
데이터 모델
- 데이터를 어떻게 표현할 것인가? 리스트? 트리? 그래프?
- 묘사하기 위한 도구들의 집합 (데이터, 데이터 관계, 데이터 제약 조건 등)
- DBMS마다 데이터 모델이 다를 수 있으나, 실제로는 대부분
관계형 데이터 모델
주요 데이터 모델
- 관계형 데이터 모델 (Relational Data Model)
- 엔티티-관계형 데이터 모델: 데이터베이스 설계에 주로 이용
- 객체지향 데이터 모델
- RDBMS 한계 극복 위해 제안
- 현재 대부분의 RDBMS는 실질적으로 ORDBMS (관계형 + 객체지향)
- 네트워크 모델, 계층형 모델 등은 RDBMS 이전에 주로 사용된 모델
관계형 데이터 모델
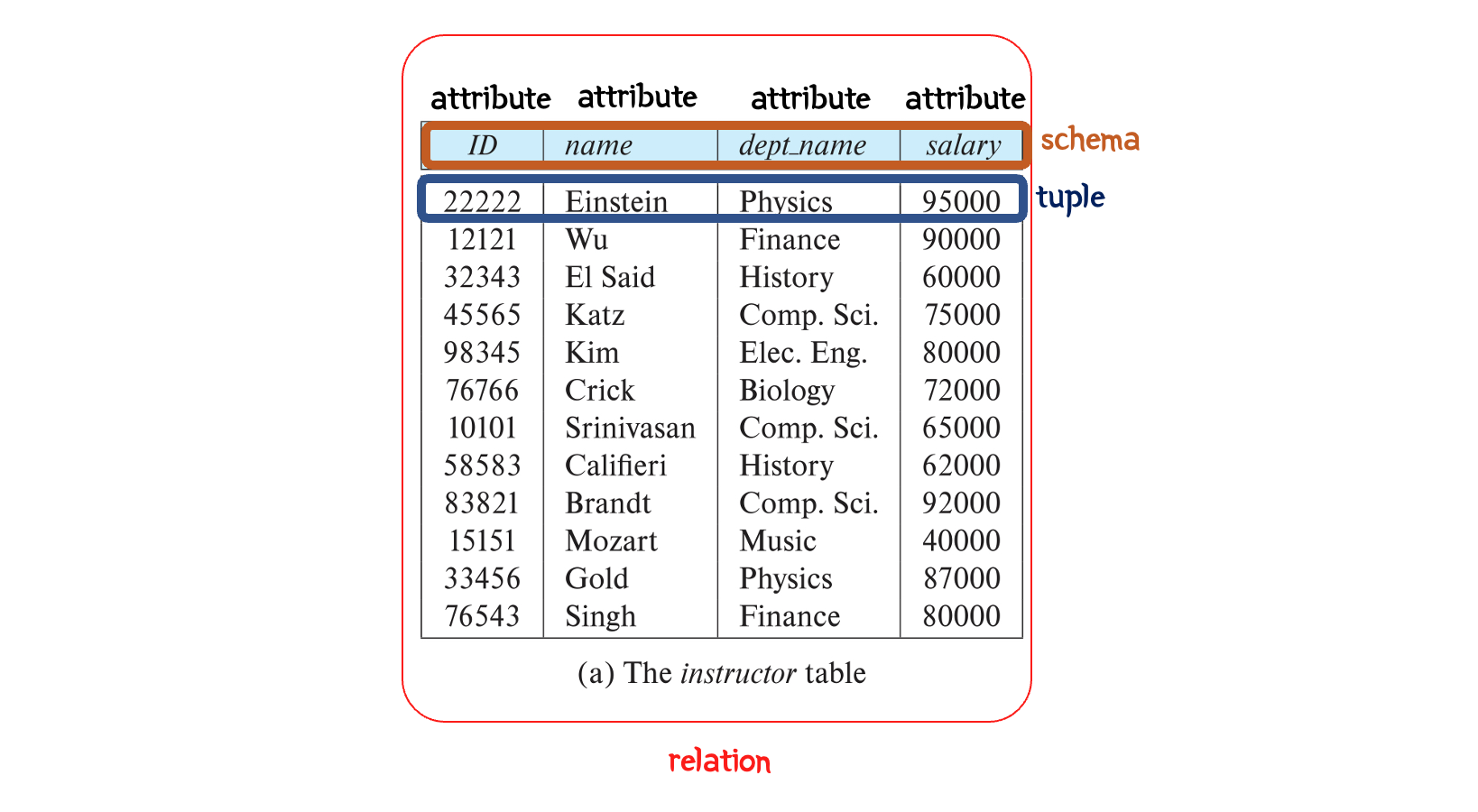
- 가장 널리 이용되는 대표적인 데이터 모델
- Relation(table)에 기반한 모델이라 사용이 편리하며 성능이 우수하다.
