가할 때 마다 한 단계씩 늘어나는 알고리즘을 로 표현하고, "오 로그 N"이라고 말한다.
위 세 가지 알고리즘을 그래프 상에서 비교했을 때, 은 아주 조금씩 증가하는 곡선을 그리고 있다. 보다는 덜 효율적이지만, 보다는 훨씬 효율적이다는 것을 알 수 있다.
3.4 로가리즘
🤨 왜 이라고 표현하나요? 로그란 무엇인가요?
로그는 로가리즘(logarithm)의 줄임말이며, 로가리즘은 지수(exponent)와 역(inverse)의 관계이다.
로가리즘을 아래 예제로 이해해보자.
예제 1
는 와 같은 값을 가지며, 그 값은 이다.
은 의 역(inverse)이다. 즉, 2를 몇 번 곱해야 8을 얻을 수 있는지를 뜻한다.
를 세 번 곱해야 이 나오므로 이다.
예제 2
은 로 표현할 수 있다.
를 번 곱해야 가 나오므로, 이다.
위의 방식으로 이해가 어렵다면, 다른 방식으로도 설명할 수 있다.
예제 3
은 이 될 때까지 을 계속해서 로 나눌 때 등식에 얼마나 많은 가 등장할까?
그 결과는 이다.
다시 말하면, 이 이 될 때까지 로 번을 나눠야하므로, 이다.
예제 4
그렇다면 의 결과는 어떨까?
가 개이므로 이다.
3.5 O(log N) 해석
그렇다면 컴퓨터 과학에서 은 사실 )을 줄여 부르는 말이라고 할 수 있다.
빅 오 표기법이 데이터가 개일 때 알고리즘에 필요한 (최악의) 단계 수를 계산하는 것이라고 했을 때, 은 데이터가 개일 때 단계가 소요된다는 의미이다. 만약 원소가 64개라면 이므로 이 알고리즘은 6단계가 걸린다.
이진 검색(Binary Search)은 특정 데이터를 찾을 때까지 경우의 수를 계속 반으로 좁혀나가는 로직이므로 의 시간복잡도를 가진다고 할 수 있다. 다시 말해 원소가 하나가 될 때까지 데이터를 계속해서 반으로 줄이는 만큼의 단계 수가 소요되는 알고리즘이다.
| 원소 개수 (N) | O(N) | O(logN) |
|---|---|---|
| 2 | 2 | 1 |
| 4 | 4 | 2 |
| 8 | 8 | 3 |
| 16 | 16 | 4 |
| 32 | 32 | 5 |
| 64 | 64 | 6 |
| 128 | 128 | 7 |
| 256 | 256 | 8 |
| 512 | 512 | 9 |
| 1024 | 1024 | 10 |
알고리즘에서 데이터의 수만큼 단계가 필요한 반면, 알고리즘에서는 데이터가 2배로 늘어날 때마다 1단계씩 추가된다.
3.6 실전 예제
리스트 내 모든 항목 출력
const fruits = ['apple', 'banana', 'cherry', 'durian'];
for (const fruit of fruits) {
console.log(fruit);
}위 예제는 for 루프를 통해 배열 fruits 내 모든 데이터를 한 번씩 출력한다. fruits 배열에는 4개의 데이터가 들어있기 때문에 총 4단계가 소요되지만, 만약 배열 내 데이터가 개라면 for 루프는 번 실행되므로 위 예제 알고리즘의 시간 복잡도는 이다.
소수 판별
function isPrime(num) {
for (let i = 2; i <= num; i++) {
if (num % i === 0) return false;
}
return true;
}위 예제는 가장 간단히 구현한 소수 판별 알고리즘이다. num을 인수로 받아 2부터 num까지 나누어 나머지를 체크하고, 나머지가 없으면 (즉 나누어 떨어지면!) 해당 수는 소수가 아니므로 false를 리턴한다.
이 경우에는 알고리즘 소요 단계를 측정할 때 num을 대상으로 함수 루프 실행 횟수를 체크하므로, 인수에 을 전달할 때 몇 단계가 소요되는지 알아보면 된다.
함수에 숫자 7을 전달할 경우 for 루프는 7단계를 실행하므로 위 예제 알고리즘의 시간복잡도는 이다. (실제로는 2에서 시작해 number에서 끝나므로 6단계 소요)
실습
- 주어진 해가 윤년인지 밝히는 다음 함수의 시간 복잡도는?
function isLeapYear(year) {
return year % 100 === 0 ? year % 400 === 0 : year % 4 === 0
}정답 :
함수에 전달된 인자(year)를 이라고 할 때, 의 크기에 상관없이 1단계가 소요된다.
- 주어진 배열의 모든 수를 합하는 다음 함수의 시간 복잡도는?
function getSumArray(arr) {
let sum = 0;
for (let i = 0; i < arr.length; i++) {
sum += arr[i];
}
return sum;
}정답 :
함수에 전달된 인자(arr)를 이라고 할 때, for 루프는 의 데이터 수만큼 실행된다.
- 체스판 한 칸에 쌀 한 톨을 놓고, 두 번째 칸에는 이전 칸에 놓았던 쌀의 양보다 두 배 더 많은 쌀을 놓을 때, 몇 번째 칸에 일정한 수의 쌀을 놓아야 하는지 계산하는 함수이다. 가령 쌀이 열여섯 톨이면 다섯 번째 칸에 놓아야 하므로 함수는 5를 값으로 반환한다. 이 함수의 시간 복잡도는?
function chessBoard(grains) {
let space = 1;
let placed = 1;
while (placed < grains) {
placed *= 2;
space += 1;
}
return space;
}정답 :
이 2배 늘어날 때마다 루프는 1번 더 실행된다.
- 문자열 배열을 인자로 받는 함수에서 "x"로 시작하는 문자열만 포함시킨 새 배열을 반환하는 알고리즘의 시간 복잡도는?
function startAStrings(arr) {
let A_arr = [];
for (let i = 0; i < arr.length; i++) {
if (arr[i].startsWith("x")) A_arr.push(arr[i]);
}
return A_arr;
}정답 :
함수에 전달된 인자(arr)를 이라고 할 때, for 루프는 의 데이터 수만큼 실행된다.
- 정렬된 배열의 중앙값을 계산하는 함수의 시간 복잡도는?
function getMiddleData(arr) {
const mid = Math.floor(arr.length / 2);
if (arr.length % 2 === 0) {
return (arr[mid - 1] + arr[mid]) / 2;
} else {
return arr[mid];
}
}정답 :
함수에 전달된 인자(arr)를 이라고 할 때, 의 데이터 수에 상관없이 매번 같은 단계의 수만큼 실행된다.
요약
- 빅 오 표기법은 알고리즘의 시간 복잡도를 나타내며, 알고리즘이 해당 차수이거나 그보다 낮은 차수의 시간복잡도를 가지고 있다는 의미이다. 즉 알고리즘의 '최악 실행 시간'을 표기한다.
- 빅 오의 본질은 데이터가 늘어날 때 알고리즘의 성능이 어떻게 바뀌는지를 뜻한다. 데이터가 늘어날 때 단계 수가 어떻게 증가하는지를 설명하는 것이다.
- 로그(log)는 로가리즘(logarithm)의 줄임말이며, 로가리즘은 지수(exponent)와 역(inverse)의 관계이다.
- 은 로그 시간(log time) 복잡도이며, 데이터가 두 배로 증가할 때 마다 한 단계씩 늘어나는 알고리즘을 로 표현하고, "오 로그 N"이라고 말한다. 즉 데이터가 개일 때 단계가 소요된다는 의미이다.
