
Prometheus란?
Prometheus는 SoundCloud에서 만든 시스템 및 서비스의 상태를 모니터링하는 오픈소스 모니터링 시스템이다.
현재는 Kubernetes 다음으로 인기있는 CNCF 프로젝트라고 볼 수 있다.
Prometheus는 특히 메트릭 수집과 알람에 특화되어있다.
Prometheus 메트릭 수집 방법
메트릭 수집의 경우 HTTP 엔드 포인트를 통한 pull 방식으로 이루어지고 있다.
Pull 방식
- 주기적으로 타겟 서버를 찾아가서 메트릭을 긁어옴 (scraping)
- ex) 매 15초마다
/metrics엔드포인트 호출
- ex) 매 15초마다
Push 방식
- 각 서버/애플리케이션이 직접 모니터링 시스템으로 메트릭 전송
- 애플리케이션이 주기적으로 메트릭을 모니터링 시스템의 api로 전송
Pull vs Push 방식 비교
| Pull (Prometheus) | Push (기존 방식) |
|---|---|
| 앱이 모니터링 서버 주소 몰라도 됨 | 앱이 모니터링 서버 주소 알아야 함 |
| 네트워크 문제 시 바로 감지 | 데이터가 안 오면 이유를 모름 |
| 수집 주기를 중앙에서 관리 | 각 앱마다 따로 설정 |
| 방화벽 설정이 복잡할 수 있음 | 방화벽 설정 간단 |
Prometheus 핵심 개념
이렇게 수집한 데이터는 시계열 데이터로 저장한다.
시계열 데이터란 모든 데이터를 시간과 함께 저장하는 것이다.
시간별로 데이터가 어떻게 변했는지 기록하는 것처럼 시간별로 데이터가 저장된다.
"시간" + "벨류"
대신 과거 데이터를 수정하지 않고 계속 쌓기만 한다. 따라서 시간 기반 계산에 최적화되어있다.예시
웹브라우저로 http://.../metrics 접속하면 보이는 내용
http_requests_total{method="GET", endpoint="/login"} 1234
http_requests_total{method="POST", endpoint="/signup"} 567
memory_usage_bytes 1073741824
cpu_usage_percent 45.2- 메트릭이름{라벨="값"} 현재값
- 타임스탬프는 보이지 않음 (Prometheus가 수집 시점에 자동 기록)
- 브라우저로 /metrics 접속하면 현재 시점의 값만 보임
- Prometheus가 주기적으로 이 엔드포인트르 스크레핑해서 타임스탬프랑 같이 저장
Prometheus 메트릭 타입
- Counter
- 누적값, 증가만 가능
- 예:
http_requests_total,error_count_total
- Gauge
- 증가 / 감소 가능한 값
- 예:
cpu_usage_percent,memory_usage_bytes
- Histogram
- 구간별 분포 측정
- 예:
http_request_duration_seconds
- Summary
- 백분위수 계산
- 예:
response_time_percentile
Prometheus 라벨
라벨을 통해서 더 세밀하게 구분할 수 있다. key-value로 이루어져 있으며, 영문자로 시작해야한다.
여기서 __로 시작하는 이름은 prometheus에서 내부적으로 사용하는 예약어라 사용하면 안된다.
라벨 활용 예시
좋은 라벨 설계
http_requests_total{
method="POST", # 값이 제한적 (GET, POST, PUT, DELETE)
endpoint="/api/users", # 엔드포인트 수는 한정적
status="200", # HTTP 상태 코드 (200, 404, 500 등)
env="production" # 환경 (dev, staging, production)
}나쁜 라벨 설계
http_requests_total{
user_id="user_123456", # 수백만 개의 고유값 -> 메모리 폭발
timestamp="2024-01-01" # 시간은 이미 자동 저장됨
}주의사항: 라벨이 변경되면 변경된 라벨에 맞춰 새로운 시계열이 생성된다.
라벨 값이 바뀌면 다른 시계열로 취급되어 문제를 발생시킬 수 있다.
이렇게되면 시계열 데이터 수가 매우 증가할 수 있기 때문에 메모리 성능에 문제가 생길 수 있어 정말 필요한 부분에만 라벨을 처리하는게 중요하다.
저장된 데이터 찾기
Prometheus는 데이터를 저장하기 위해서 Chunk(청크)와 WAL(Write-Ahead-Log)를 사용한다.
Chunk
청크는 여러개의 샘플을 하나의 덩어리로 묶은 데이터 구조이다.
만약 1시간 동안의 CPU 사용률 데이터의 경우 아래와 같다.