- Oracle, IBM DB2, MS-SQL Server 등 대부분의 DBMS가 RDBMS이다.
- SQL을 제공한다.
주요 개념
Domain: 각각의Attribute가 가질 수 있는 값의 집합 (ex: 나이는 모든 자연수)- 모든 Domain은
NULL을 포함한다.
- 모든 Domain은
Attribute(column): 하나의 열Tuple(row): 하나의 행, 열이 모여 하나의 객체를 표현Relation:Tuple들의 집합Database: 여러Relation들의 집합
스키마
- 데이터베이스의 논리적 구조 (뼈대)
- 프로그램에서의 변수의 타입과 유사
- 자주 변경되지 않는 것을 권장
논리적 스키마
logical level에서 이뤄지는 데이터베이스의 디자인- 프로그래머에게 가장 중요한 성질
물리적 스키마
physical level에서 이뤄지는 데이터베이스의 디자인- 논리적 스키마 아래에 숨겨질 수 있으며, 애플리케이션 프로그램에 영향 없이 쉽게 변경될 수 있다.
인스턴스
- 특정 시점에 데이터베이스에 들어있는 실제 내용
- 프로그램에서의 변수와 유사
키
키는 Tuple을 구별하기 위한 Attribute의 집합을 뜻한다.
Relation은 완전히 동일한 Tuple이 있을 수 없다.
Super key
- Relation에서 Tuple을 식별할 수 있는 unique한 Attribute의 집합
Candidate key
- Super key 중 minimal한 키
- 하나의 Attribute라도 빼면 더 이상 키가 될 수 없음
- 여러 개로 구성될 수도 있다.
Primary key
- Candidate key 중 하나 (Relation을 정의할 때 선택)
Entity Integrity: NULL이 될 수 없다.- 여러 Candidate key가 모여 PK가 될 수도 있다.
Foreign key
- 다른 Relation을 참조하는 Attribute
- 참조하는 Relation에서 Key는 아닐 수 있지만, 참조되는 Relation에서 Primary key이다.
Referential Integrity: 반드시 참조된 Relation의 PK 값에 존재하거나, NULL이어야 함- 여러 FK가 모여 PK가 될 수도 있다.
키 구분 예시
예를 들어 다음과 같은 Relation을 설계했다고 가정해보자.
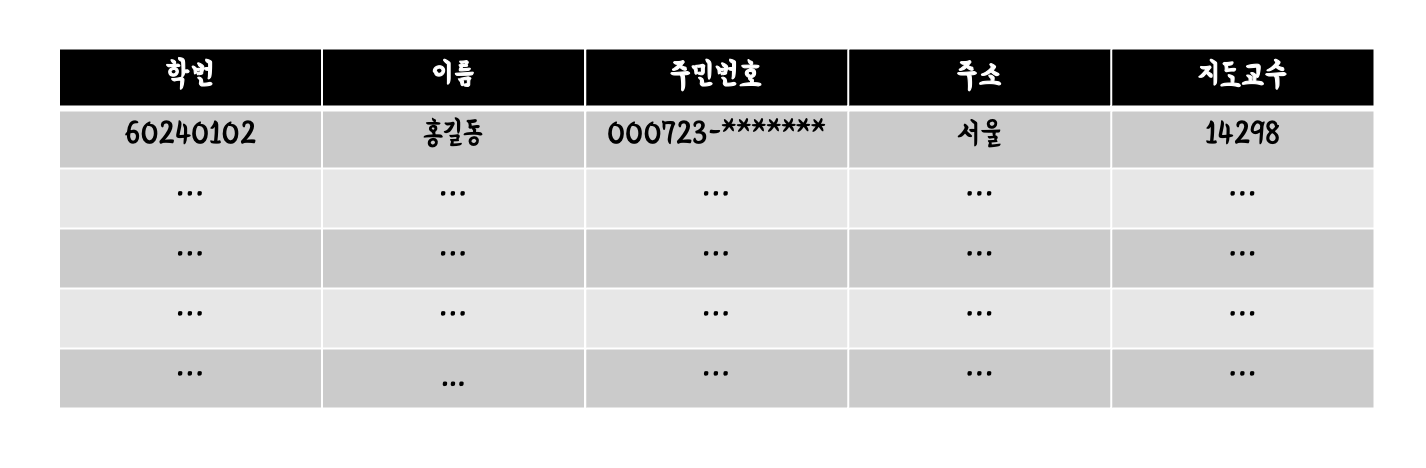
Super key (슈퍼 키)
Super key는 Relation에서 Tuple을 식별할 수 있는 unique한 Attribute의 집합을 뜻한다.
