
속성 타입
- 각 relation의 속성(attribute)은 이름을 가진다.
- 허용된 값들의 집합을
도메인이라고 한다. - 속성 값들은 일반적으로 원자성을 요구받는다.
- 많은 값을 가진 (multi-valued) 속성 값들은 원자적이지 않다. (전화번호 등)
- 합성된 값들 또한 원자적이지 않다. (이름 - 성, 이름 등)
NULL은 모든 도메인의 값으로 들어가있다.- 이것은 많은 연산의 정의에 복잡성을 야기한다. (PK는
NULL이 불가능하다.)
- 이것은 많은 연산의 정의에 복잡성을 야기한다. (PK는
관계형 스키마와 인스턴스
관계형 스키마
- , , ..., 을 속성이라고 가정하자.
- 을
관계형 스키마라고 한다. 이때 좌변을 relation, 우변을 schema (스키마)라고 한다. - 은 relation 과 그에 대한 관계형 스키마 을 의미한다.
customer(customer-name, customer-street, customer-city)와 같이 쓰인다. - 를 도메인 (속성이 가질 수 있는 값들)이라고 한다면, relation은 의 조합으로 가질 수 있는 것의 부분집합이라고 할 수 있다.
아래 예시를 보면 더 쉽게 이해할 수 있을 것이다.
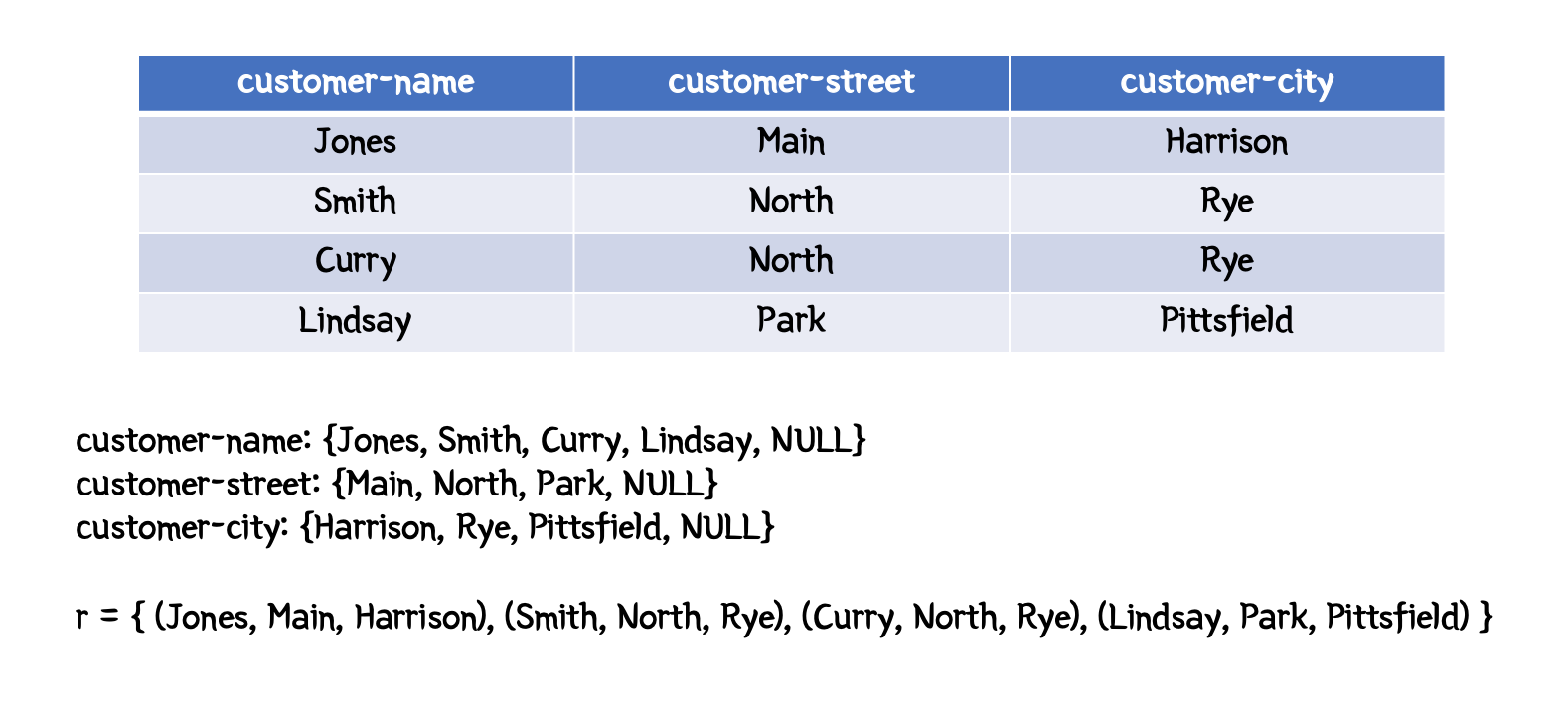
관계형 인스턴스
- 관계형 인스턴스는 현재 시점의 특정 테이블의 값들을 의미한다.