[10:00:00, 45%] [10:00:15, 47%] [10:00:30, 52%] ...하나의 청크로 압축되어 디스크에 저장된다.
이렇게 압축된 청크 덕분에 Prometheus는 많은 데이터를 효율적으로 저장하고 빠르게 조회할 수 있다.
WAL (Write-Ahead-Log)
WAL은 데이터 안정성을 보장하는 로그 파일이다. 샘플이 수집되게되면 가장 먼저 WAL에 저장된다.
수집 → WAL에 즉시 기록 → 메모리 저장 → 청크로 압축 → 디스크 저장WAL의 경우 만약 장애가 발생하게 되면 복구를 도와주는 중요한 역할을 하게 된다.
만약, Prometheus가 비정상적으로 종료되었을 경우에, WAL 파일을 읽어서 데이터를 복구할 수 있게 된다.
- 메트릭 수집: Prometheus는 타겟으로부터 메트릭을 수집하고, 이를 시계열 데이터로 변환한다.
- WAL 기록: 수집된 샘플과 해당 시계열 정보는 먼저 WAL에 기록되어 장애 발생 시 복구 가능하게 한다.
- 메모리 저장: 수집된 메트릭은 Prometheus의 in-memory TSDB 구조에 시계열(series)과 샘플(sample) 형태로 저장된다.
- 청크 압축: 메모리 내의 샘플들은 chunk로 압축되어 저장된다.
- 디스크 저장: 일정 시간이 경과하거나 조건이 충족되면 디스크에 block 형태로 flush 된다. 이후 해당 시점까지의 WAL segment는 삭제된다.
- Compaction: 디스크에 저장된 block들은 주기적으로 compaction 과정을 거치며, 이 과정에서 저장
공간을 최적화한다.
재시작시 복구 과정
만약 문제가 있어 Prometheus가 재시작이 된다면 다음과 같은 과정을 거치게 된다.
- WAL 파일을 읽어 메모리에만 존재하던 데이터를 복구한다
- 시계열과 샘플 정보를 다시 메모리에 로드한다
- 데이터 연속성을 유지한다.
데이터 저장 위치와 보존 기간 설정 예시
# prometheus.yml
storage:
tsdb:
path: /var/lib/prometheus # 데이터 저장 경로
retention.time: 15d # 15일간 보관
retention.size: 10GB # 최대 10GB까지 저장PromQL (Prometheus Query Language)
Prometheus는 자체 쿼리인 PromQL을 제공하며, 다양한 방식으로 메트릭을 집계하고 필터링한다.
PromQL 예시
# 5분간 초당 요청 수 (QPS)
rate(http_requests_total[5m])
# 엔드포인트별 에러율
sum(rate(http_requests_total{status=~"5.."}[5m])) by (endpoint)
/
sum(rate(http_requests_total[5m])) by (endpoint) * 100
# 메모리 사용률 80% 넘는 서버 찾기
(memory_usage_bytes / memory_total_bytes) > 0.8
# 특정 팀의 프로덕션 서버만 모니터링
cpu_usage{team="backend", env="production"}
알람 설정
Prometheus는 알람 기능도 제공하고 있기 때문에 임계값을 초과하면 알림을 발송해서 문제를 알고 대응할 수 있다.
알람 설정 예시
groups:
- name: example
rules:
- alert: HighErrorRate
expr: rate(http_requests_total{status=~"5.."}[5m]) > 0.05
for: 5m
annotations:
summary: "{{ $labels.endpoint }} 에러율 5% 초과"
description: "현재 에러율: {{ $value | humanizePercentage }}"
- alert: HighMemoryUsage
expr: memory_usage_bytes / memory_total_bytes > 0.9
for: 10m
annotations:
summary: "메모리 사용률 90% 초과"모니터링
PromQL의 쿼리 결과들은 보통 다른 모니터링 도구로 그래프와 대시보드 형태로 표현해 확인할 수 있다.
나의 경우 Grafana를 통해서 초기 대시보드 화면을 구현한적 있다.
직접 만든 화면은 회사 데이터가 있으므로 Grafana에서 가져온 것으로 대체한다.