이 예시에서 보면, "학번"과 "주민번호"가 유일하게 식별할 수 있는 값이다.
즉, 어떤 집합이든 "학번" 또는 "주민번호"가 들어가있다면 그것은 Super key라고 할 수 있다.
- {"학번"}
- {"학번", "이름"}
- {"학번", "주민번호"}
- {"주민번호", "지도교수"}
- 그 외 기타
단, 다음과 같은 경우는 Super key라고 할 수 없다.
- {"이름"}
- {"이름", "지도교수"}
- {"이름", "주소"}
- 그 외 기타
위의 경우들은 Tuple을 unique하게 식별할 수 없는 값들로만 구성되어 있기 때문이다.
Candidate key (후보 키)
Candidate key는 Super key 중 minimal한 값, 즉 이것을 빼면 나머지들은 Super key가 될 수 없는 것들을 뜻한다.
언급했듯이 "학번", "주민번호"가 이에 해당한다. 두 번째 예시에서의 "학번"을 빼면 "이름"만 남게 되고, 네 번째 경우에서 "주민번호"를 빼면 "지도교수"만 남게 되어 unique하게 식별할 수 없기 때문이다.
Primary key (기본 키)
Primary key는 Candidate key 중 하나, 즉 "학번" 또는 "주민번호"가 들어올 수 있다.
Foreign key (외래 키)
Foreign key는 다른 Relation을 참조하는 Attribute이다. 즉, 위의 경우에서는 "지도교수"가 해당할 수 있다.
엔티티 관계형 모델
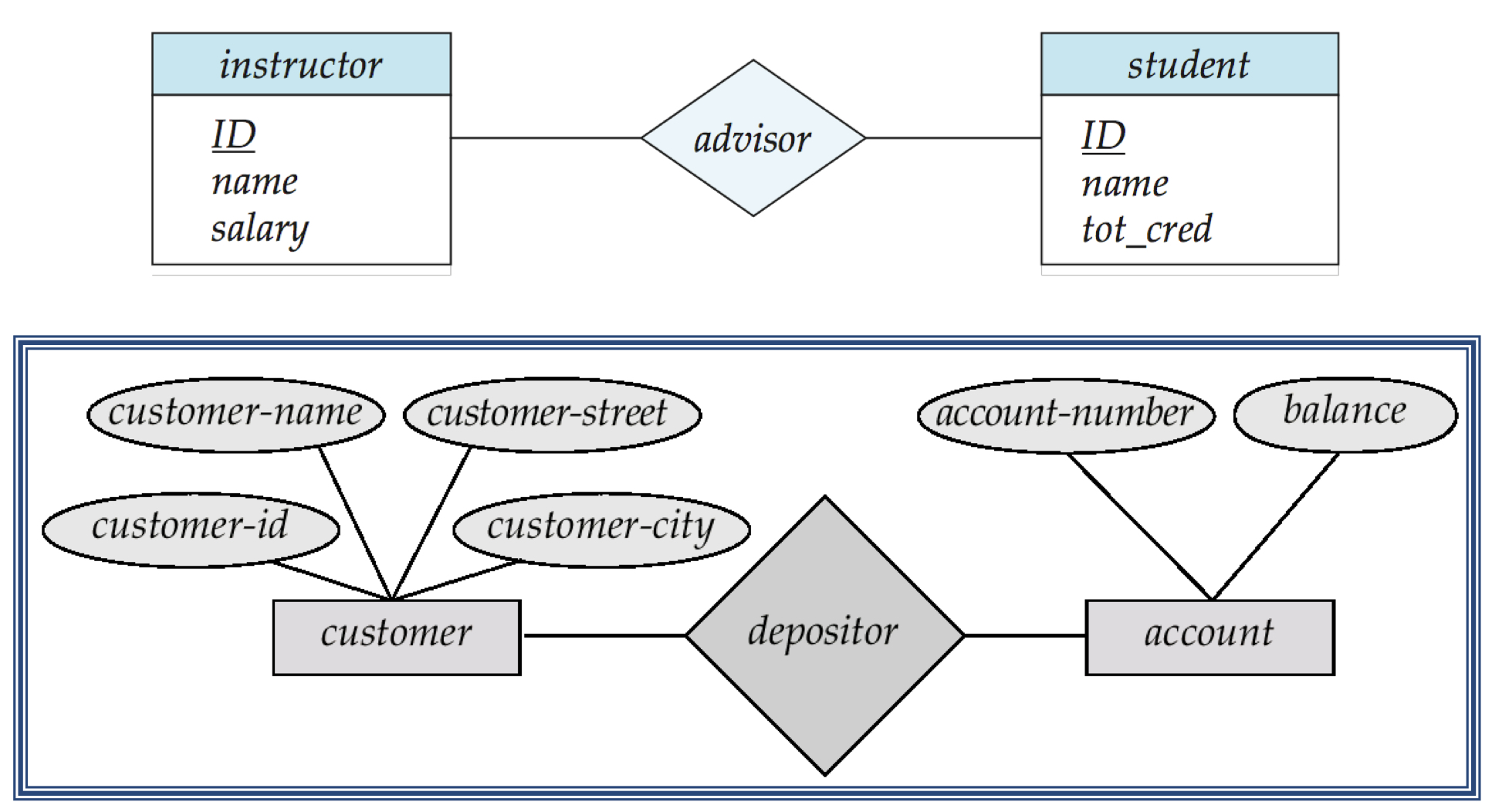
엔티티 관계형 모델은 주로 데이터베이스를 설계할 때 사용된다.
고객의 요구사항을 제대로 파악하여 스키마를 처음부터 잘 설계하기 위해 사용된다.
엔티티
- 실제 사물을 뜻한다.
- 소비자, 계좌 등
엔티티의 관계
- 소비자와 계좌를 서로 연결하는 것 등의 작업을 뜻한다.
데이터베이스 언어
데이터 정의 언어 (Data Definition Language, DDL)
- 데이터베이스의 스키마를 정의할 때 사용되는 언어
create table,drop column등이 해당된다.
