
들어가기 전에
데이터를 알파벳 순서나 낮은 가격 등의 특정 순서로 정리하고 싶을 수 있다.
퀵 정렬은 데이터를 완벽하게 오름차순으로 정리할 수 있지만 비용이 든다.
정렬 알고리즘은 아무리 빨라도 의 시간이 걸리기 때문에 데이터를 자주 정렬해야 할 때는 다시 정렬하는 일이 없도록 애초에 항상 정렬된 순서를 유지하는 것이 합리적이다.
정렬된 배열은 순서대로 데이터를 유지하는 간단하면서 효과적인 도구이며,
특정 연산에 매우 빠르기 때문에 읽기에서는 , 검색(이진 검색)에서는 의 시간이 소요된다.
하지만 한 가지 문제가 존재하는데, 정ㄹ려된 배열에서 삽입과 삭제가 상대적으로 느리다는 점이다.
정렬된 배열에 값을 삽입할 때마다 먼저 더 큰 값을 전부 할 셀 오른쪽으로 시프트해야 한다.
또한 값을 삭제할 때마다 더 큰 값을 전부 한 셀 왼쪽으로 시프트해야 한다.
최악의 시나리오 경우 단계, 평균적으로는 단계가 소요된다.
전반적으로 빠른 속도의 자료구조를 원한다면 해시 테이블이 좋다.
해시 테이블은 검색, 삽입, 삭제가 모두 이다. 하지만 순서를 유지하지 못한다
그렇다면 순서를 유지하면서도 빠른 검색, 삽입, 삭제가 가능한 자료구조가 필요할 때는 어떻게 해야 할까?
15.1 트리
트리(tree)란?
노드들이 나무 가지처럼 연결된 비선형 계층적 자료구조로 그래프의 일종
한 노드에서 시작해 다른 정점들을 순회하여 자기 자신에게 돌아오는 순환이 없는 연결 그래프
14장에서는 연결 리스트라는 노드 기반 자료 구조를 알아봤다.
전형적인 연결 리스트는 각 노드마다 그 노드와 다른 한 노드를 연결하는 링크를 포함한다.
트리(tree) 역시 노드 기반의 자료구조지만, 각 노드는 여러 노드로의 링크를 포함할 수 있다.
트리 용어
- 루트(root) : 최상위 노드
- 부모(parent) : 연결된 한 단계 상위 노드
- 자손(descendant) : 한 노드에서 생겨난 모든 노드
- 조상(ancestor) : 자손을 생겨나게 한 모든 노드
- 레벨(level) : 트리에서 같은 줄(row)
- 프로퍼티(property) : 균형잡힌 정도
- 모든 노드에서 하위 트리 노드 개수가 같으면 균형 트리
- 모든 노드에서 하위 트리 노드 개수가 다르면 불균형 트리
15.2 이진 탐색 트리
이진 탐색 트리(Binary Search Tree)란?
이진 트리 기반의 탐색을 위한 자료 구조
이진 트리는 각 노드에 자식이 2개 이하인 트리이며, 이진 탐색 트리는 아래 규칙이 추가된다.
- 각 노드의 자식은 최대 '왼쪽'에 하나, '오른쪽'에 하나
- 한 노드의 '왼쪽' 자손은 그 노드보다 작은 값만 포함할 수 있다.
- 한 노드의 '오른쪽' 자손은 그 노드보다 큰 값만 포함할 수 있다.
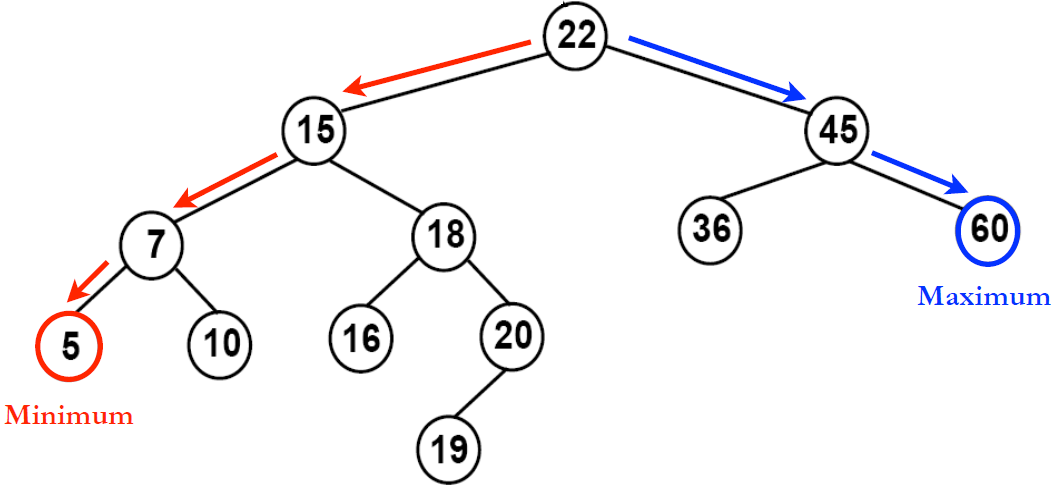
이진 탐색 트리는 각 노드마다 해당 노드보다 작은 값을 가지는 자식 노드 하나(왼쪽 화살표), 큰 값을 가지는 노드 하나(오른쪽 화살표)가 있다. 그리고 루트 노드의 왼쪽 자손은 전부 루트보다 작고, 오른쪽 자손은 전부 루트보다 크다. 이 패턴이 모든 노드에서 반복된다.
