타겟넘버
문제 요약
정수들이 들어가있는 배열 numbers와 목표 결과값인 target을 인자로 받는다. 모든 값을 더하거나 빼서 결과값이 target이 나온다면 카운팅을 하고, 해당 값을 return하면 되는 문제다.
IO
| Numbers | Target | Return |
|---|---|---|
| [1, 1, 1, 1, 1] | 3 | 5 |
| [4, 1, 2, 1] | 4 | 2 |
제한사항
- 주어지는 숫자의 개수는 2개 이상 20개 이하입니다.
- 각 숫자는 1 이상 50 이하인 자연수입니다.
- 타겟 넘버는 1 이상 1000 이하인 자연수입니다.
풀이
function solution(numbers, target) {
let answer = 0;
const stack = [{ index: 0, sum: 0 }];
while (stack.length) {
const { index, sum } = stack.pop();
if (index === numbers.length) {
if (sum === target) answer++;
continue;
}
stack.push({ index: index + 1, sum: sum + numbers[index] });
stack.push({ index: index + 1, sum: sum - numbers[index] });
}
return answer;
}
console.log(solution([4, 1, 2, 1], 4));DFS 방식을 사용했는데, Python을 사용하다 와서 그런지 다른 풀이를 참고하면서 풀었다. stack에는 index, sum 값이 들어가있고, 스택이 빌 때까지 탐색을 시작한다. 카운팅이 수행되는 조건은 index가 numbers 배열의 길이만큼 늘어나고, 합산이 target과 일치할 때이다. index는 말 그대로 인덱스의 의미도 가지고 있지만, 무조건 순차적인 탐색이라 카운팅의 의미를 갖기도 한다.
push 구문을 보면 더하는 케이스와 빼는 케이스가 있는데, index는 다음 index로 넘어가게 되면서 +1이 되고, sum은 기존 값에 numbers 배열의 해당 인덱스 값을 더하거나 빼는 과정을 수행하게 된다. 나머지 문제들에 비해 상대적으로 쉬웠던 문제였던 것 같다.
여행경로
문제 요약
tickets 배열을 받아오는데, 배열의 형태가 [['KOR', 'JPN'], ['JPN', 'USA'], ...]와 같은 형식으로 주어져있다. 인덱스의 첫 번째 값과 두 번째 값은 각 출발지와 도착지를 의미하며, 모든 항공권을 이용하여 여행경로를 짜야 한다.
IO
| Tickets | Return |
|---|---|
| [["ICN", "JFK"], ["HND", "IAD"], ["JFK", "HND"]] | ["ICN", "JFK", "HND", "IAD"] |
| [["ICN", "SFO"], ["ICN", "ATL"], ["SFO", "ATL"], ["ATL", "ICN"], ["ATL","SFO"]] | ["ICN", "ATL", "ICN", "SFO", "ATL", "SFO"] |
제한사항
- 모든 공항은 알파벳 대문자 3글자로 이루어집니다.
- 주어진 공항 수는 3개 이상 10,000개 이하입니다.
- tickets의 각 행 [a, b]는 a 공항에서 b 공항으로 가는 항공권이 있다는 의미입니다.
- 주어진 항공권은 모두 사용해야 합니다.
- 만일 가능한 경로가 2개 이상일 경우 알파벳 순서가 앞서는 경로를 return 합니다.
- 모든 도시를 방문할 수 없는 경우는 주어지지 않습니다.
풀이
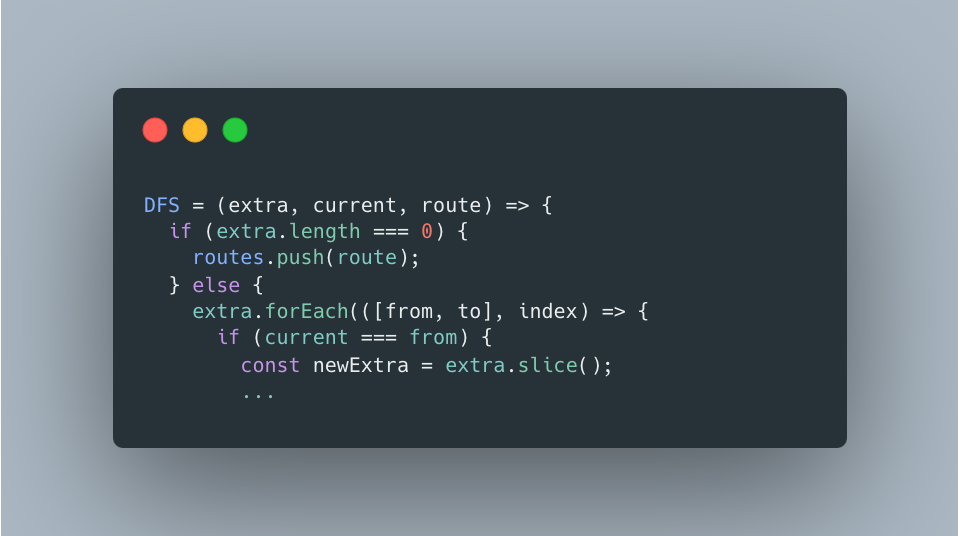
function solution(tickets) {
let routes = [];
DFS = (extra, current, route) => {
if (extra.length === 0) {
routes.push(route);
} else {
extra.forEach(([from, to], index) => {
if (current === from) {
const newExtra = extra.slice();
newExtra.splice(index, 1);
DFS(newExtra, to, route.concat(to));
}
});
}
};
DFS(tickets, "ICN", ["ICN"]);
return routes.sort()[0];
}BFS로 풀고 싶었는데, 생각대로 잘 안되었던 것도 있고 문제 자체가 좀 어려워서 외부 풀이를 참고해서 풀었다. 전반적인 DFS 구조를 보면 인자값으로 extra, current, route가 들어가는 것을 볼 수 있다. 처음에 선언하는 routes는 최종적인 경로라고 생각하면 되고, 인자로 들어가는 route는 중간에 경로를 기억할 수 있는 tmp_route 정도로 이해하면 될 것 같다.