데이터 조작 언어 (Data Manipulation Language, DML)
- 데이터베이스의 데이터를 조작 (스키마는 불변)하는 언어
Retrieve (Read),Insert,Delete,Change(CRUD) 등이 해당된다.
데이터 제어 언어 (Data Control Language, DCL)
- 데이터베이스의 제약 조건을 정의하는 언어 (무결성 보장 등)
트랜잭션을 제어하는 명령어, 데이터 접근 권한을 제어하는 명령어 등이 해당된다.
절차적 vs 비절차적
- 절차적: 데이터가 어떤 것이 필요하며 그것들을 어떻게 얻을 수 있을지 기술
- ex: 관계대수 (Relational Algebra)
- 대부분의 프로그래밍 방식
- 비절차적 (선언적): 필요한 데이터가 무엇인지만 기술
- ex: 관계해석 (Relational Calculus), SQL
- 사람의 직관에 가까움
쿼리
- 정보를 추출하기 위한 선언문
- 쿼리 언어는 DML의 한 종류
- 질의
SQL
- 가장 많이 쓰이는 선언적 언어
- ex:
customer의id가192-83-7465이면서customer의name을 추출 ⬇️select customer.customer-name from customer where customer.custmer-id = '192.83.7465'
- ex:
- SQL은
Turing machine equivalent language(계산적인 문제를 풀 수 있는 언어)가 아니다!- 복잡한 형태의 기능을 구현하고 싶다면 고수준의 언어에 embedded 되어서 사용된다. (ODBC/JDBC)
- 애플리케이션 프로그램들은 embedded된 SQL이 들어있는 언어를 통해 데이터베이스에 접근한다.
데이터베이스 디자인
일반적인 데이터베이스의 구조를 디자인하는 과정은 논리적 디자인과 물리적 디자인으로 구분된다.
논리적 디자인
- 데이터베이스의 스키마를 결정
- 데이터베이스 디자인은 우리가 좋은 관계형 스키마의 집합을 찾도록 요구한다.
- 비즈니스적 결정: 우리가 어떤 속성(Attribute)들을 데이터베이스에 기록해야 하는가?