- 관계의 각 요소를 tuple이라 하며, 테이블의 한 행으로 표현된다.
- 관계들은 순서가 없다: tuple들은 임의의 순서로 저장되는 집합이다.
데이터베이스
- 데이터베이스는 많은 관계들로 구성
- 한 개념이 여러 개로 나눠질 수 있음을 알려준다. (강사 - 학생 - 교수)
나쁜 설계
- 정보의 되풀이 (두 학생이 같은 강사를 가짐)
NULL값을 필요로 함 (교수가 정해지지 않은 학생)
정규화 이론 (Normalization Theory)은 어떻게 "좋은" 관계형 스키마를 설계할 수 있을지를 다룬다
데이터베이스 스키마
- 데이터베이스 스키마 - 데이터베이스의 논리적 뼈대 (
instructor(ID, name, dept_name, salary)등) - 데이터베이스 인스턴스 - 주어진 시간에서의 데이터베이스 안에 있는 데이터의 스냅샷
키
이라고 가정해보자. (: 속성의 집합, : 스키마)
-
이때, 에 대한 값이 각 가능한 관계 의 고유 튜플을 식별하기에 충분하다면 는 의 슈퍼 키이다.
예시:{ID}와{ID, name}은 모두 강사의 슈퍼 키이다. -
슈퍼 키 는 가 minimal할 경우 후보 키가 될 수 있다.
예시:{ID}는 강사의 후보 키이다.주의할 점: minimal하다는 것은 후보 키가 하나임을 의미하지 않는다. 키가 여러 개인 집합 자체가 후보 키가 될 수도 있다. 즉, 두 개 이상의 키가 모두 있어야만 unique하게 식별 가능한 경우가 있을 수도 있다.
예시로 아래의대학 데이터베이스의 스키마 다이어그램에서prereq테이블을 보자.
prereq 테이블은 선수과목을 나타내는 것으로써, 과목-선수과목을 나타낸다.
한 과목은 여러 개의 선수과목을 가질 수 있다. 따라서course_id으로는 unique하게 식별할 수 없다.
선수 과목 또한 여러 개의 과목을 가질 수 있다. 따라서prereq_id만으로는 unique하게 식별할 수 없다.
이러한 이유에 의해, 후보 키로는{course_id, prereq_id}가 들어갈 수 있으며, Primary Key 또한{course_id, prereq_id}가 되는 것이다. 특히 "PK는 한 키만 해당할 수 있지 않나?"라고 헷갈리기 쉬운데, 후보 키 집합의 원소 중 하나가 될 수 있다 (즉, 집합도 가능하다)고 생각을 하자.
외래 키는 반드시 다른 관계에 있거나 NULL 값이어야 한다. 이때, 각 테이블에서의 속성 이름은 달라도 된다.