하나의 트리 노드를 자바스크립트로 구현하면 다음과 같다.
코드로 구현한다면: 하나의 트리 노드
기본 코드
class TreeNode {
constructor(value, left = null, right = null) {
this.value = value;
this.leftChild = left;
this.rightChild = right;
}
}
테스트
const node1 = new TreeNode(25);
const node2 = new TreeNode(75);
const root = new TreeNode(50, node1, node2);15.3 검색
이진 탐색 트리를 검색하는 알고리즘은 아래와 같다.
- 노드를 '현재 노드'로 지정한다. (처음 시작할 때는 루트 노드가 현재 노드!)
- 현재 노드의 값을 확인한다.
- 찾고 있는 값이면 좋다!
- 찾고 있는 값이 현재 노드보다 작으면 왼쪽 하위 트리를 검색한다.
- 찾고 있는 값이 현재 노드보다 크면 오른쪽 하위 트리를 검색한다.
- 찾고 있는 값을 찾았거나 트리 바닥에 닿을 때까지 1~5단계를 반복한다.
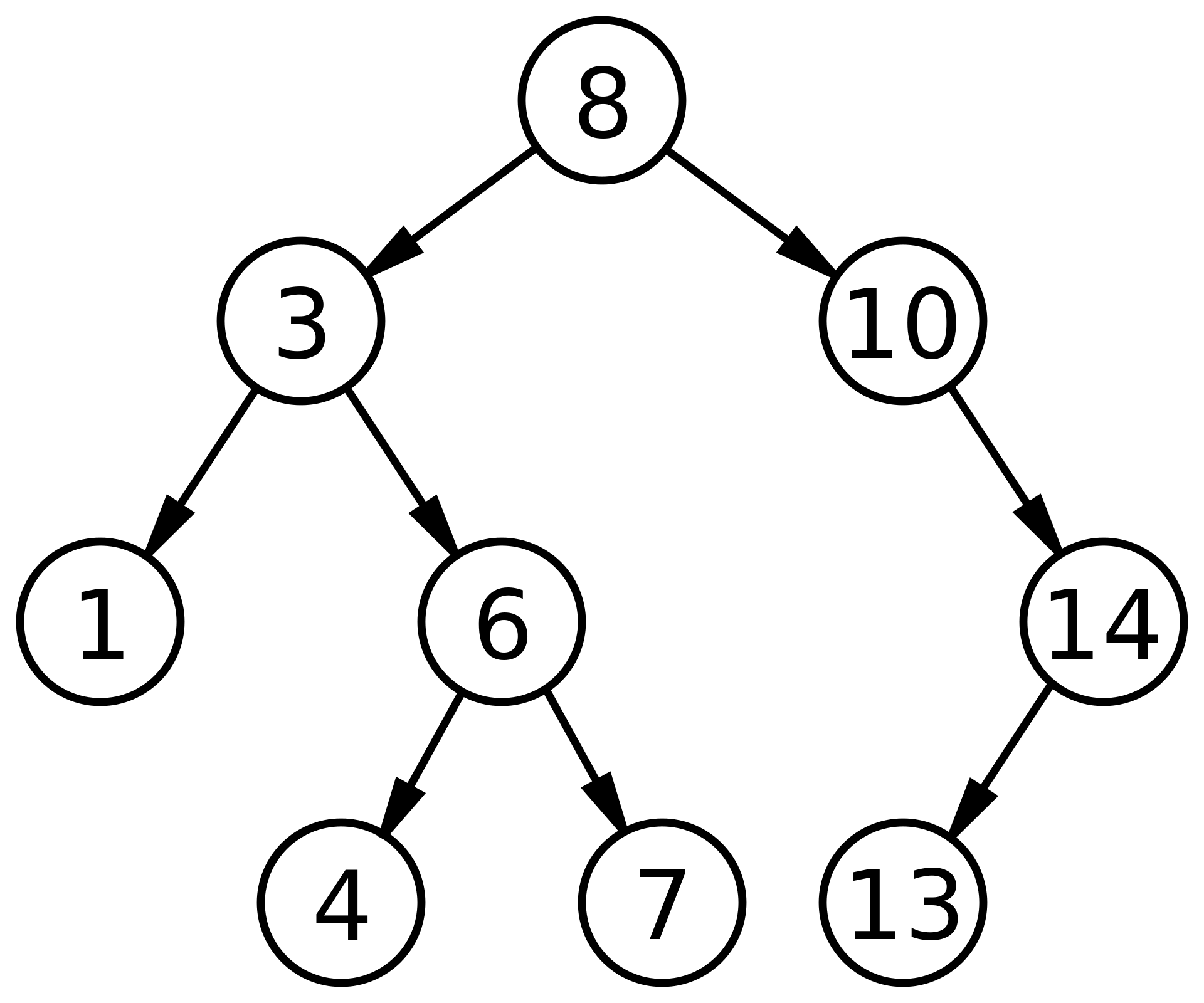
위 트리에서 7을 찾기 위해서는 가장 먼저 루트부터 시작한다.