- 컴퓨터과학적 결정: 어떤 관계형 스키마를 가져야 하고 속성은 다양한 관계 스키마 사이에 어떻게 분배되어야 하는가?
물리적 디자인
- 데이터베이스의 물리적 레이아웃을 결정
잘못된 설계 예시
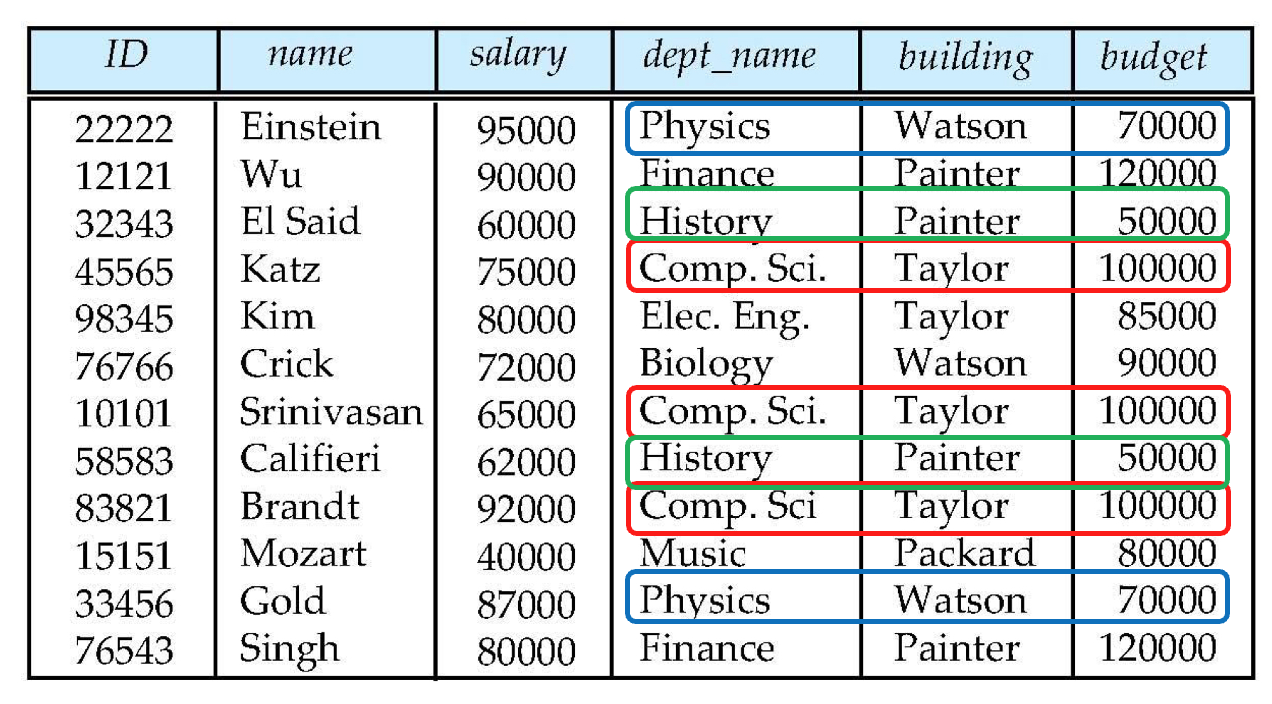
위의 그림의 경우, 잘못된 데이터베이스를 설계한 경우이다.
데이터베이스는 의미있는 데이터들의 집합이다. 그런데 지금 박스친 것들을 보면, 데이터의 중복성이 드러난다.
이는 두 개의 Relation을 억지로 한 개의 테이블로 합쳤기에 발생한 문제이다.
만약 Comp.Sci. / Taylor / 100000의 정보를 수정하고 싶다면 어떻게 해야 할까? 자칫하다가는 나머지 row의 정보는 수정되지 않은 상태가 되어 어떤 것이 정확한 것인지 모르는, 즉 의미없는 데이터로 전락하기 쉽지 않을까? 만약 이렇게 중복된 값이 매우 많아진다면?
그렇기에 데이터베이스에는 서로 중복된 값이 없도록 하는 것이 중요하다. (그리고 중복될수록 저장 공간 낭비도 심해진다.)
또, 만약 새로운 부서(dept)를 추가한다고 했을 때, 처음에는 교수가 배정되지 않으므로 name, salary는 NULL이 될 수 밖에 없다. 교수를 무조건 처음부터 배치한다면? 그것은 현실의 제약 조건을 데이터베이스가 반영하지 못해 타협하게 됨을 의미한다.