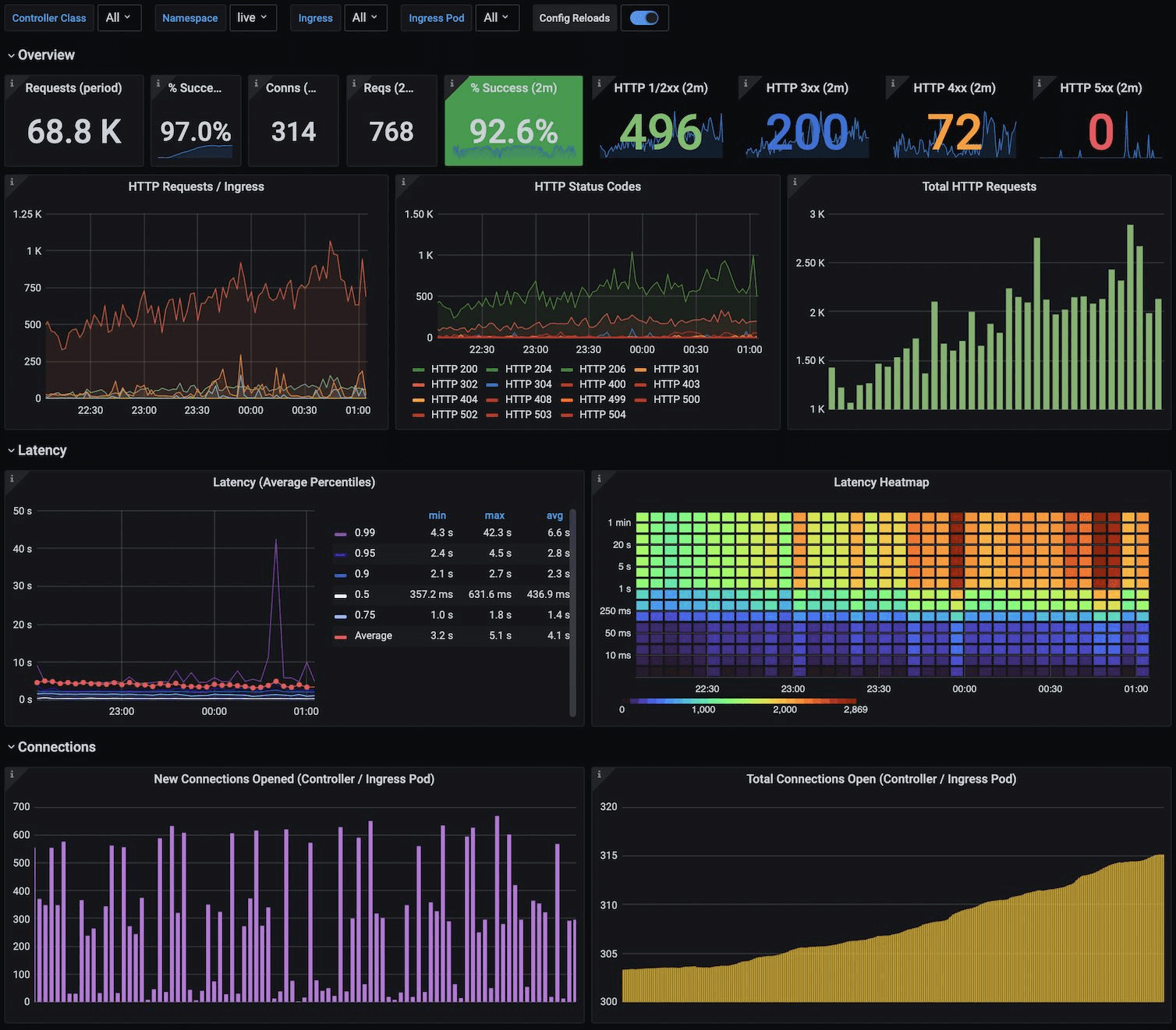
Prometheus는 데이터 수집과 저장에 특화되어있고, 시각화는 주로 Grafana를 연동해서 사용하는 추세이다.
- Prometheus가 메트릭 수집/저장
- Grafana가 Prometheus를 데이터소스로 연결함
- 대시보드에서 PromQL로 쿼리 작성
- 실시간 그래프와 알림 설정 가능
실제 Grafana Dashboard Template이 있어서 원하는 템플릿을 직접 가져와서 사용해도 된다.
나의 경우 데이터가 보이지 않거나 다른 데이터를 보여줘야할때 Panel을 추가해서 직접 PromQL로 데이터를 보여줬다
* Grafana Dashboard Template: https://grafana.com/grafana/dashboards/
Prometheus의 한계
Prometheus의 경우 분명 메트릭을 수집하는데 특화되어있다.
그러나 실제 운영에 있어서 모니터링앱을 구성할때는 메트릭 데이터만으로는 모니터링 앱을 만드는데 한계가 있다.
로그나 트레이싱을 지원하지 않기 때문에 완벽한 모니터링 앱을 만들고자한다면,
로그나 트레이싱(예., Jaeger) 데이터를 수집하는 다른 것들이 필요하다.