현재 노드 : 8(root)
그 다음 검색하고 있는 수가 해당 노드보다 큰지 작은지를 체크하는데,
7은 현재 노드이자 루트인 8보다 작으므로 왼쪽 자손 노드에서 찾는다.
현재 노드 : 3
다시 현재 노드에서 찾고 있는 수를 비교한다. 7은 3보다 크므로 오른쪽 자손 노드에서 찾는다.
현재 노드 : 6
다시 현재 노드에서 찾고 있는 수를 비교한다. 7은 6보다 크므로 오른쪽 자손 노드에서 찾는다.
현재 노드 : 7
찾았다!
이진 탐색 트리 검색의 효율성
방금 검색했던 단계를 조금 다른 시각에서 바라보면 각 단계마다 검색할 대상이 남은 노드의 절반으로 줄어든다. 예를 들어 처음 루트 노드에서 검색을 시작할 대 찾고 있는 값은 루트의 자손 중 하나였다. 하지만 루트의 왼쪽 자식 노드를 검색하기로 결정하는 순간 오른쪽 자식 노드와 그 자식의 모든 자손 노드는 검색에서 제외된다.
따라서 이진 탐색 트리의 검색은 각 단계마다 남은 값 중 절반을 제거하는 모든 알고리즘을 나타내는 이다.
log(N) 레벨
이진 탐색 트리 검색이 왜 인지 다른 방식으로 설명해보자.
이 설명을 통해 균형 이진 트리에 노드가 개일 경우, 레벨이 약 개라는 이진 트리의 일반적 속성이 밝혀진다.
이해를 돕기 위해 트리의 모든 줄이 노드로 완전히 채워져 있고 빈 노드가 없다고 가정하자.
이렇게 가정할 경우 가득 채운 새 레벨을 트리에 추가할 때마다 트리의 노드개수가 대략 두 배로늘어난다.
예를 들어, 레벨이 4인 이진 트리가 완전히 채워져 있을 때 노드는 15개다.
다섯 번째 레벨을 가득 채워 추가하면 네 번째 레벨에 있는 8개 노드에 각각 자식 노드가 2개씩 추가된다.
즉, 16개의 노드가 새로 추가되면서 트리의 크기가 약 2배로 늘어난다.
이렇듯 레벨을 새로 추가할 때마다 트리의 크기가 2배가 된다.
따라서 노드가 개인 트리에서 모든 자리마다 노드를 두려면 레벨이 레벨이 필요하다.
이렇게 생각하면 이진 탐색 트리 검색에 왜 최대 단계가 소요되는지 충분히 이해할 수 있다. 각 검색 단계마다 레벨을 하나씩 내려가면서 레벨 수 만큼 들어가기 때문이다. 어떤 방식으로 생각하던지 이진 탐색 트리 검색에는 이 걸린다.
배열의 이진 검색도 마찬가지다. 남은 값 중 절반을 제거한다.
이러한 면에서 이진 탐색 트리의 검색은 정렬된 배열의 이진 검색과 효율성이 같다.
하지만 삽입에서는 정렬된 배열보다 이진 트리가 훨씬 뛰어나다.
코드로 구현한다면: 이진 탐색 트리의 검색
검색 뿐 아니라 앞으로 다른 이진 탐색 트리의 연산을 구현할 때도 재귀를 많이 활용할 것이다.
10장-재귀를 사용한 재귀적 반복에서 본 것 처럼 재귀는 임의 깊이만큼 들어가야 하는 자료구조를 다룰 때 꼭 필요하다. 레벨이 무한한 트리가 여기에 해당된다.
function search(searchValue, node) {
if (!node || node.value === searchValue) {
return node;
} else if (searchValue < node.value) {
return search(searchValue, node.leftChild);
} else {
return search(searchValue, node.rightChild);
}
}
15.4 삽입
15.5 삭제
15.6 이진 탐색 트리 다뤄보기
15.7 이진 탐색 트리 순회
실습
요약