권장 방법
데이터베이스를 잘 설계 (디자인)하는 방법은 다음과 같은 방법들이 있다.
엔티티 관계형 모델
- 기업을 엔티티 (개체)와 관계의 모음으로 모델링
- 엔티티 관계형 다이어그램으로 그래픽적으로 표현된다.
정규화 이론
- 나쁜 디자인을 형식화하고 그에 대해 테스트하는 방법
DBMS 아키텍처
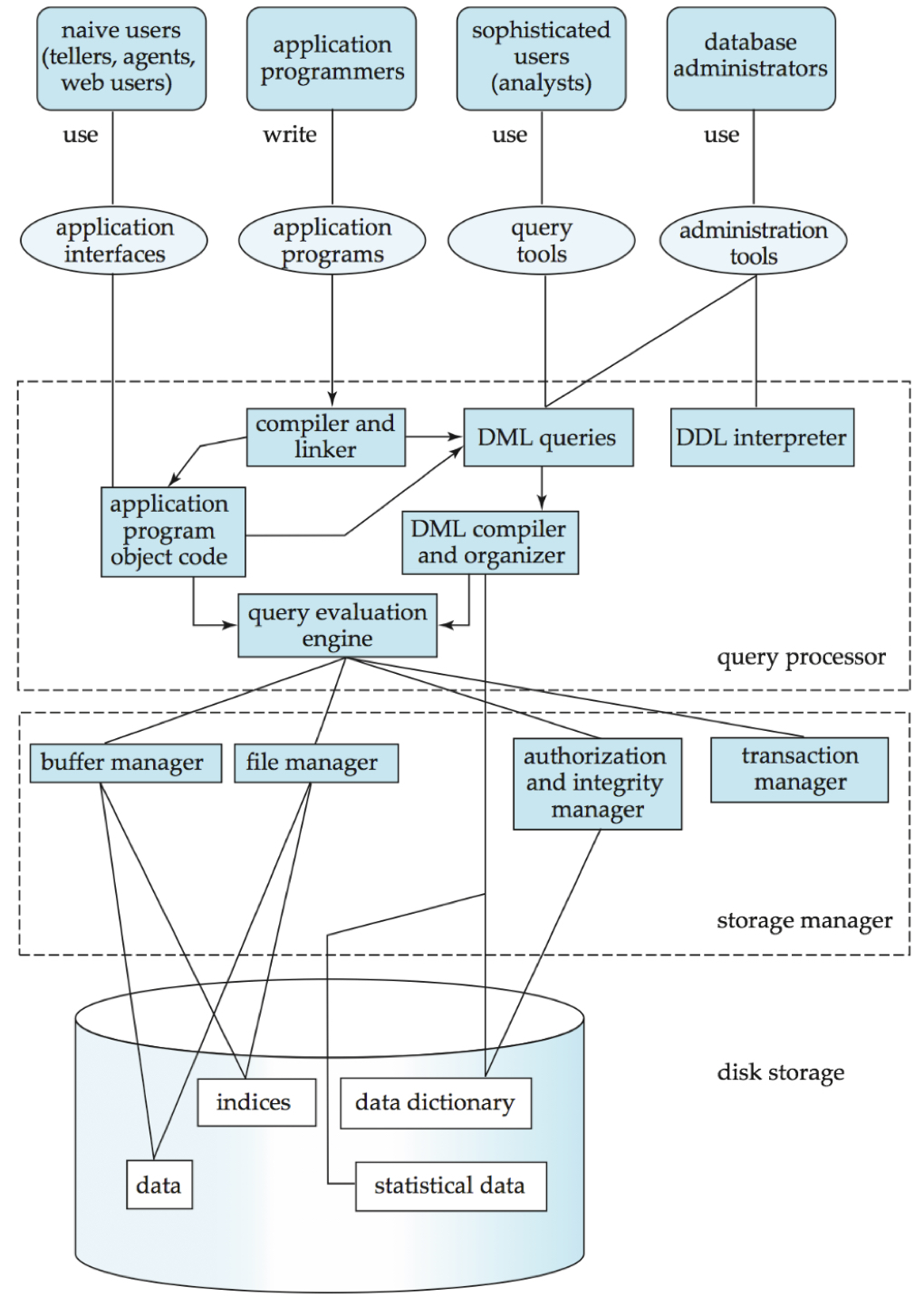
- DBMS 아키텍처는 위와 같이 복잡한 과정을 가진다.