대학 데이터베이스의 스키마 다이어그램 ⭐️
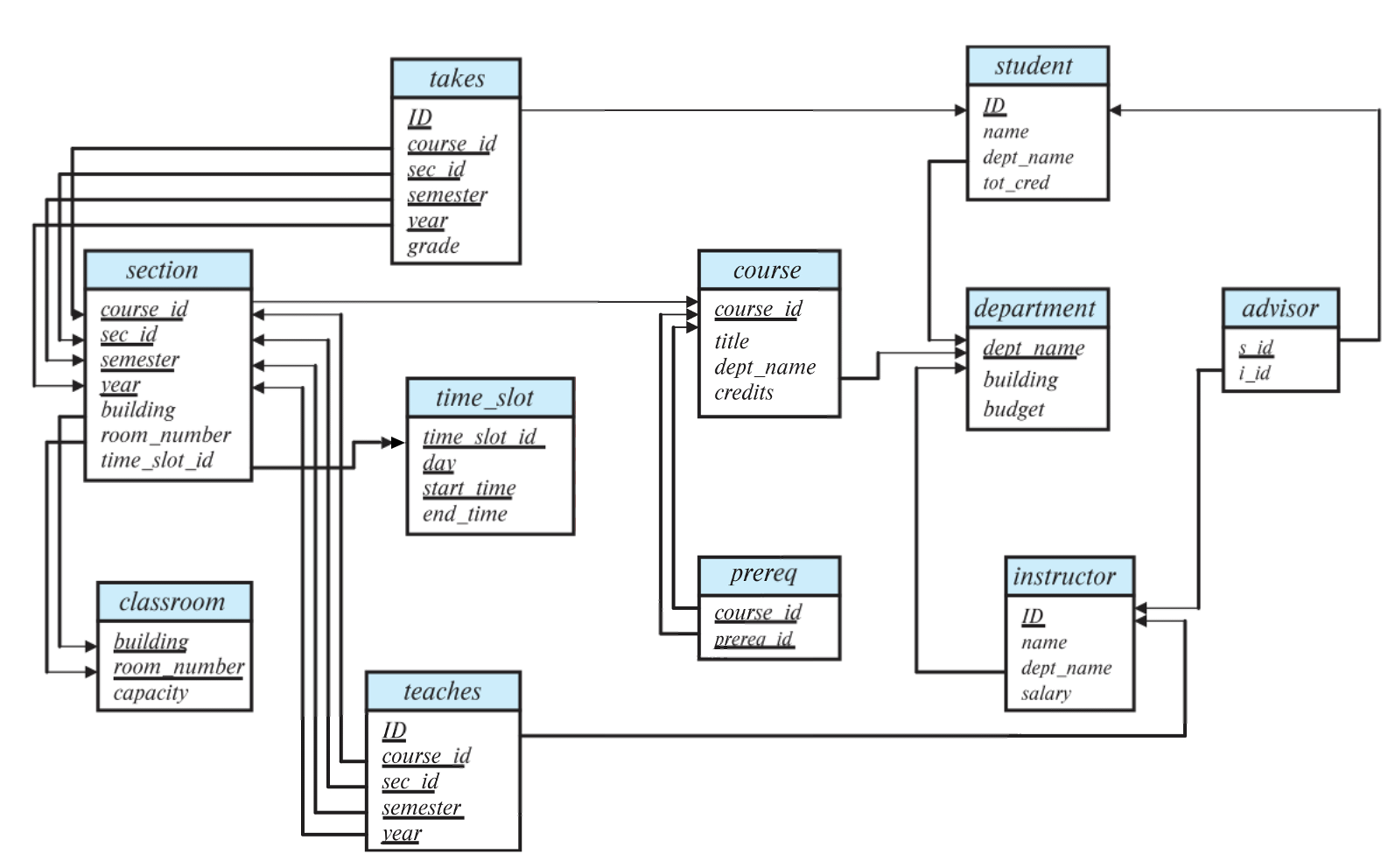
student
ID를 PK로 가진다. (NULL이 될 수 없다.)name,dept_name,tot_cred는 후보 키가 될 수 없다.dept_name은 FK이다. (NULL이거나 외부 테이블에 반드시 존재하는 값이다.)
department
dept_name을 PK로 가진다.building,budget은 후보 키가 될 수 없다.
advisor
s_id를 PK로 가진다.i_id는 후보 키가 될 수 없다.s_id와i_id는 FK이다.
instructor
ID를 PK로 가진다.name,dept_name,salary는 후보 키가 될 수 없다.dept_name은 FK이다.
course
course_id를 PK로 가진다.title,dept_name,credits는 후보 키가 될 수 없다.dept_name은 FK이다.
prereq
course_id와prereq_id모두 PK이자 FK이다.- 이처럼 FK가 모여 PK로 구성될 수 있다.
takes
ID,course_id,sec_id,semester,year는 PK이자 FK이다.grade는 후보 키가 될 수 없다.
time_slot
time_slot_id,day,start_time은 PK이다.time_slot_id는 FK이다.end_time은 후보 키가 될 수 없다.
teaches
- 모든 요소가 PK이자 FK이다.
section
course_id,sec_id,semester,year는 PK이자 FK이다.building,room_number,time_slot_id는 후보 키가 될 수 없다.building,room_number도 FK이다.
classroom
building,room_number는 PK이자 FK이다.capacity는 후보 키가 될 수 없다.