DFS 함수가 실행되면 extra 값이 비어있는지 확인한다. 초기값은 티켓 전체가 그대로 들어가므로 바로 else문으로 들어가는데, extra에 forEach 루프를 돌려 각 인덱스 내의 출발지와 도착지에 대한 연산을 시작한다. 현위치 current에는 초기값 "ICN"이 들어가기 때문에 첫 루프에는 출발지가 ICN인 경우를 서칭하게 될 것이다. 조건을 충족하면 임시로 쓸 변수 newExtra에 extra 배열을 얕은 복사해주고 복사하는 이유는 단순 대입 연산자를 이용하여 넣어버리면 기존 배열값이 바뀌기 때문이다.
그렇게 가져온 newExtra에서 조건을 충족하는 index를 빼줌으로써 다음 서칭에는 포함되지 않도록 만들어준다. 그리고 재귀적으로 동작하도록 DFS를 호출하는데, 여기서 newExtra: extra, to: current, route.concat(to)라는 의미를 담고 있다. 첫 루프에는 route에 ICN 밖에 안들어있었는데 그 다음 목적지, 예를 들면 "JFK"가 들어가게 되는 것이다.
그렇게 나온 routes를 제한사항 5번을 참고하여 정렬해야 하는데, sort()를 활용하여 정렬을 수행하고 그렇게 정렬된 routes 배열의 첫 번째 인덱스 값을 가져오기 위해 [0]을 사용했다.
네트워크
문제 요약
지난 번에 풀었던 백준의 바이러스 와 유사한 문제이다. 인자값으로 n, computers를 받는데 n은 컴퓨터의 개수, computers는 연결 상태가 담긴 배열이다. 뭐, 예를 들어 컴퓨터가 4대라고 한다면 [[0: 1번 컴퓨터와의 연결 여부, 0: 2번 컴퓨터와의 연결 여부, 0: 3번 컴퓨터와의 연결 여부, 0: 4번 컴퓨터와의 연결 여부], [...], [...], [...] 와 같은 형태로 되는 것이다. 각 인덱스는 컴퓨터의 번호를 의미한다고 보면 되고, 그렇게 해서 컴퓨터들은 각각의 연결로 하나의 네트워크를 이루게 될 것이다. 그렇게 구성된 네트워크의 개수를 알아내면 되는 문제다.
IO
| n | computers | return |
|---|---|---|
| 3 | [[1, 1, 0], [1, 1, 0], [0, 0, 1]] | 2 |
| 3 | [[1, 1, 0], [1, 1, 1], [0, 1, 1]] | 1 |
풀이
function solution(n, computers) {
var answer = 0;
const visited = Array(n).fill(false);
DFS = (index, visited, computers) => {
visited[index] = true;
for (let i = 0; i < computers.length; i++) {
if (computers[index][i] === 1 && !visited[i]) DFS(i, visited, computers);
}
};
for (let i = 0; i < n; i++) {
if (!visited[i]) {
DFS(i, visited, computers);
answer++;
}
}
return answer;
}
console.log(
solution(3, [
[1, 1, 0],
[1, 1, 0],
[0, 0, 1],
])
); // local 확인용 콘솔DFS로 풀었는데 먼저 visited 배열은 각 컴퓨터의 방문 상태를 기록하기 위해 선언했다. 개수를 맞추기 위해 Array(n).fill(false)로 선언했고, [false, false, ... , false] 이런식으로 될 것이다. 이렇게 초기값은 다 false로 선언이 되었기 때문에 루프를 돌려서 첫 index부터 DFS 탐색을 시작한다. DFS 함수를 분석해보자.
우선 방문을 기록하기 위해 visited 배열의 해당 인덱스의 값을 true로 수정해준다. 그리고 반복문을 돌려 그 해당 인덱스와의 연결이 되어있는 경우를 찾는다. 이것이 computers[index][i]를 의미하고, 방문 여부도 !visited[i]를 통해 확인해준다. 그렇게 방문하지 않고 연결되어 있는 케이스를 찾아내면 재귀적으로 DFS를 호출한다. 그렇게 다 돌면 하나의 네트워크를 다 탐색했으므로 answer의 값을 1 증가시킨 후, 다음 네트워크를 찾게 된다.