- 위와 관련된 기술은 이미 많은 시간에 걸쳐 완성된 기술이기 때문에, 이를 직접 구현하진 않는다.
저장 관리 (Storage management)
- 데이터 저장, 접근, 파일 구조 설계, 인덱싱 처리와 같은 작업을 한다.
- OS 파일 관리자와 상호작용한다.
- 효율적인 저장, 추출, 데이터 수정 등을 한다.
- low-level의 데이터베이스에 보관된 데이터와 애플리케이션 유저가 시스템에 제출한 질의를 연결시켜주는 인터페이스를 제공한다.
쿼리 처리 (Query processing)
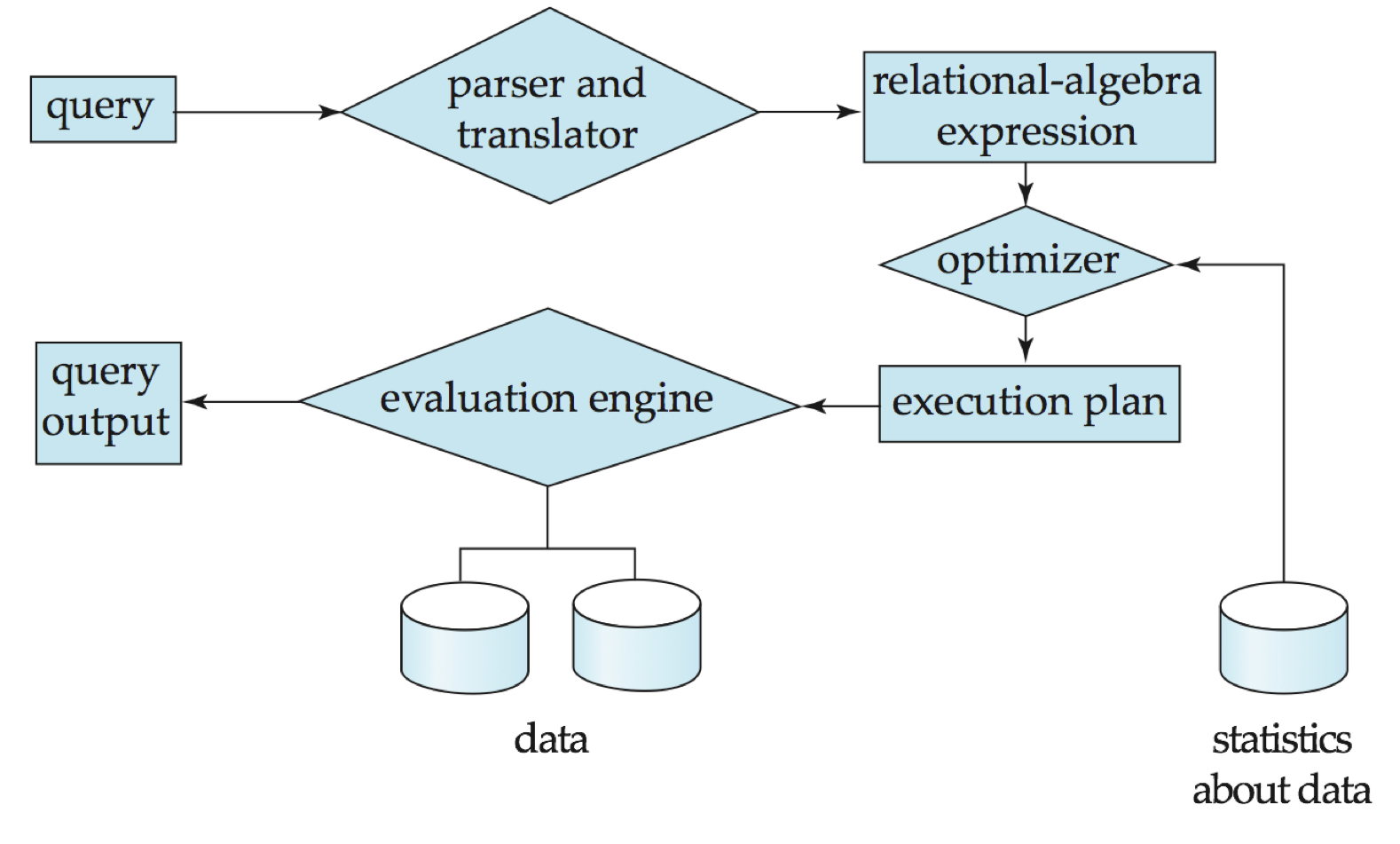
- SQL 파싱, Relational Algebra로 변형, 최적화 하는 등의 작업을 한다.
트랜잭션 관리 (Transaction management)
트랜잭션: 데이터베이스 애플리케이션에서 논리적으로 하나의 기능을 하는 연산들의 집합- 프로그래머는 정확한 트랜잭션을 작성할 책임이 있다.
- DBMS는 각 트랜잭션마다
ACID를 보장해야 한다.Atomicity(원자성): 트랜잭션 내에서 실행한 작업들은 마치 하나의 작업인 것 처럼 모두 성공하거나 모두 실패해야 한다.Consistency(일관성): 모든 트랜잭션은 일관성 있는 데이터베이스 상태를 유지해야 한다.Isolation(격리성): 동시에 실행되는 트랜잭션들이 서로에게 영향을 미치지 않도록 격리해야 한다. (동시에 같은 데이터를 수정하지 못하게 하는 등)Durability(지속성): 트랜잭션을 성공적으로 끝내면 그 결과를 기록해야 한다. 중간에 시스템에 문제가 발생해도 데이터베이스 로그 등을 사용하여 성공한 트랜잭션 내용을 복구해야 한다.
온라인 트랜잭션 처리 (On-Line Transaction Processing)
온라인 트랜잭션 처리 (OLTP)는 트랜잭션 지향 애플리케이션을 손쉽게 관리할 수 있도록 도와주기 위해 나온 방법이다.
OLAP (On-Line Analytical Processing)
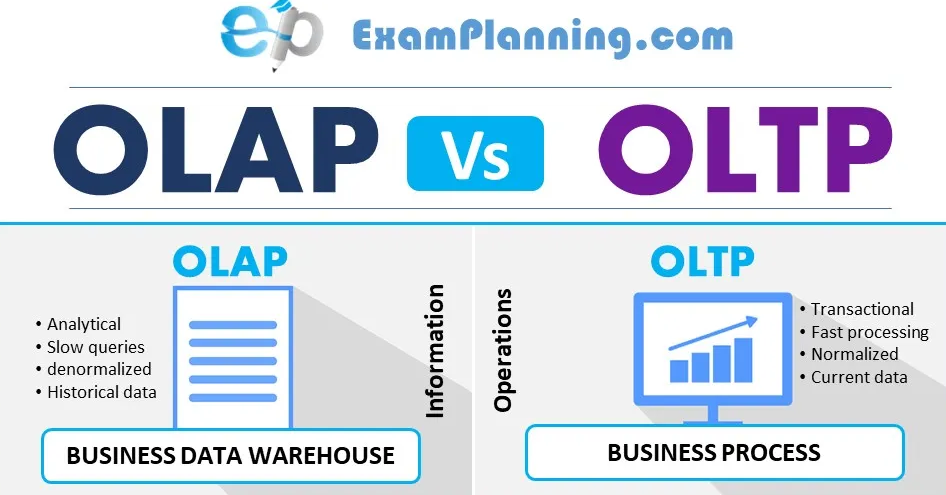
Data Warehouse(데이터 창고) 활용- 데이터들을 취합하여 한 곳에 저장, 분석 (
Data mining)
- 데이터들을 취합하여 한 곳에 저장, 분석 (
- 느린 쿼리 (slow queries)
- 데이터베이스 시스템이 처리해야 하는 데이터의 양이 많거나 복잡한 쿼리를 실행할 경우에는 성능 저하 문제가 발생할 수 있다.
- 대부분 조회 (
SELECT) 질의
- 분석적, 과거의 데이터, 역정규화
- 역정규화: 데이터를 묶거나 데이터의 복제 사본을 추가함으로써 데이터베이스의 읽기 성능을 개선하려고 시도하는 과정
- 과거의 데이터이기 때문에 변경될 일이 없음
OLTP (On-Line Transaction Processing)
- 트랜잭션: 변경될 가능성이 있으므로 트랜잭션 처리가 필요
- 빠른 처리
- 정규화
- 데이터베이스 설계 과정에서 중복을 제거하고 데이터를 구조화하는 기술
- 현재의 데이터: 데이터 변경 가능성 있음
